
SGD 随机梯度下降
Keras 中包含了各式优化器供我们使用,但通常我会倾向于使用 SGD 验证模型能否快速收敛,然后调整不同的学习速率看看模型最后的性能,然后再尝试使用其他优化器。
Keras 中文文档中对 SGD 的描述如下:
keras.optimizers.SGD(lr=0.01, momentum=0.0, decay=0.0, nesterov=False)
随机梯度下降法,支持动量参数,支持学习衰减率,支持Nesterov动量
参数:
lr:大或等于0的浮点数,学习率
momentum:大或等于0的浮点数,动量参数
decay:大或等于0的浮点数,每次更新后的学习率衰减值
nesterov:布尔值,确定是否使用Nesterov动量
参数设置
Time-Based Learning Rate Schedule
Keras 已经内置了一个基于时间的学习速率调整表,并通过上述参数中的 decay 来实现,学习速率的调整公式如下:
LearningRate = LearningRate * 1/(1 + decay * epoch)
当我们初始化参数为:
LearningRate = 0.1
decay = 0.001
大致变化曲线如下(非实际曲线,仅示意):
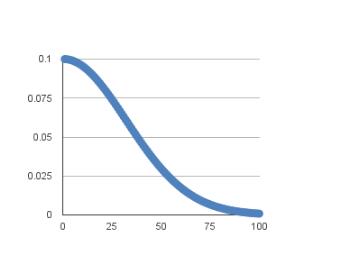
当然,方便起见,我们可以将优化器设置如下,使其学习速率随着训练轮次变化:
sgd = SGD(lr=learning_rate, decay=learning_rate/nb_epoch, momentum=0.9, nesterov=True)
Drop-Based Learning Rate Schedule
另外一种学习速率的调整方法思路是保持一个恒定学习速率一段时间后立即降低,是一种突变的方式。通常整个变化趋势为指数形式。
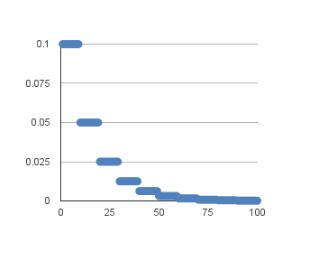
对应的学习速率变化公式如下:
LearningRate = InitialLearningRate * DropRate^floor(Epoch / EpochDrop)
实现需要使用 Keras 中的 LearningRateScheduler 模块:
from keras.callbacks import LearningRateScheduler # learning rate schedule def step_decay(epoch): initial_lrate = 0.1 drop = 0.5 epochs_drop = 10.0 lrate = initial_lrate * math.pow(drop, math.floor((1+epoch)/epochs_drop)) return lrate lrate = LearningRateScheduler(step_decay) # Compile model sgd = SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False) model.compile(loss=..., optimizer=sgd, metrics=['accuracy']) # Fit the model model.fit(X, Y, ..., callbacks=[lrate])
补充知识:keras中的BGD和SGD
关于BGD和SGD
首先BGD为批梯度下降,即所有样本计算完毕后才进行梯度更新;而SGD为随机梯度下降,随机计算一次样本就进行梯度下降,所以速度快很多但容易陷入局部最优值。
折中的办法是采用小批的梯度下降,即把数据分成若干个批次,一批来进行一次梯度下降,减少随机性,计算量也不是很大。 mini-batch
keras中的batch_size就是小批梯度下降。
以上这篇Keras SGD 随机梯度下降优化器参数设置方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/189108/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)