
数据库读写分离对于大型系统或者访问量很高的互联网应用来说,是必不可少的一个重要功能。对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个读节点的配置。而一般的读写分离中间件,例如Mycat的读写分离和自动切换机制,需要mysql的主从复制机制配合。
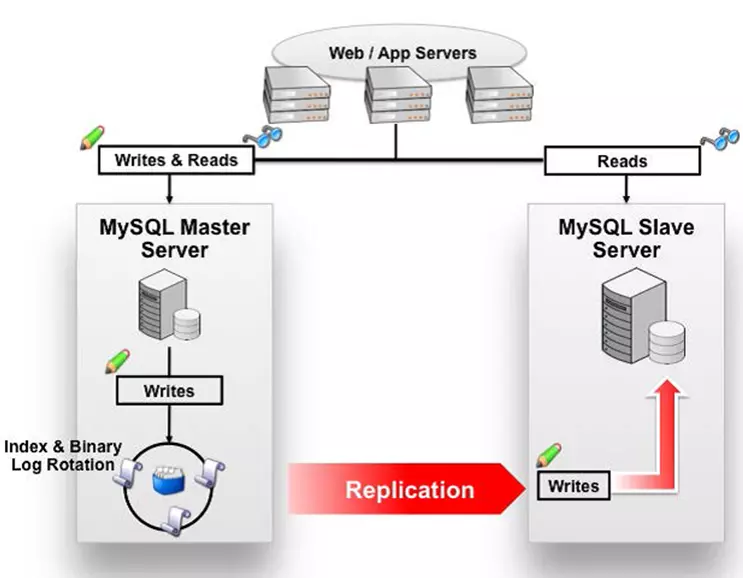
主从配置需要注意的地方
1、主DB server和从DB server数据库的版本一致
2、主DB server和从DB server数据库数据名称一致
3、主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一MySQL主服务器配置
第一步:修改my.conf文件:
在[mysqld]段下添加:
binlog-ignore-db=mysql #启用二进制日志 log-bin=mysql-bin //二进制日志的格式,有三种:statement/row/mixed binlog_format=row #主服务器唯一ID,一般取IP最后一段 server-id=82
第二步:重启mysql服务
service mysql restart
第三步:建立帐户并授权slave
mysql>GRANT FILE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepw';
mysql>GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'slave'@'%' identified by 'slavepw';
一般不用root帐号,“%”表示所有客户端都可能连,只要帐号,密码正确,此处可用具体客户端IP代替,如192.168.145.226,加强安全。
刷新权限
mysql> FLUSH PRIVILEGES;
第四步:查询master的状态
mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 881 | | mysql | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
MySQL从服务器配置
第一步:修改my.conf文件
[mysqld]#从服务器唯一ID,一般取IP最后一段server-id=83
第二步:配置从服务器
mysql>change master to master_host='192.168.11.82',master_port=3306,master_user='slave',master_password='slavepw',master_log_file='mysql-bin.000001',master_log_pos=881;
注意语句中间不要断开,master_port为mysql服务器端口号(无引号),master_user为执行同步操作的数据库账户,“881”无单引号(此处的881就是show master status 中看到的position的值,这里的mysql-bin.000001就是file对应的值)。
第三步:启动从服务器复制功能
mysql>start slave;
第四步:检查从服务器复制功能状态:
mysql> show slave status;
Slave_IO_Running: Yes //此状态必须YES
Slave_SQL_Running: Yes //此状态必须YES
注:Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
进行验证
在主节点上创建表、插入数据,发现从节点也创建表并插入数据。
MySQL 主从复制原理的是啥?
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
所以 MySQL 实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题;一个是并行复制,用来解决主从同步延时问题。
这个所谓半同步复制,也叫semi-sync复制,指的就是主库写入 binlog 日志之后,就会将强制此时立即将数据同步到从库,从库将日志写入自己本地的 relay log 之后,接着会返回一个 ack 给主库,主库接收到至少一个从库的 ack 之后才会认为写操作完成了。
所谓并行复制,指的是从库开启多个线程,并行读取 relay log 中不同库的日志,然后并行重放不同库的日志,这是库级别的并行。
MySQL 主从同步延时问题
以前线上确实处理过因为主从同步延时问题而导致的线上的 bug,属于小型的生产事故。
是这个么场景。有个同学是这样写代码逻辑的。先插入一条数据,再把它查出来,然后更新这条数据。在生产环境高峰期,写并发达到了 2000/s,这个时候,主从复制延时大概是在小几十毫秒。线上会发现,每天总有那么一些数据,我们期望更新一些重要的数据状态,但在高峰期时候却没更新。用户跟客服反馈,而客服就会反馈给我们。
我们通过 MySQL 命令:
show status
查看Seconds_Behind_Master,可以看到从库复制主库的数据落后了几 ms。
一般来说,如果主从延迟较为严重,有以下解决方案:
分库,将一个主库拆分为多个主库,每个主库的写并发就减少了几倍,此时主从延迟可以忽略不计。打开 MySQL 支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了 2000/s,并行复制还是没意义。重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到。如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你要是这么搞,读写分离的意义就丧失了。开启并行复制
开启多线程复制,默认关键的参数有两个:
mysql> show variables like 'slave_parallel_%'; +------------------------+----------+ | Variable_name | Value | +------------------------+----------+ | slave_parallel_type | DATABASE | | slave_parallel_workers | 0 | +------------------------+----------+ 2 rows in set (0.00 sec)
slave-parallel-type 默认值为database
slave-parallel-workers 默认值为0
开启:
mysql> stop slave sql_thread; Query OK, 0 rows affected (0.05 sec) mysql> set global slave_parallel_type='LOGICAL_CLOCK'; Query OK, 0 rows affected (0.00 sec) mysql> set global slave_parallel_workers=4; Query OK, 0 rows affected (0.00 sec) mysql> start slave sql_thread; Query OK, 0 rows affected (0.07 sec)
参考资料:
https://www.jianshu.com/p/3932551e0221
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/200867/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)