
一、Beautiful Soup库简介
BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据。和 lxml 库一样。
lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低。
BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支持 lxml 解析器。
二、Beautiful Soup库安装
目前,Beautiful Soup 的最新版本是 4.x 版本,之前的版本已经停止开发,这里推荐使用 pip 来安装,安装命令如下:
pip install beautifulsoup4
查看 Beautiful Soup 安装是否成功
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','html.parser')
print(soup.p.string)
注意:
□ 这里虽然安装的是 beautifulsoup4 这个包,但是引入的时候却是 bs4,因为这个包源 代码本身的库文件名称就是bs4,所以安装完成后,这个库文件就被移入到本机 Python3 的 lib 库里,识别到的库文件就叫作 bs4。
□ 因此,包本身的名称和我们使用时导入包名称并不一定是一致的。
三、Beautiful Soup 库解析器
Beautiful Soup 在解析时实际上依赖解析器,它除了支持 Python 标准库中的 HTML 解析器外,还支持一些第三方解析器(比如 lxml)。下表列出了 Beautiful Soup 支持的解析器。
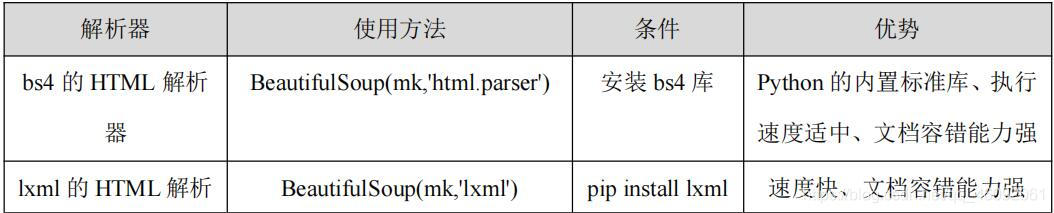

初始化 BeautifulSoup 使用 lxml,把第二个参数改为 lxml
from bs4 import BeautifulSoup
bs = BeautifulSoup('<p>Python</p>','lxml')
print(bs.p.string)
四、Beautiful Soup库基本用法

获取 title 节点,查看它的类型
from bs4 import BeautifulSoup
html = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify())
print(soup.title.string)
执行结果如下所示:
The Dormouse's story
- 上述示例首先声明变量 html,它是一个 HTML 字符串。接着将它当作第一个参数传给 BeautifulSoup 对象,该对象的第二个参数为解析器的类型(这里使用 lxml),此时就完成了 BeaufulSoup 对象的初始化。
- 接着调用 soup 的各个方法和属性解析这串 HTML 代码了。
- 调用 prettify()方法。可以把要解析的字符串以标准的缩进格式输出。这里需要注意的是, 输出结果里面包含 body 和 html 节点,也就是说对于不标准的 HTML 字符串 BeautifulSoup, 可以自动更正格式。
- 调用 soup.title.string,输出 HTML 中 title 节点的文本内容。所以,soup.title 可以选出 HTML 中的 title 节点,再调用 string 属性就可以得到里面的文本了。
选择元素
# 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 获取head标签 print(soup.head) # 获取p标签 print(soup.p)
运行结果:
<head><title>The Dormouse's story</title></head>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
- 从上述示例运行结果可以看到,获取 head 节点的结果是节点加其内部的所有内容。
- 最后,选择了 p 节点。不过这次情况比较特殊,我们发现结果是第一个 p 节点的内容,后面的几个 p 节点并没有选到。也就是说,当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略。
调用 name 属性获取节点的名称
# 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 调用 name 属性获取节点的名称 print(soup.title.name)
运行结果:
title
调用 attrs 获取所有属性
# 调用 attrs 获取所有属性 print(soup.p.attrs) print(soup.p.attrs['name'])
运行结果:
{'class': ['title'], 'name': 'dromouse'}
dromouse
从上述运行结果可以看到,attrs 的返回结果是字典形式,它把选择节点的所有属性和属性值组合成一个字典。
如果要获取 name 属性,就相当于从字典中获取某个键值,只需要用中括号加属性名就可以了。例如,要获取 name 属性,就可以通过 attrs[‘name'] 来得到。
简单获取属性的方式
print(soup.p['name']) print(soup.p['class'])
这里需要注意的是,获取属性有的返回结果是字符串,有的返回结果是字符串组成的列表。
比如,name 属性的值是唯一的,返回的结果就是单个字符串。而对于 class,一个节点元素可能有多个 class,所以返回的是列表。
调用 string 属性获取节点元素包含的文本内容
print('调用 string 属性获取节点元素包含的文本内容')
print(soup.p.string)
嵌套选择
print('嵌套选择')
print(soup.head.title)
# 获取title的类型
print(type(soup.head.title))
# 获取标签内容
print(soup.head.title.string)
运行结果:
<title>The Dormouse's story</title>
<class 'bs4.element.Tag'>
The Dormouse's story
从上述示例运行结果可以看到,调用 head 之后再次调用 title 可以选择 title 节点元素。 输出了它的类型可以看到,它仍然是 bs4.element.Tag 类型。也就是说,我们在 Tag 类型的基础上再次选择得到的依然还是 Tag 类型,每次返回的结果都相同。
调用 children 属性,获取它的直接子节点
from bs4 import BeautifulSoup
html = '''
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story"> Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well.
</p>
<p class="story">...</p>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取孩子结点
print(soup.p.children)
# 遍历孩子结点
# 将列表中元素与下标枚举为元组
# 获取p标签下的孩子标签
for i, child in enumerate(soup.p.children):
print(i, child)
执行结果:
<list_iterator object at 0x0CACF448>
0 Once upon a time there were three little sisters; and their names were
1 <a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
2
3 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
4 and
5 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
6 and they lived at the bottom of a well.
从上述示例运行结果可以看到,调用 children 属性,返回结果是生成器类型。用 for 循环输出相应的内容。
调用 parent 属性,获取某个节点元素的父节点
from bs4 import BeautifulSoup html = ''' <html> <head> <title>The Dormouse's story</title> </head> <body><p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1"> <span>Elsie</span> </a> </p> <p class="story">...</p> ''' # 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 获取父结点 print(soup.a.parent)
运行结果:
<p class="story"> Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
从上述示例运行结果可以看到,我们选择的是第一个 a 节点的父节点元素,它的父节点 是 p 节点,输出结果便是 p 节点及其内部的内容。 需要注意的是,这里输出的仅仅是 a 节点的直接父节点,而没有再向外寻找父节点的祖 先节点。如果想获取所有的祖先节点,可以调用 parents 属性。
调用 parents 属性,获取某个节点元素的祖先节点
from bs4 import BeautifulSoup html = ''' <html> <body><p class="story"> <a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1"> <span>Elsie</span> </a> </p> ''' # 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 获取父结点 print(type(soup.a.parents)) # 获取类型 print(list(enumerate(soup.a.parents)))
运行结果:
[(0, <p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>), (1, <body><p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
</body>), (2, <html>
<body><p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
</body></html>), (3, <html>
<body><p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
</body></html>)]
调用 next_sibling 和 previous_sibling 分别获取节点的下一个和上一个兄弟元素
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<p class="story"> Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1">
<span>Elsie</span>
</a> Hello
<a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取下一个结点的属性
print('Next Sibling', soup.a.next_sibling)
print('Previous Sibling', soup.a.previous_sibling)
运行结果:
Next Sibling Hello
Previous Sibling Once upon a time there were three little sisters; and their names were
五、方法选择器
上面所讲的选择方法都是通过属性来选择的,这种方法非常快,但是如果进行比较复杂的选择的话,它就比较烦琐,不够灵活了。
Beautiful Soup 还提供了一些查询方法,例如:find_all()和 find()等。
find_all 是查询所有符合条件的元素。给它传入一些属性或文本,就可以得到符合条件的元素,它的功能十分强大。
语法格式如下:
find_all(name , attrs , recursive , text , **kwargs)
find_all 方法传入 name 参数,根据节点名来查询元素
from bs4 import BeautifulSoup
html = '''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
for li in ul.find_all(name='li'):
print(li.string)
结果如下:
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
Foo
Bar
Jay
[<li class="element">Foo</li>, <li class="element">Bar</li>]
Foo
Bar
从上述示例可以看到,调用 find_all()方法,name 参数值为 ul。返回结果是查询到的所有 ul 节点列表类型,长度为 2,每个元素依然都是 bs4.element.Tag 类型。因为都是 Tag 类型, 所以依然可以进行嵌套查询。再继续查询其内部的 li 节点,返回结果是 li 节点列表类型, 遍历列表中的每个 li,获取它的文本。
find_all 方法传入 attrs 参数,根据属性来查询
from bs4 import BeautifulSoup
html = '''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(attrs={'id': 'list-1'}))
print(soup.find_all(attrs={'name': 'elements'}))
结果如下:
[<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
[<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
从上述示例可以看到,传入 attrs 参数,参数的类型是字典类型。比如,要查询 id 为 list-1 的节点,可以传入 attrs={‘id': ‘list-1'}的查询条件,得到的结果是列表形式,包含的内容就是符合 id 为 list-1 的所有节点。符合条件的元素个数是 1,长度为 1 的列表。
对于一些常用的属性,比如 id 和 class 等,可以不用 attrs 来传递。比如,要查询 id 为 list-1 的节点 ,可以直接传入 id 这个参数。
示例如下:
print(soup.find_all(id='list-1')) print(soup.find_all(class_='element'))
上述示例直接传入 id='list-1',就可以查询 id 为 list-1 的节点元素了。而对于 class 来 说,由于 class 在 Python 里是一个关键字,所以后面需要加一个下划线,即 class_='element', 返回的结果依然还是 Tag 组成的列表。
find_all 方法根据文本来查询
find_all 方法传入 text 参数可用来匹配节点的文本,传入的形式可以是字符串,可以是正则表达式对象。
from bs4 import BeautifulSoup
import re
html = '''
<div class="panel">
<div class="panel-body">
<a>Hello, this is a link</a>
<a>Hello, this is a link, too</a>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
运行结果
['Hello, this is a link', 'Hello, this is a link, too']
上述示例有两个 a 节点,其内部包含文本信息。这里在 find_all()方法中传入 text 参数, 该参数为正则表达式对象,结果返回所有匹配正则表达式的节点文本组成的列表。
除了 find_all()方法,还有 find()方法,不过后者返回的是单个元素,也就是第一个匹配的元素,而前者返回的是所有匹配的元素组成的列表。
find 方法查询第一个匹配的元素
from bs4 import BeautifulSoup
import re
html = '''
<<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取标签名为ul的标签体内容
print(soup.find(name='ul'))
# 获取返回结果的列表
print(type(soup.find(name='ul')))
# 查找标签中class是'list'
print(soup.find(class_='list'))
结果如下
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<class 'bs4.element.Tag'>
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
上述示例使用 find 方法返回结果不再是列表形式,而是第一个匹配的节点元素,类型依然是 Tag 类型。
六、CSS 选择器
Beautiful Soup 还提供了另外一种选择器,那就是 CSS 选择器。使用 CSS 选择器时,只 需要调用 select()方法,传入相应的 CSS 选择器即可。
CSS相关知识:
#element: id选择器.
element:类选择器
tag tag:派生选择器
通过依据元素在其位置的上下文关系来定义样式,你可以使标记更加简洁。
from bs4 import BeautifulSoup
import re
html = '''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取class=panel标签下panel_heading,类选择器
print(soup.select('.panel .panel-heading'))
# 派生选择器
print(soup.select('ul li'))
# id选择器+类选择器
lis = soup.select('#list-2 .element')
for l in lis:
print('GET TEXT', l.get_text())
print('String:', l.string)
结果如下
[<div class="panel-heading">
<h4>Hello</h4>
</div>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
GET TEXT Foo
String: Foo
GET TEXT Bar
String: Bar
上述示例,用了 3 次 CSS 选择器,返回的结果均是符合 CSS 选择器的节点组成的列表。 例如,select(‘ul li')则是选择所有 ul 节点下面的所有 li 节点,结果便是所有的 li 节点组成的列表。要获取文本,当然也可以用前面所讲的 string 属性。此外,还有一个方法,那就是 get_text()。
到此这篇关于Python爬虫进阶之Beautiful Soup库详解的文章就介绍到这了,更多相关Python Beautiful Soup库详解内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/211048/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)