
一、背景
默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢。因为需要一个url请求的完成,才能让下一个url继续访问。一种很自然的想法就是用异步机制来提高爬虫速度。通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时)。
import time
#串形
def getPage(url):
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
urls = ['url1','url2','url3','url4','url5']
beginTime = time.time()#开始计时
for url in urls:
getPage(url)
endTime= time.time()#结束计时
print("完成时间%d"%(endTime - beginTime))
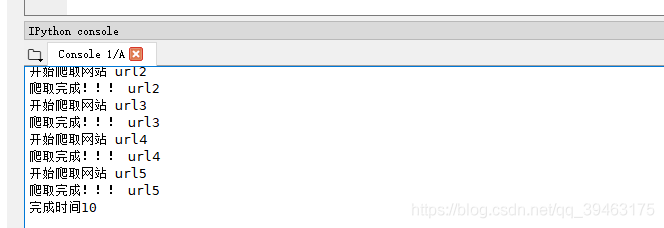
下面通过模拟爬取网站来完成对多线程,多进程,协程的理解。
二、多线程实现
import time
#使用线程池对象
from multiprocessing.dummy import Pool
def getPage(url):
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
urls = ['url1','url2','url3','url4','url5']
beginTime = time.time()#开始计时
#准备开启5个线程,并示例化对象
pool = Pool(5)
pool.map(getPage, urls)#urls是可迭代对象,里面每个参数都会给getPage方法处理
endTime= time.time()#结束计时
print("完成时间%d"%(endTime - beginTime))
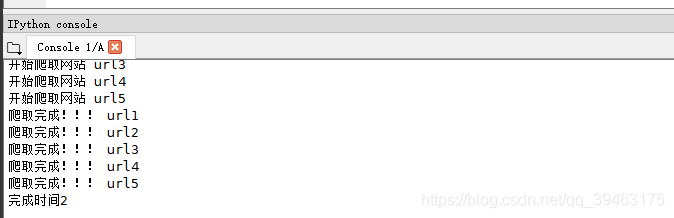
完成时间只需要2s!!!!!!!!
线程池使用原则:适合处理耗时并且阻塞的操作
三、协程实现
单线程+异步协程!!!!!!!!!!强烈推荐,目前流行的方式。
相关概念:

#%%
import time
#使用协程
import asyncio
async def getPage(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
#async修饰的函数返回的对象
c = getPage(11)
#创建事件对象
loop_event = asyncio.get_event_loop()
#注册并启动looP
loop_event.run_until_complete(c)
#task对象使用,封装协程对象c
'''
loop_event = asyncio.get_event_loop()
task = loop_event.create_task(c)
loop_event.run_until_complete(task)
'''
#Future对象使用,封装协程对象c 用法和task差不多
'''
loop_event = asyncio.get_event_loop()
task = asyncio.ensure_future(c)
loop_event.run_until_complete(task)
'''
#绑定回调使用
async def getPage2(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
return url
#async修饰的函数返回的对象
c2 = getPage2(2)
def callback_func(task):
print(task.result()) #task.result()返回任务对象中封装的协程对象对应函数的返回值
#绑定回调
loop_event = asyncio.get_event_loop()
task = asyncio.ensure_future(c2)
task.add_done_callback(callback_func) #真正绑定,
loop_event.run_until_complete(task)
输出:

四、多任务协程实现
import time
#使用多任务协程
import asyncio
urls = ['url1','url2','url3','url4','url5']
async def getPage(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
#在异步协程中如果出现同步模块相关的代码,那么无法实现异步
#time.sleep(2)#阻塞
await asyncio.sleep(2)#遇到阻塞操作必须手动挂起
print("爬取完成!!!",url)
return url
beginTime = time.time()
#任务列表,有多个任务
tasks = []
for url in urls:
c = getPage(url)
task = asyncio.ensure_future(c)#创建任务对象
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))#不能直接放task,需要封装进入asyncio,wait()方法中
endTime = time.time()
print("完成时间%d"%(endTime - beginTime))

此时不能用time.sleep(2),用了还是10秒
对于真正爬取过程中,如在getPage()方法中真正爬取数据时,即requests.get(url) ,它是基于同步方式实现。应该使用异步网络请求模块aiohttp
参考下面代码:
async def getPage(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
#在异步协程中如果出现同步模块相关的代码,那么无法实现异步
#requests.get(url)#阻塞
async with aiohttp.ClintSession() as session:
async with await session.get(url) as response: #手动挂起
page_text = await response.text() #.text()返回字符串,read()返回二进制数据,注意不是content
print("爬取完成!!!",url)
return page_text

到此这篇关于Python异步爬虫实现原理与知识总结的文章就介绍到这了,更多相关Python异步爬虫内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/212084/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)