
1、Cookie的实现原理?
参考文章:
Cookie 工作原理如图所示:
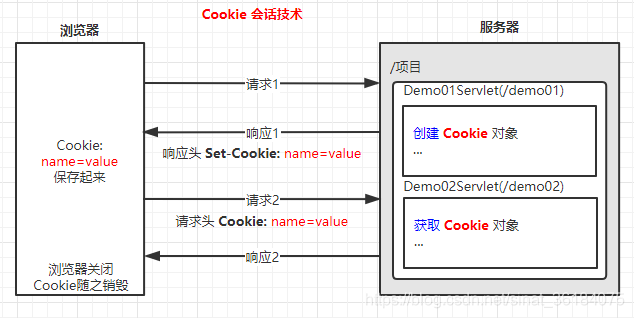
执行流程:
- 浏览器向服务器发送请求,服务器需要创建 cookie,服务器会通过响应携带 cookie,在产生响应时会产生 Set-Cookie 响应头,从而将 cookie 信息传递给了浏览器;
- 当浏览器再次向服务器发送请求时,会产生 cookie 请求头,将之前服务器的 cookie 信息再次发送给了服务器,然后服务器根据 cookie 信息跟踪客户端状态。
Cookie 创建:
// 用响应创建Cookie,等价于 response.addHeader("set-cookie", "name=value");
Cookie cookie = new Cookie(String name, String value); // Cookie: name=value
cookie.setMaxAge(seconds); // 设置Cookie的生命周期
cookie.setPath("/"); // 设置Cookie的共享范围
response.addCookie(cookie); // 添加1个Cookie
Cookie 获取:
// 用请求获取Cookie Cookie[] cookies = request.getCookies(); // 获取Cookies返回数组 // 需遍历 cookie.getName(); // 获取键 cookie.getValue(); // 获取值
Cookie 修改:
// 修改Cookie cookie.setValue(String name);
2、TCP断开连接时,通信双方的状态变化?
参考文章:
TCP的三次握手与四次挥手
这道题是我在字节跳动一面时候遇到的问题,我以为会先从三次握手、四次挥手开始问,没想到面试官不按常理出牌,直接问我 TCP 通信双方的状态变化。
这道题的答案,直接看上面提供的参考文章,讲的非常透彻,也非常容易理解,只需要静下心看完它!
3、GC垃圾回收时,什么情况下会Stop The World?
在每次 FUll GC 的时候都会 Stop The World (STW),即,挂起其他所有除了 GC 之外的线程,只让 GC 垃圾回收线程工作,Young GC 不会触发 Stop The World。
- CMS 垃圾收集器:
- 新生代:不会触发 STW。
- 老年代:会触发 2 次 STW,初始标记 和 重新标记 会触发。当年老代达到特定的占用比例时,CMS 开始执行。
- G1 垃圾收集器:
- 新生代:新生对象会被疏散(复制、移动)到一个或多个 Survivor 幸存区域。如果对象达到晋升总阈值,对象会晋升到年老代区域,这时候会触发一次 STW 。
- 老年代:G1 老年代垃圾回收和 CMS 一样,会触发 2 次 STW,初始标记 、重新标记、清理、复制 时,会触发 STW。
4、堆和栈的区别?
堆:
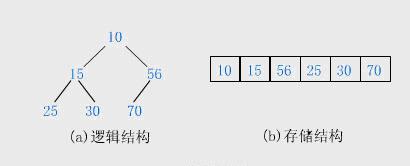
堆是一种常用的树形结构,是一种特殊的完全二叉树,当且仅当满足所有节点的值总是不大于或不小于其父节点的值的完全二叉树被称之为堆。堆的这一特性称之为堆序性。因此,在一个堆中,根节点是最大(或最小)节点。如果根节点最小,称之为小顶堆(或小根堆),如果根节点最大,称之为大顶堆(或大根堆)。堆的左右孩子没有大小的顺序。下面是一个小顶堆示例:

堆的存储一般都用数组来存储堆,i 节点的父节点下标就为(i?1)/2,它的左右子节点下标分别为2 ∗ i + 1 和 2 * i - 1,如第 0 个节点左右子节点下标分别为 1 和 2。
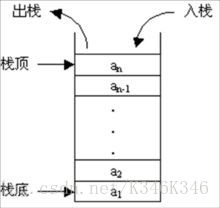
栈:
栈是一种线性表,只仅允许在表的一端进行插入和删除操作,这一端被称为栈顶(Top),相对地,把另一端称为栈底(Bottom)。把新元素放到栈顶元素的上面,使之成为新的栈顶元素称作进栈、入栈或压栈(Push);把栈顶元素删除,使其相邻的元素成为新的栈顶元素称作出栈或退栈(Pop)。
文章参考:堆与栈的区别
5、线程调度的方式?
- 分时调度:所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间。
- '抢占式调度:优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
线程的调度,取决于支持的是内核级线程还是用户级线程?
- 对于用户级线程,内核不知道线程的存在,就给了进程很大的自主权。内核只是调度进程,由进程去选择调度哪个线程来运行。
- 对于内核级线程,线程的调度就交给了系统完成。
6、Linux 下如何查看文件前几行和后几行的命令?
这个是近期面试字节一面的时候,面试官问的问题:
# /etc/profile 的前10行内容,应该是: head -n 10 /etc/profile # 查看/etc/profile 的最后5行内容,应该是: tail -n 5 /etc/profile # 将内容输出到/home/test文件中 head -n 10 /etc/profile >> /home/test tail -n 5 /etc/profile >> /home/test
7、TIME_WAIT为什么要等待2MSL,TIME_WAIT是客户端状态还是服务端状态?
简短概括:① 防止服务没有收到客户端发送的最后一个 ACK,则会重发 FIN 请求,② 让本次请求之前发送的请求都过期。
详细介绍如下:
- 第一,保证客户端发送的最后一个 ACK 报文能够到达服务器,由于这个 ACK 报文可能丢失,站在服务器的角度看来,我已经发送了 FIN+ACK 报文请求断开了,客户端还没有给我回应,应该是我发送的请求断开报文它没有收到,于是服务器又会重新发送一次而客户端就能在这个 2MSL 时间段内收到这个重传的报文,接着给出回应报文,并且会重启 2MSL 计时器。
- 第二,防止 “已经失效的连接请求报文段” 出现在本次请求中。客户端发送完最后一个确认报文后,在这个 2MSL 时间中,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样新的连接中不会出现旧连接的请求报文。
8、为什么建立连接是三次握手,关闭连接确是四次挥手呢?
为什么要三次握手?
- 简短来说就是,在建立通信连接之前,通信双方都确保自己与对方的发送、接收功能是正常的。
为什么要四次挥手?
通信双方的任何一方都可以在数据传输结束之后,发出连接释放的请求,待对方确认请求后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
总结一句话:确保通信双方在互相都关闭通信连接之前,已经没有数据在双方之间继续传输了,使双方可以安全的关闭连接。
9、TCP 滑动窗口和流量控制机制?
TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
10、TCP 拥塞控制机制?
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
为了进行拥塞控制,TCP 发送方要维持一个 拥塞窗口(cwnd) 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
TCP的拥塞控制采用了四种算法,即 慢开始 、 拥塞避免 、快重传 和 快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
- 慢开始: 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd初始值为1,每经过一个传播轮次,cwnd加倍。
- 拥塞避免: 拥塞避免算法的思路是让拥塞窗口cwnd缓慢增大,即每经过一个往返时间RTT就把发送放的cwnd加1.
- 快重传与快恢复: 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
总结
本篇文章的内容就到这了,希望大家可以多多关注自学编程网的其他精彩内容!

- 本文固定链接: https://zxbcw.cn/post/215418/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)