
1.预备知识
python语言,scrapy爬虫基础,json模块,flask后端
2.抓取CSDN数据接口
使用谷歌抓包工具抓取CSDN搜索引擎的接口
2.1 查看CSDN搜索引擎主页
查看CSDN搜索引擎主页https://so.csdn.net/,截图如下:
2.2测试CSDN搜索引擎的功能
测试CSDN搜索引擎的功能,尝试输入参数之后,查看返回的文章信息列表,测试如下:
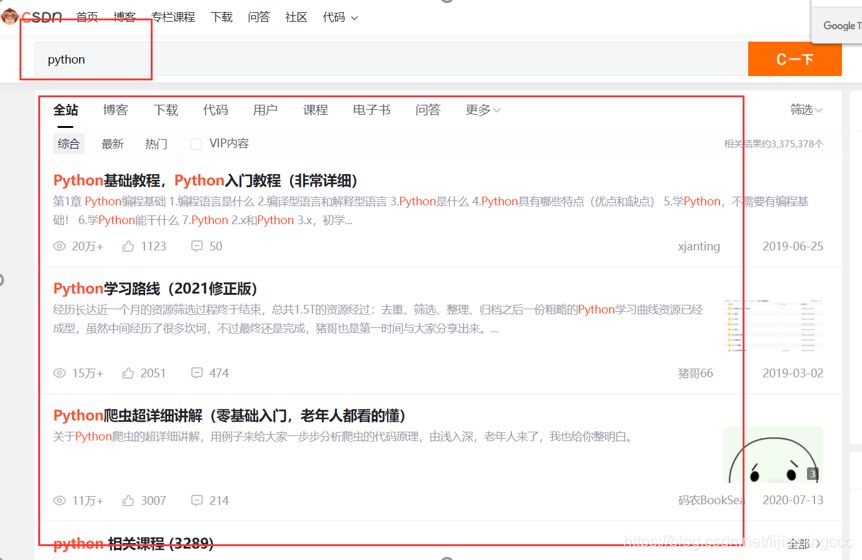
经过测试发现,CSDN搜索引擎的主要功能是,搜索所有跟python有关的文章,然后根据文章热度,点赞量,留言数进行一个综合排序,展示给用户排序后的文章结果。这样来说,我们的主要任务就是利用抓包抓取到前后端传输数据的接口,通过接口,来实现整个搜索引擎的效果。
2.3查看更多相关文章的信息
让我们把前端滑轮移到最后,发现并没有页数的标签,而是通过自动加载数据来呈现,效果如下:
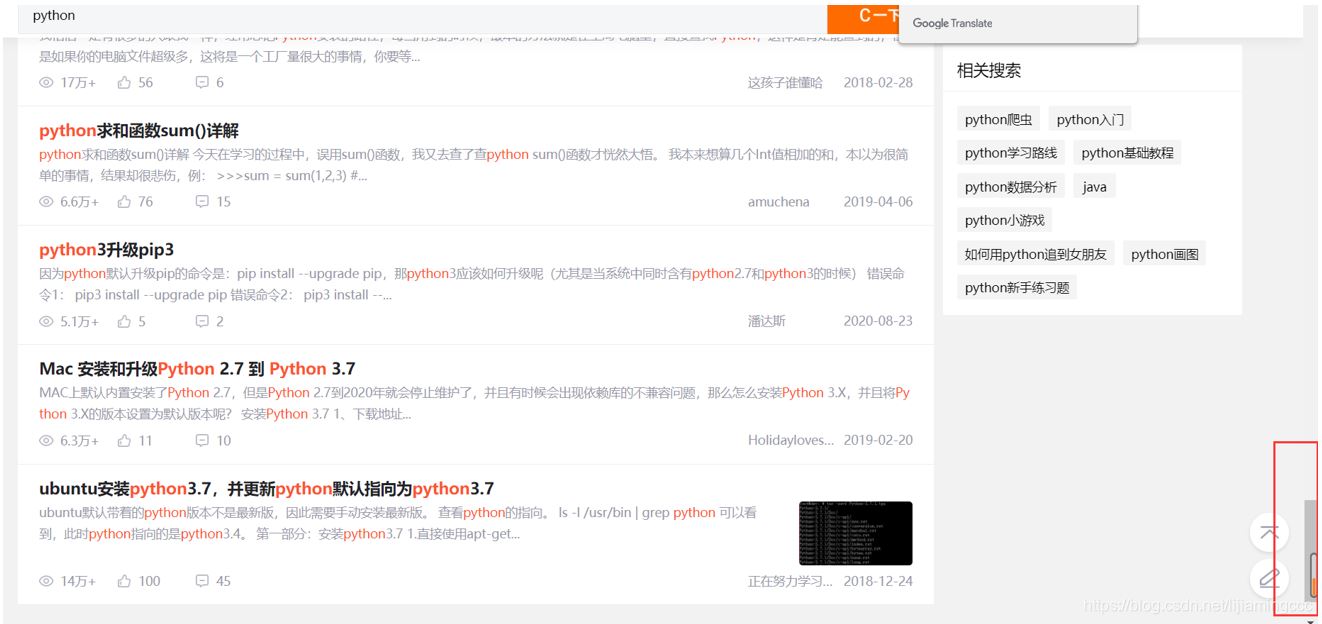
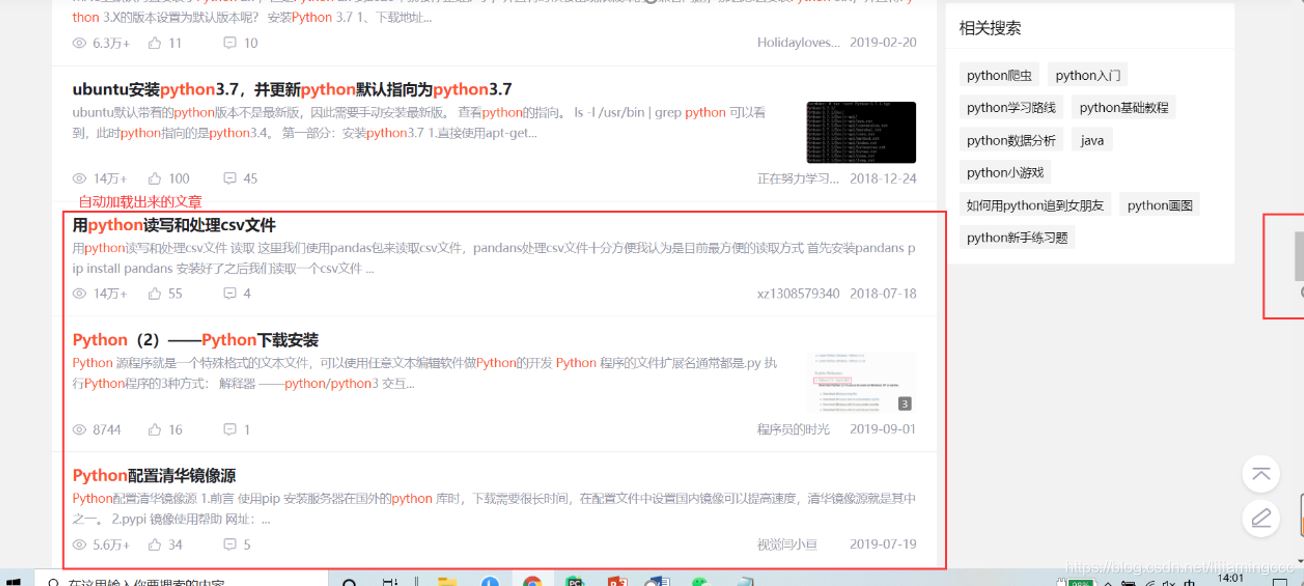
在不刷新整个页面的基础上加载新的数据,这很容易让我们联想到ajax异步请求。
异步请求通常就是利用ajax技术,能在不更新整个页面的前提下维护数据。这使得Web应用程序更为迅捷地回应用户动作,并避免了在网络上发送那些没有改变的信息。
接下来我们尝试利用谷歌浏览器抓取异步请求的信息。
2.4抓取ajax异步请求数据
使用谷歌浏览器抓取ajax异步请求数据
为了避免干扰因素,我们在抓包前需要点击clear按钮,清空当前的抓包记录
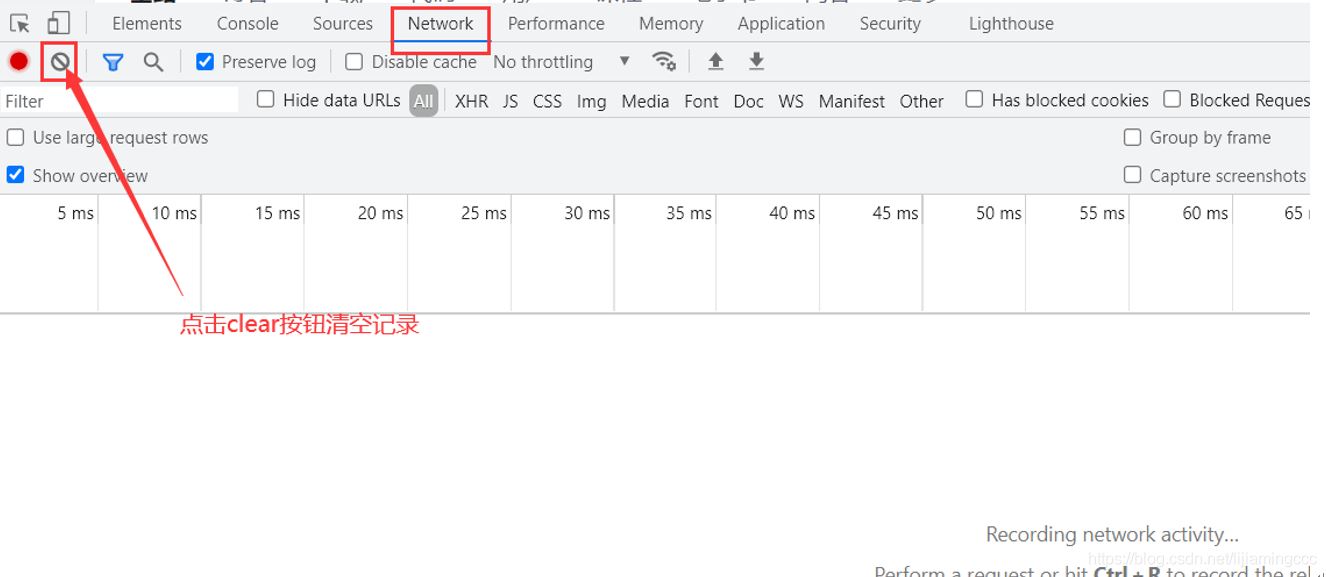
将滑块移动到最后,使前端页面自动加载数据,分析数据加载时抓取到的数据包信息。通过多次分析验证,发现结果有一个get请求携带着大量的刷新时的数据。如下图所示:
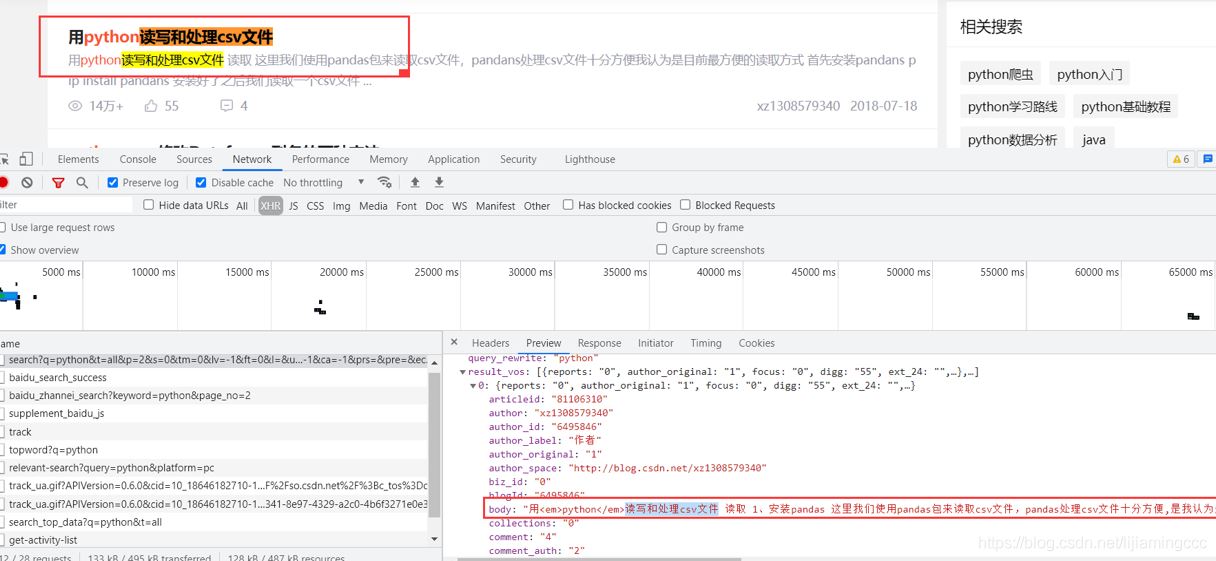
是JSON格式的数据,这里简单介绍一下JSON格式的数据。
JSON 是前后端传输数据最常见的用法之一,是从 web 服务器上读取 JSON 数据(作为文件或作为 HttpRequest),将 JSON 数据转换为 JavaScript 对象,然后在网页中使用该数据。
通过分析,我们可以发现数据是存放在result_vos列表下的各个字典中的,我们可以使用循环,然后通过dict[“xxx”]的方式来提取数据。
2.5 分析url地址

我们发现这个GET请求携带了大量的未知参数,通过经验分析,以及英语首字母,我们可以猜测P是page(页),Q是query(查询)的意思,其他xxx=-1应该是默认值,我们暂时按照这个猜测进行删减参数。
测试结果截图:
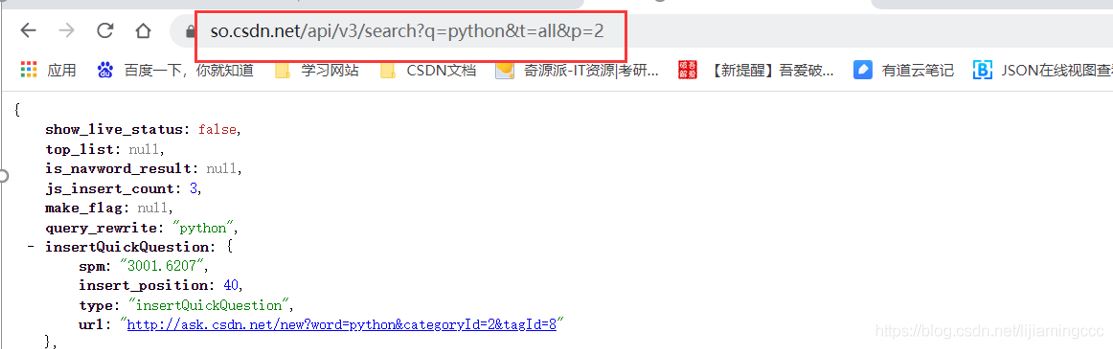
通过测试,发现猜测正确,只保留了q、t、p三个参数,依然可以访问到传输的数据内容(事实上,这里t参数也可以删除,同学们可以自行测试)
这样,这条url对应的重要参数都分析出来了,链接如下:
https://so.csdn.net/api/v3/search?q=python&t=all&p=2
跟我们猜测的一样,q是代表查询,p是代表page,这样我们已经获取到CSDN引擎的核心API,我们可以通过这条API来实现搜索引擎的功能。
至此,抓包分析过程结束。
3. 使用scrapy爬取CSDN数据接口
3.1 start_requests
使用start_requests函数进行构造20页的url列表。
这里start_requests方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于抓取的第一个Request。
当spider开始抓取并且未指定start_urls时,该方法将会被调用。该方法仅仅会被scrapy调用一次,因此可以将其实现为url生成器。
使用scrapy.Request可以发送一个GET请求,传送到指定的函数进行处理。
详细代码操作如下:
# 重写start_urls的方法
def start_requests(self):
# 这里是控制CSDN的文章类型
input_text = input('请输入要爬取的CSDN类型:')
# 是控制爬取文章页数
for i in range(1,31):
start_url = 'https://so.csdn.net/api/v3/search?q={}&p={}'.format(input_text,i)
yield scrapy.Request(
url=start_url,
callback=self.parse
)
3.2使用parse函数提取数据
这里需要掌握几个重要的方法应用
- response.text 请求返回的响应的字符串格式的数据
- json.loads() loads方法是将str转化为dict格式数据
- json.dumps() dumps方法是将dict格式的数据转化为str
具体代码操作如下:
data_dict = json.loads(response.text)
使用循环遍历json数据中的各个具体直播间数据的信息,新建一个item字典进行数据存储,然后使用yield传递给引擎进行相应的处理
代码操作如下:
def parse(self, response):
# response.request.headers
print(response.request.headers)
data_dict = json.loads(response.text)
for data in data_dict['result_vos']:
item = {}
# 标题
item['title'] = data['title'].replace('<em>','').replace('</em>','')
# 作者
item['author_label'] = data['nickname']
# 浏览量
item['view'] = data['view']
# 点赞量
item['zan'] = data['digg']
# 地址链接
item['link_url'] = data['url']
3.3保存成CSV文件
import csv
定义csv文件需要的列标题
headers = ['title','author_label','view','zan','jianjie' ,'link_url']
每次调用pipline的时候,都会运行一遍
class Day02Pipeline:
def process_item(self, item, spider):
文件默认保存到当前目录下的douyu.csv中
这里a是追加操作
with open('csdn.csv', 'a', encoding='utf-8', newline='') as fa:
保存headers规定的列名内容
writer = csv.DictWriter(fa, headers)
writer.writerow(item)
print(item)
return item
3.4 运行结果
最后,我们来查看一下运行结果,以及保存好的csv文件
终端运行结果如下:
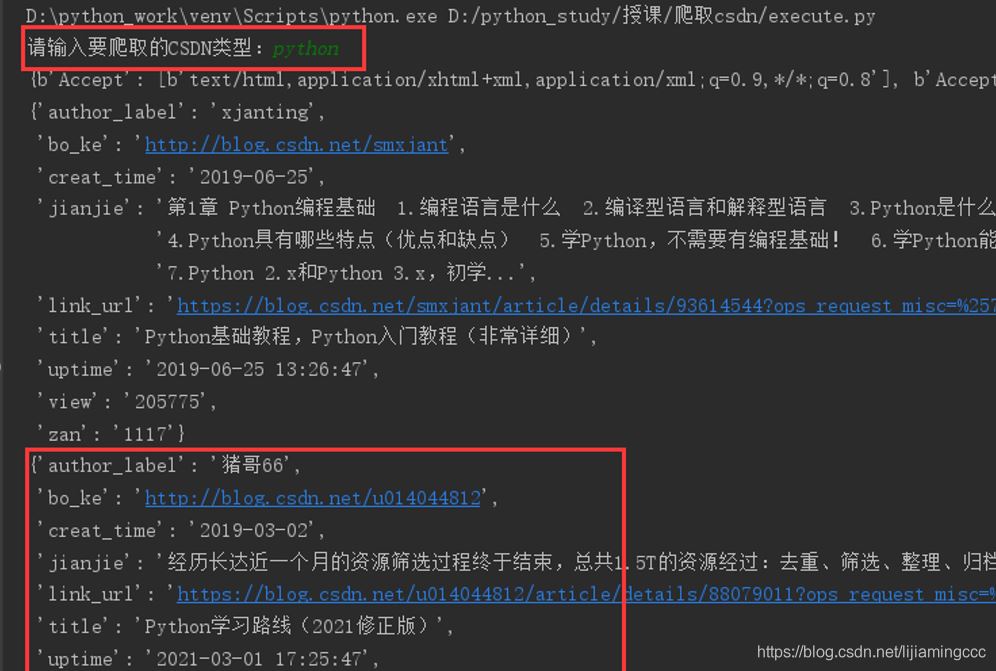

至此,爬虫实验结束。
4. 效果展示
4.1 flask后端展示
搭建过程略
(入门级搭建,没有用企业级开发流程,后期可以考虑出flask的教程)
展示结构如下:
flask入门可自行百度
4.2 效果展示
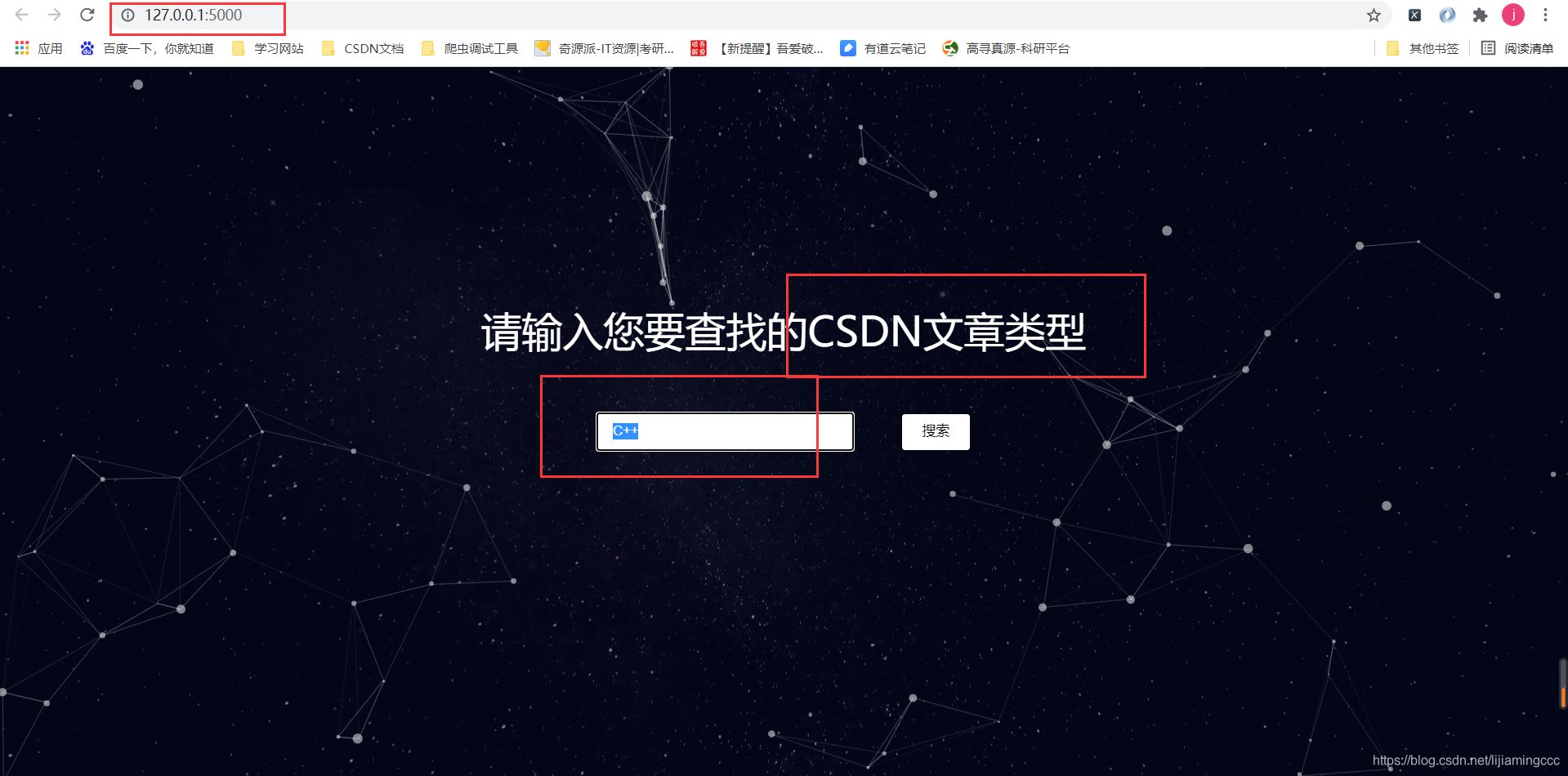
点击搜索后:
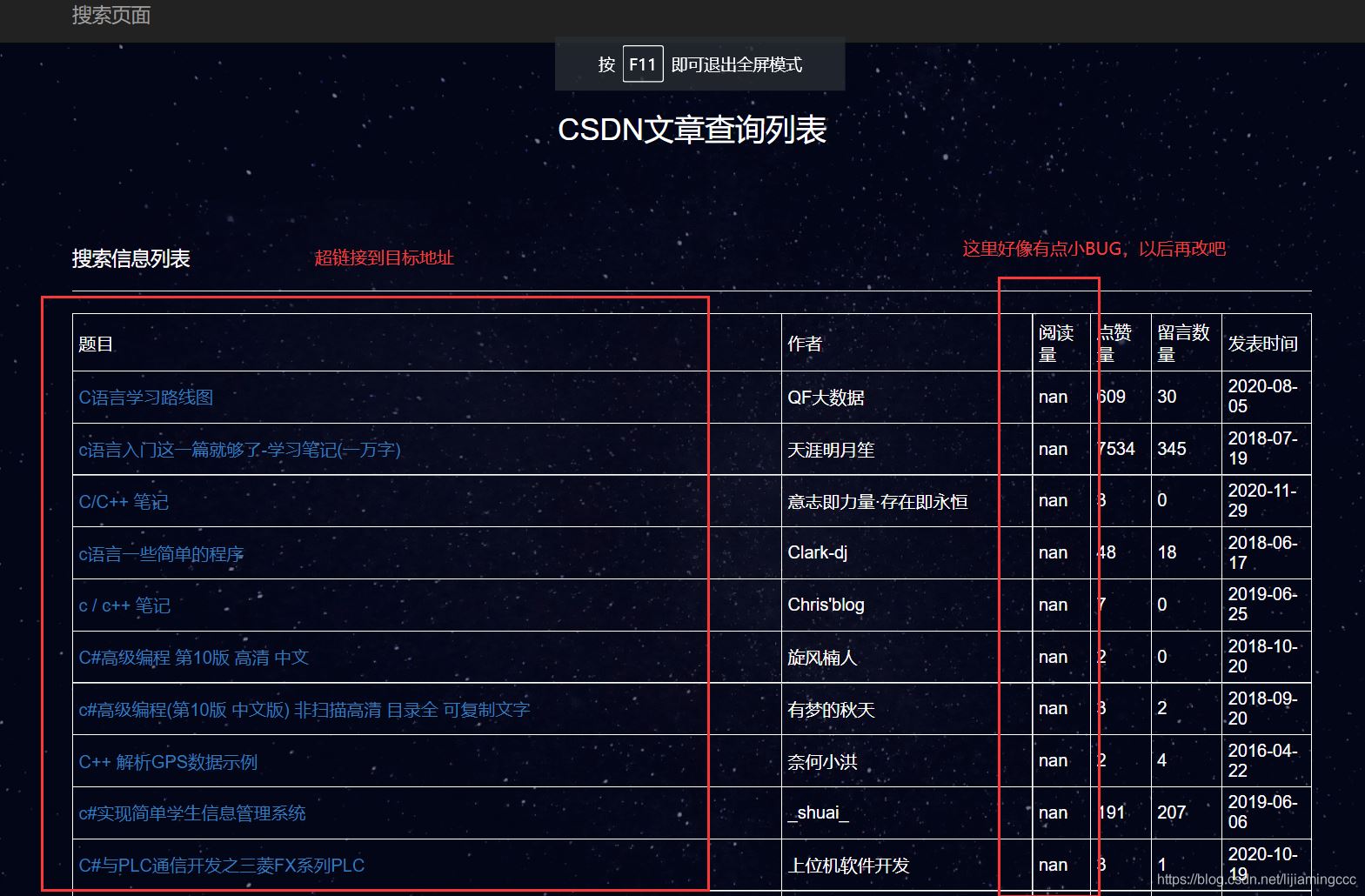
左上角的搜索页面是入口页面。
好了,这样简易版的搜索引擎就搭建好了。更多相关scrapy+flask+html搜索引擎内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/218051/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)