
在一个微服务架构中,系统的规模往往会比较大,各微服务之间的调用关系也错综复杂。通常一个有客户端发起的请求在后端系统中会经过多个不同的微服务调用阿里协同产生最后的请求结果。在复杂的微服务架构中,几乎每一个前端请求都会形成一条复杂的分布式的服务调用链路,在每条链路中任何一个依赖服务出现延迟过高或错误的时候都有可能引起请求最后的失败。
这个时候,对于每个请求,全链路调用的跟踪就边得越来越重要,通过实现对请求调用的跟踪可以帮助我们快速发现问题根源以及监控分析每条请求链路上的性能瓶颈等。而Spring Cloud Sleuth就是一个提供了一套完整的解决方案的组件。
在开始今天的这个例子之前,可以看一下我之前的几篇博客,特别是hystrix之前的博客。本篇博客就是在这基础上所增加的新功能。在之前的实践中,通过9004的customer-server项目调用9003的hello-server项目的接口。
准备工作
在之前的服务调用的方法上加上日志操作。
customer-server的CustomerController类:
@RequestMapping("/sayHello1")
@ResponseBody
public String invokeSayHello1(String name){
logger.info("调用了customer-server的sayHello1方法,参数为:{}",name);
return serivce.invokeSayHello1(name);
}
hello-server的Hello1Controller类:
@RequestMapping("/sayHello1")
public String sayHello1(@RequestParam("name") String name){
logger.info("你好,服务名:{},端口为:{},接收到的参数为:{}",instanceName,host,name);
try {
int sleepTime = new Random().nextInt(3000);
logger.error("让线程阻塞 {} 毫秒",sleepTime);
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "你好,服务名:"+instanceName+",端口为:"+host+",接收到的参数为:"+name;
}
在页面上访问localhost:9004/sayHello1?name=charon
# customer-server中的打印日志 2021-08-09 23:22:33.905 INFO 19776 --- [nio-9004-exec-8] c.c.e.controller.CustomerController : 调用了customer-server的sayHello1方法,参数为:charon # hello-server中的打印日志 2021-08-09 23:22:33.917 INFO 2884 --- [nio-9003-exec-9] c.c.e.controller.Hello1Controller : 你好,服务名:hello-server,端口为:9003,接收到的参数为:charon
实现跟踪
在修改完上面的代码后,为customer-server项目和hello-server项目添加服务跟踪的功能,引入依赖
<!--引入sleuth链路追踪的jar包-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
页面调用查看日志:
# customer-server中的打印日志 2021-08-09 23:30:44.782 INFO [customer-server,0e307552774ef605,0e307552774ef605,true] 14616 --- [nio-9004-exec-2] c.c.e.controller.CustomerController : 调用了customer-server的sayHello1方法,参数为:charon # hello-server中的打印日志 2021-08-09 23:30:44.807 INFO [hello-server,0e307552774ef605,4cf4d9dd57ca7478,true] 6660 --- [nio-9003-exec-2] c.c.e.controller.Hello1Controller : 你好,服务名:hello-server,端口为:9003,接收到的参数为:charon
从上面的控制台的输出内容可以看到形如[customer-server,0e307552774ef605,0e307552774ef605,true] 的日志信息,而浙西而元素正是实现分布式服务跟踪的重要组成部分,每个值的含义如下:
- customer-server:应用的名称,也就是application.properties中的soring。application.name的值
- 0e307552774ef605:Spring Cloud Sleuth生成的一个ID,成微Trace ID,它用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID。
- 0e307552774ef605:Spring Cloud Sleuth生成的另一个ID,成为Span ID,它表识一个基本的工作单元,比如发怂一个HTTP请求
- true:表示是否要将改信息输出到Zipkin等服务中来收集和展示
在一个服务请求链路的调用过程中,会包吃并传递同一个Trace ID,从而将整个分布于不容微服务进程中的请求跟踪信息串联起来。以上面输出内容为例,customer-server和hello-server同属于一个前端服务请求来源,所以他们的Trace ID是相同的,处于同一个请求链路中。通过Trace ID,我们就能将所有请求过程的日志关联起来。
在Spring Boot应用中,通过引入spring-cloud-starter-sleuth依赖之后,他会自动为当前应用构建起通道跟踪机制,比如:
- 通过RabbitMQ,Kafka等中间件传递的请求
- 通过Zuul代理传递的请求
- 通过RestTemplate发起的请求。
抽样收集
通过TraceID和SpanID已经实现了对分布式系统中的请求跟踪,而记录的跟踪信息最终会被分析系统收集起来,并用来实现对分布式系统的监控和分析功能。
理论上讲,收集的跟踪信息越多就可以越好的反应系统的真实运行情况,并给出更精准的预警和分析,但是在高并发的分布式系统运行时,大两的请求调用会产生海量的跟踪日志信息,如果收集过多对整个系统的性能也会造成一定的影响,同时保存大两的日志信息也需要很大的存储开销。所以在Sleuth中菜用了抽样收集的方式来为跟踪信息打商收集标记。也就是我们之前在日志信息中看到的第4个布尔类型的值,它代表了改信息是否要改后续的跟踪信息收集器获取或存储。
默认情况下,Sleuth会使用 zipkin brave的ProbabilityBasedSampler的抽样策略(现在已经不推荐使用),即以请求百分比的方式配置和收集跟踪信息,我们可以在配置文件中配置参数对其百分比值进行设置(它的默认值为 0.1,代表收集 10% 的请求跟踪信息)。
spring.sleuth.sampler.probability=0.5
而如果在配置文件中配置了 spring.sleuth.sampler.rate 的属性值,那么便会使用zipkin Brave自带的RateLimitingSampler的抽样策略。不同于ProbabilityBasedSampler菜用概况收集的策略,RateLimitingSampler是菜用的限速收集,也就是说它可以用来限制每秒跟踪请求的最大数量。
- 如果同时设置了 spring.sleuth.sampler.rate 和 spring.sleuth.sampler.probability 属性值,也仍然使用 RateLimitingSampler 抽样策略(即 spring.sleuth.sampler.probability 属性值无效)
- RateLimitingSampler 策略每秒间隔接受的 trace 量设置范围:最小数字为 0,最大值为 2,147,483,647(最大 int)
整合Zipkin
Zipkin是twitter的一个开源项目,它基于Google Dapper实现,我们可以用它来实现收集各个服务器上的请求链路的跟踪。并通过它提供的REST API接口来辅助查询跟踪数据以实现对分布式系统的监控程序,从而及时发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。同时,Zipkin还提供了方便的UI组件来帮助我们直观地所搜跟踪信息和分析请求地链路明细,比如可以查询某段时间内各用户请求地处理时间等。
Spring Boot 2.x 以后官网不推荐使用源码方式编译,推荐使用官网编译好的jar执行。所以我们不熟Zipkin也使用jar包的方式。
1.下载Zipkin
我这里是到maven仓库中下载的。
https://search.maven.org/remote_content?g=io.zipkin.java&a=zipkin-server&v=LATEST&c=exec
下载完成后,使用java -jar命令启动zipkin。
2.引入依赖配置
为customer-server和hello-server的项目引入zipkin的包:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
配置文件添加zipkin的地址:
spring.zipkin.base-url=http://localhost:9411
3.测试与分析
完成所有接入Zipkin的工作后,依次讲服务起来,浏览器发送请求做测试。
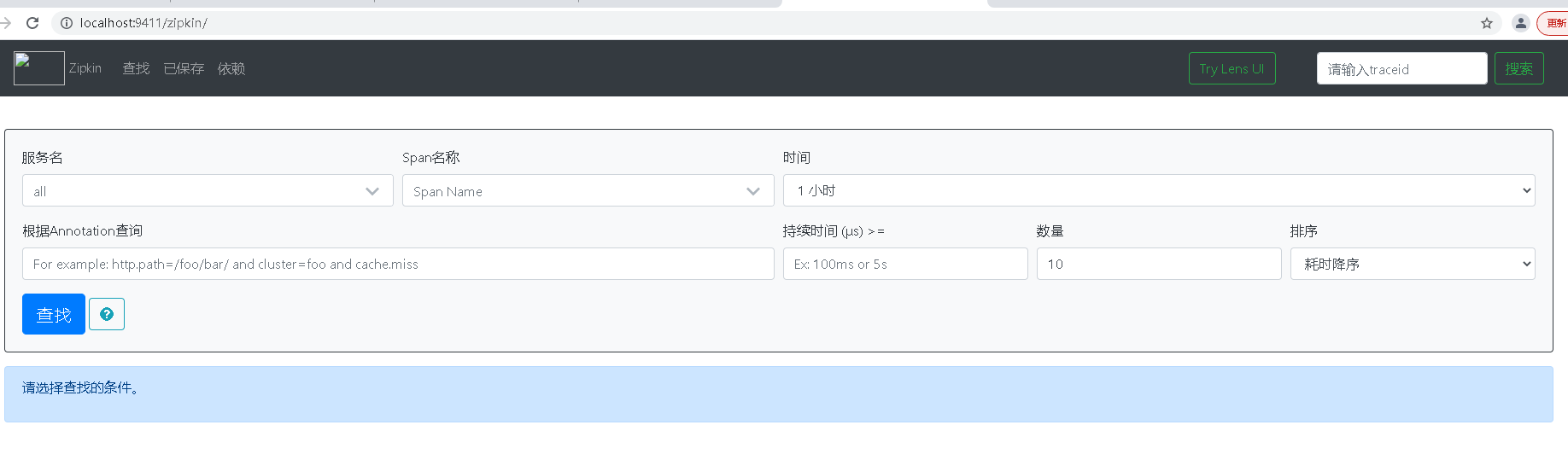
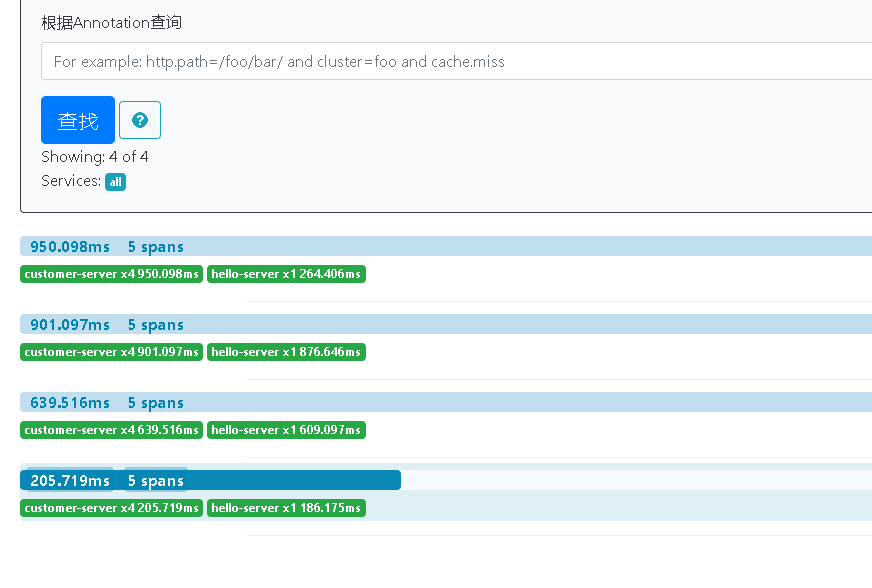
点击查找按钮,下方出现服务调用的信息。注意,只有在sleuth的最后一个参数为true的时候,才会讲改跟踪信息输出给Zipkin Server。
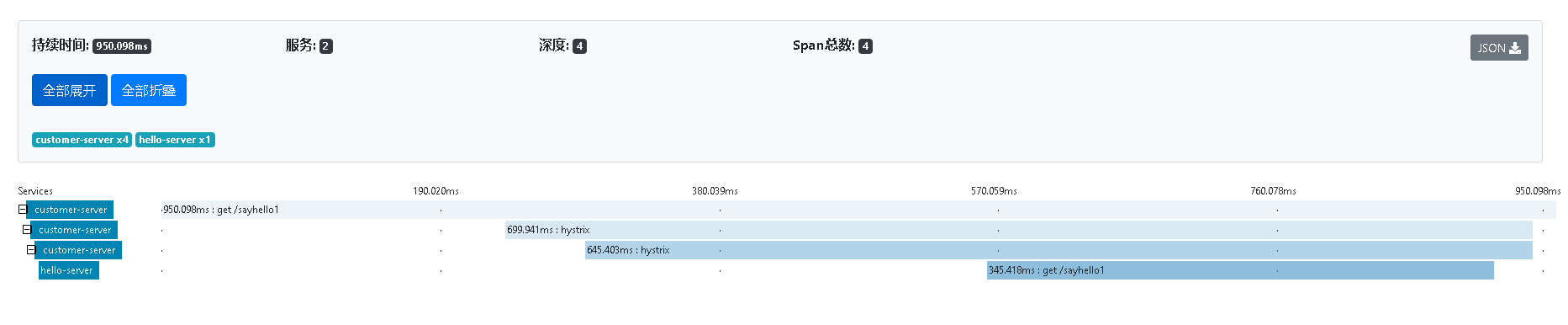
单击其中的某一个,还可以得到Sleuth跟踪到的详细信息。其中就包括时间请求时间消耗等。
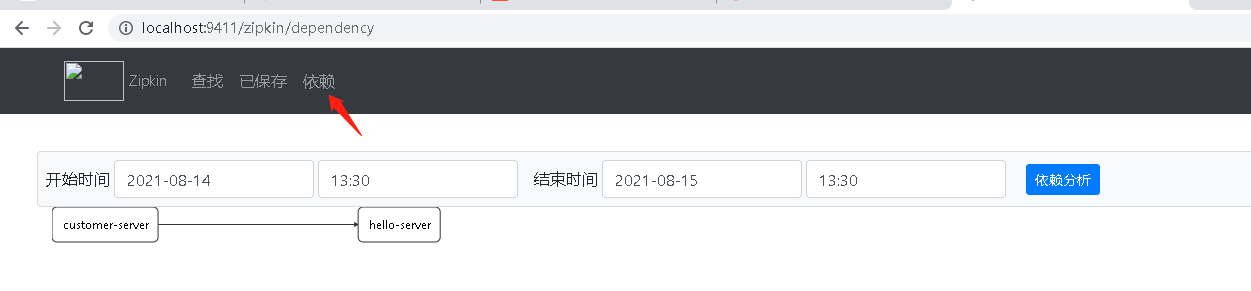
单击导航栏中的依赖按钮,还可以查看到Zipkin根据跟踪信息分析生成的系统关系请求链路依赖关系图。
持久化到mysql
在SpringBoot2.0之前的版本,Zipkin-Server端由我们自己创建项目来搭建。可以比较灵活的选择数据持久化的配置,SpringBoot2.0之后的版本,Zipkin-Server端由官方提供,无需我们自己搭建,那么如何选择去配置将数据持久化到MySQL呢?
1.创建zipkin数据库
在下载好的zipkin-serve的jar包中,找到zipkin-server-shared.yml的文件,

在里面可以找到关于mysql的持久化配置,可以看到数据库名称默认为zipkin,
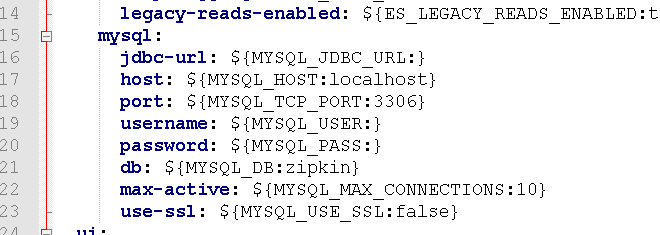
初始化mysql的脚本:https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
创建的数据库如下:
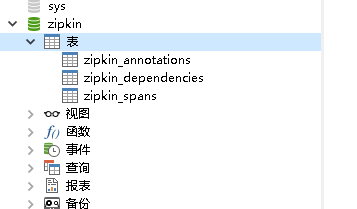
2.启动zipkin
在启动zipkin的时候,以命令行的方式启动,输入mysql的参数
java -jar zipkin-server-2.12.9-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_DB=zipkin --MYSQL_USER=root --MYSQL_PASS=root
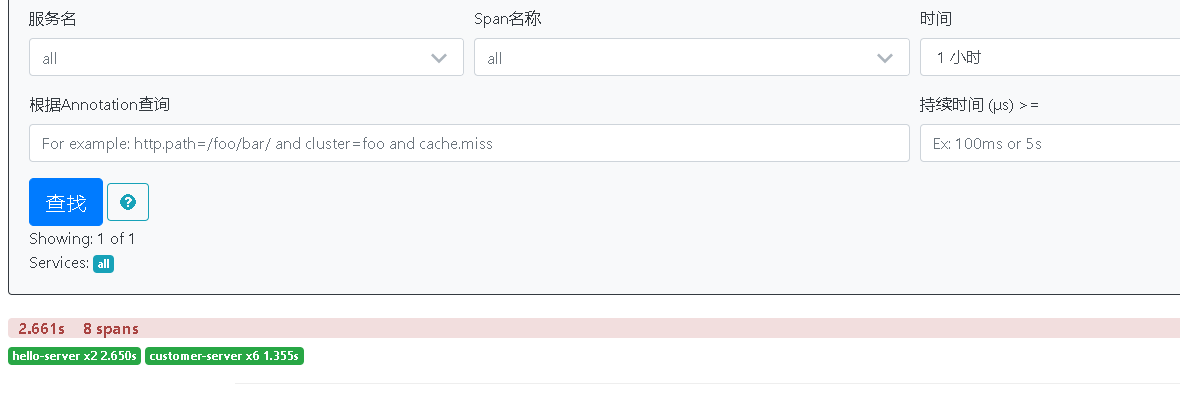
3.测试与分析
浏览器访问,因为我这次调用服务超时了,触发了hystrix的断路器功能,所以这次有8个span。
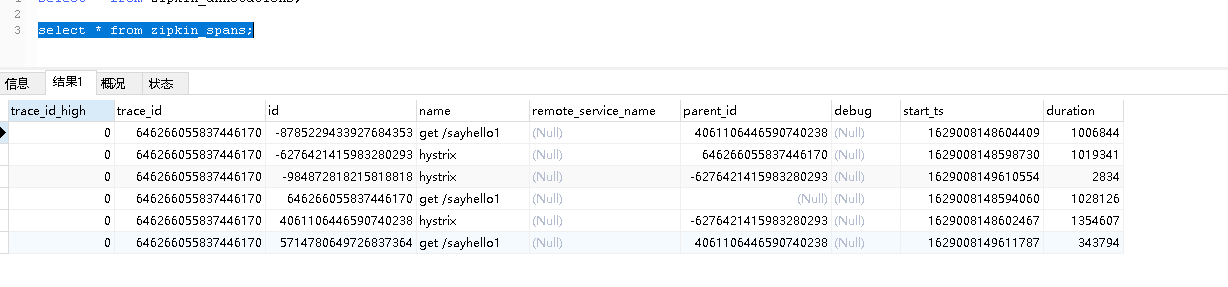
关闭zipkin-server,然后重启,发现依然能够查询到上一次请求的服务链路跟踪数据。查看数据库表,发现数据都存储到表里了。
参考文章:
翟永超老师的《Spring Cloud微服务实战》
https://www.hangge.com/blog/cache/detail_2803.html
https://blog.csdn.net/Thinkingcao/article/details/104957540
到此这篇关于Spring Cloud 专题之Sleuth 服务跟踪的文章就介绍到这了,更多相关Spring Cloud Sleuth 服务跟踪内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/219712/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)