
一直都听说DOM很慢,要尽量少的去操作DOM,于是就想进一步去探究下为什么大家都会这样说,在网上学习了一些资料,这边整理出来。
首先,DOM对象本身也是一个js对象,所以严格来说,并不是操作这个对象慢,而是说操作了这个对象后,会触发一些浏览器行为,比如布局(layout)和绘制(paint)。下面主要先介绍下这些浏览器行为,阐述一个页面是怎么最终被呈现出来的,另外还会从代码的角度,来说明一些不好的实践以及一些优化方案。
浏览器是如何呈现一张页面的
一个浏览器有许多模块,其中负责呈现页面的是渲染引擎模块,比较熟悉的有WebKit和Gecko等,这里也只会涉及这个模块的内容。
先用文字大致阐述下这个过程:
- 解析HTML,并生成一棵DOM tree
- 解析各种样式并结合DOM tree生成一棵Render tree
- 对Render tree的各个节点计算布局信息,比如box的位置与尺寸
- 根据Render tree并利用浏览器的UI层进行绘制
其中DOM tree和Render tree上的节点并非一一对应,比如一个display:none的节点就在会存在与DOM tree上,而不会出现在Render tree上,因为这个节点不需要被绘制。
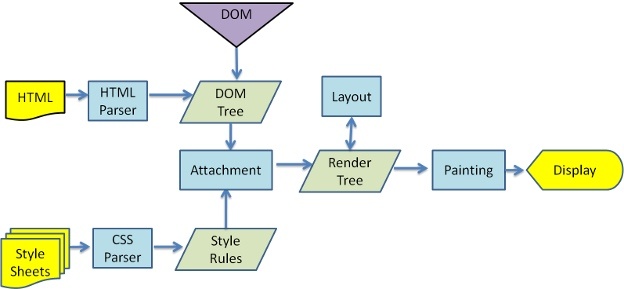
上图是Webkit的基本流程,在术语上和Gecko可能会有不同,这里贴上Gecko的流程图,不过文章下面的内容都会统一使用Webkit的术语。
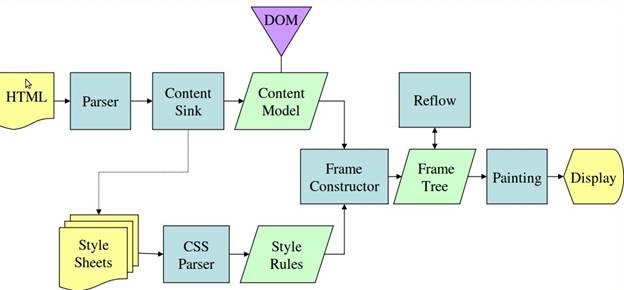
影响页面呈现的因素有许多,比如link的位置会影响首屏呈现等。但这里主要集中讨论与layout相关的内容。
paint是一个耗时的过程,然而layout是一个更耗时的过程,我们无法确定layout一定是自上而下或是自下而上进行的,甚至一次layout会牵涉到整个文档布局的重新计算。
但是layout是肯定无法避免的,所以我们主要是要最小化layout的次数。
什么情况下浏览器会进行layout
在考虑如何最小化layout次数之前,要先了解什么时候浏览器会进行layout。
layout(reflow)一般被称为布局,这个操作是用来计算文档中元素的位置和大小,是渲染前重要的一步。在HTML第一次被加载的时候,会有一次layout之外,js脚本的执行和样式的改变同样会导致浏览器执行layout,这也是本文的主要要讨论的内容。
一般情况下,浏览器的layout是lazy的,也就是说:在js脚本执行时,是不会去更新DOM的,任何对DOM的修改都会被暂存在一个队列中,在当前js的执行上下文完成执行后,会根据这个队列中的修改,进行一次layout。
然而有时希望在js代码中立刻获取最新的DOM节点信息,浏览器就不得不提前执行layout,这是导致DOM性能问题的主因。
如下的操作会打破常规,并触发浏览器执行layout:
- 通过js获取需要计算的DOM属性
- 添加或删除DOM元素
- resize浏览器窗口大小
- 改变字体
- css伪类的激活,比如:hover
- 通过js修改DOM元素样式且该样式涉及到尺寸的改变
我们来通过一个例子直观的感受下:
// Read var h1 = element1.clientHeight; // Write (invalidates layout) element1.style.height = (h1 * 2) + 'px'; // Read (triggers layout) var h2 = element2.clientHeight; // Write (invalidates layout) element2.style.height = (h2 * 2) + 'px'; // Read (triggers layout) var h3 = element3.clientHeight; // Write (invalidates layout) element3.style.height = (h3 * 2) + 'px';
这里涉及一个属性clientHeight,这个属性是需要计算得到的,于是就会触发浏览器的一次layout。我们来利用chrome(v47.0)的开发者工具看下(截图中的timeline record已经经过筛选,仅显示layout):
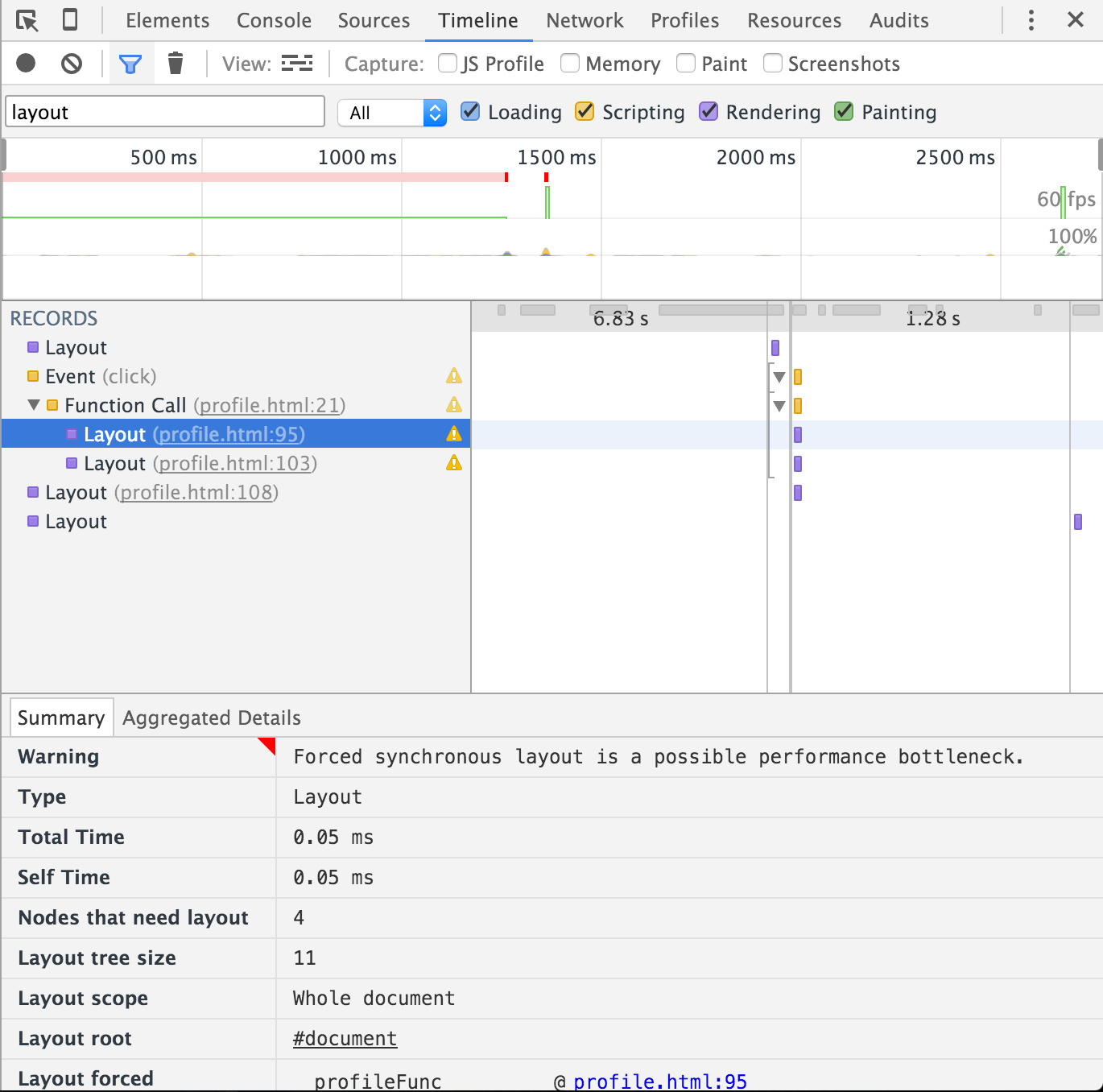
上面的例子中,代码首先修改了一个元素的样式,接下来读取另一个元素的clientHeight属性,由于之前的修改导致当前DOM被标记为脏,为了保证能准确的获取这个属性,浏览器会进行一次layout(我们发现chrome的开发者工具良心的提示了我们这个性能问题)。
优化这段代码很简单,预先读取所需要的属性,在一起修改即可。
// Read var h1 = element1.clientHeight; var h2 = element2.clientHeight; var h3 = element3.clientHeight; // Write (invalidates layout) element1.style.height = (h1 * 2) + 'px'; element2.style.height = (h2 * 2) + 'px'; element3.style.height = (h3 * 2) + 'px';
看下这次的情况:

下面再介绍一些其他的优化方案。
最小化layout的方案
上面提到的一个批量读写是一个,主要是因为获取一个需要计算的属性值导致的,那么哪些值是需要计算的呢?
这个链接里有介绍大部分需要计算的属性:http://gent.ilcore.com/2011/03/how-not-to-trigger-layout-in-webkit.html
再来看看别的情况:
面对一系列DOM操作
针对一系列DOM操作(DOM元素的增删改),可以有如下方案:
- documentFragment
- display: none
- cloneNode
比如(仅以documentFragment为例):
var fragment = document.createDocumentFragment();
for (var i=0; i < items.length; i++){
var item = document.createElement("li");
item.appendChild(document.createTextNode("Option " + i);
fragment.appendChild(item);
}
list.appendChild(fragment);
这类优化方案的核心思想都是相同的,就是先对一个不在Render tree上的节点进行一系列操作,再把这个节点添加回Render tree,这样无论多么复杂的DOM操作,最终都只会触发一次layout。
面对样式的修改
针对样式的改变,我们首先需要知道并不是所有样式的修改都会触发layout,因为我们知道layout的工作是计算RenderObject的尺寸和大小信息,那么我如果只是改变一个颜色,是不会触发layout的。
这里有一个网站CSS triggers,详细列出了各个CSS属性对浏览器执行layout和paint的影响。
像下面这种情况,和上面讲优化的部分是一样的,注意下读写即可。
elem.style.height = "100px"; // mark invalidated elem.style.width = "100px"; elem.style.marginRight = "10px"; elem.clientHeight // force layout here
但是要提一下动画,这边讲的是js动画,比如:
function animate (from, to) {
if (from === to) return
requestAnimationFrame(function () {
from += 5
element1.style.height = from + "px"
animate(from, to)
})
}
animate(100, 500)
动画的每一帧都会导致layout,这是无法避免的,但是为了减少动画带来的layout的性能损失,可以将动画元素绝对定位,这样动画元素脱离文本流,layout的计算量会减少很多。
使用requestAnimationFrame
任何可能导致重绘的操作都应该放入requestAnimationFrame
在现实项目中,代码按模块划分,很难像上例那样组织批量读写。那么这时可以把写操作放在requestAnimationFrame的callback中,统一让写操作在下一次paint之前执行。
// Read
var h1 = element1.clientHeight;
// Write
requestAnimationFrame(function() {
element1.style.height = (h1 * 2) + 'px';
});
// Read
var h2 = element2.clientHeight;
// Write
requestAnimationFrame(function() {
element2.style.height = (h2 * 2) + 'px';
});
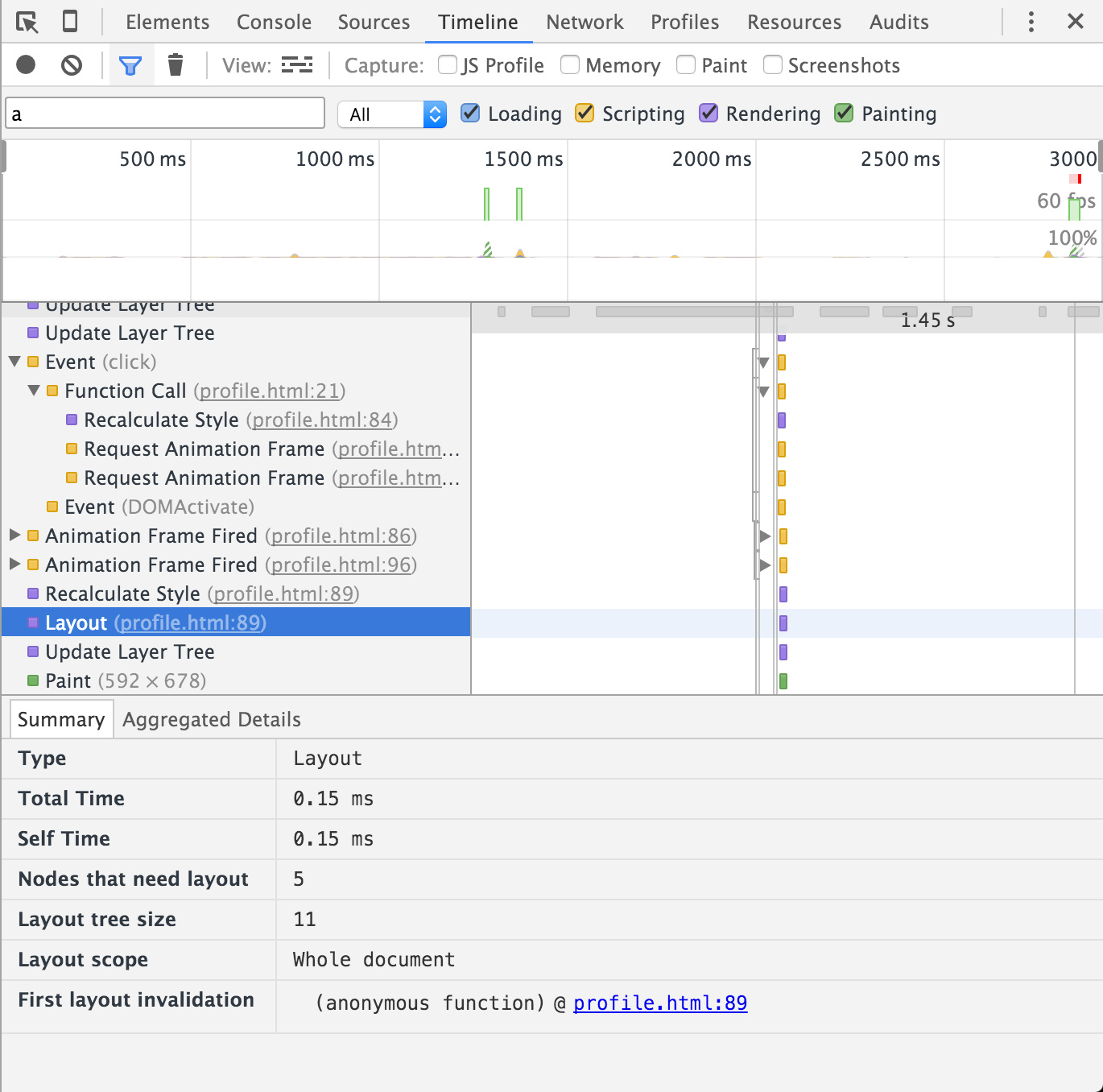
可以很清楚的观察到Animation Frame触发的时机,MDN上说是在paint之前触发,不过我估计是在js脚本交出控制权给浏览器进行DOM的invalidated check之前执行。
其他注意点
除了由于触发了layout而导致性能问题外,这边再列出一些其他细节:
缓存选择器的结果,减少DOM查询。这里要特别体下HTMLCollection。HTMLCollection是通过document.getElementByTagName得到的对象类型,和数组类型很类似但是每次获取这个对象的一个属性,都相当于进行一次DOM查询:
var divs = document.getElementsByTagName("div");
for (var i = 0; i < divs.length; i++){ //infinite loop
document.body.appendChild(document.createElement("div"));
}
比如上面的这段代码会导致无限循环,所以处理HTMLCollection对象的时候要最些缓存。
另外减少DOM元素的嵌套深度并优化css,去除无用的样式对减少layout的计算量有一定帮助。
在DOM查询时,querySelector和querySelectorAll应该是最后的选择,它们功能最强大,但执行效率很差,如果可以的话,尽量用其他方法替代。
下面两个jsperf的链接,可以对比下性能。
https://jsperf.com/getelementsbyclassname-vs-queryselectorall/162
http://jsperf.com/getelementbyid-vs-queryselector/218
自己对View层的想法
上面的内容理论方面的东西偏多,从实践的角度来看,上面讨论的内容,正好是View层需要处理的事情。已经有一个库FastDOM来做这个事情,不过它的代码是这样的:
fastdom.read(function() {
console.log('read');
});
fastdom.write(function() {
console.log('write');
});
问题很明显,会导致callback hell,并且也可以预见到像FastDOM这样的imperative的代码缺乏扩展性,关键在于用了requestAnimationFrame后就变成了异步编程的问题了。要让读写状态同步,那必然需要在DOM的基础上写个Wrapper来内部控制异步读写,不过都到了这份上,感觉可以考虑直接上React了......
总之,尽量注意避免上面说到的问题,但如果用库,比如jQuery的话,layout的问题出在库本身的抽象上。像React引入自己的组件模型,用过virtual DOM来减少DOM操作,并可以在每次state改变时仅有一次layout,我不知道内部有没有用requestAnimationFrame之类的,感觉要做好一个View层就挺有难度的,之后准备学学React的代码。希望自己一两年后会过来再看这个问题的时候,可以有些新的见解。
参考
- http://www.html5rocks.com/en/tutorials/internals/howbrowserswork/
- https://dev.opera.com/articles/efficient-javascript/?page=3
- http://wilsonpage.co.uk/preventing-layout-thrashing/
- https://www.nczonline.net/blog/2009/02/03/speed-up-your-javascript-part-4/
- http://gent.ilcore.com/2011/03/how-not-to-trigger-layout-in-webkit.html

- 本文固定链接: https://zxbcw.cn/post/4469/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)