
机器学习是数据科学的发动机。每种机器学习方法(也称为算法)获取数据,反复咀嚼,输出结果。机器学习算法负责数据科学里最难以解释又最有趣的部分。数学的魔法在此发生。
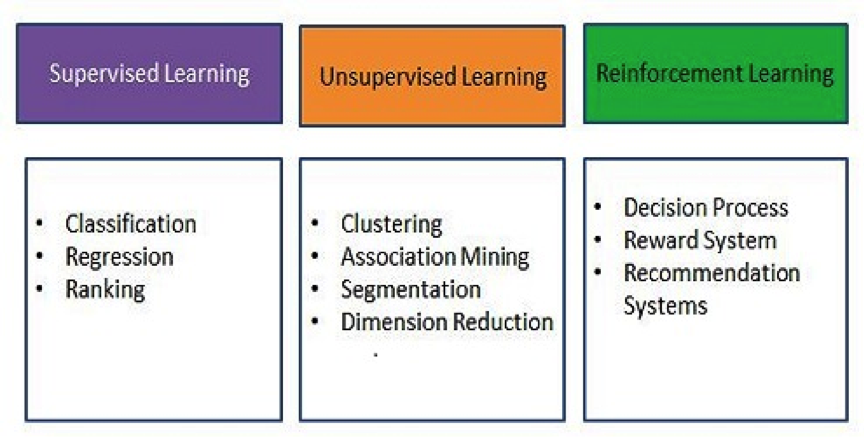
机器学习算法可以根据它们所回答的问题分成几组。这种分组能够在你提炼问题时帮助思考。
A类还是B类?
这组算法被称为二类分类( two-class classification )。适用于任何有两个可能选项的问题:是或否、开或关、吸烟或不吸烟、买或不买。许多数据科学问题看起来是这种形式,或者可以被组织成这种形式。这是最简单也最常提到的数据科学问题。几个典型的例子:
1.这名顾客会不会继续订阅?
2.这图片上是一只猫还是一只狗?
3.这名顾客会不会点击顶部链接?
4.在接下来的一千英里轮胎会不会报废?
5.5美元打折券和25%打折券哪个能吸引更多回头客?
A类、B类、C类还是D类?
这组算法被称作多类分类( multi-class classification )。如同名字所示,这组算法回答有多个可能答案的问题:哪种口味、哪个人、哪个部分、哪个公司、哪位候选人。大多数多类分类算法只是二类分类算法的延伸。一些典型例子如下:
1.这图片上是哪种动物?
2.这种雷达信号是哪种飞行器引起的?
3.这篇新闻是什么主题?
4.这条推特是什么情绪?
5.这段录音里的说话人是谁?
是否异常?
这组算法进行异常检测( anomaly detection )。它们识别出异常的数据点。如果仔细留意,你会发现异常检测看起来像二元分类问题。问题可以用“是”或“否”来回答。不同之处时,二元分类假定你已经有一些“是”/“不是”的案例。异常检测则不是这样。当你所寻找的东西如此稀少(如设备失灵),以至于没能收集太多有关案例时,异常检测尤其有用。 当“不正常”包含多种情况时(如信用卡诈骗),异常检测也很有帮助。一些常见的异常检测问题:
1.这个压力读数是否异常?
2.这则网上信息有代表性吗?
3.这个购物组合是否与此消费者之前所做的非常不同?
4.这些电压在这个季节的这个时间是否正常?
多少?
当你想求一个数字,而不是一个分级或类别,此时要用到的是回归。
1.下周二会是什么温度?
2.我第四季度在葡萄牙的销售额会是多少?
3.在接下来半个小时,我的风力发电厂会有多少千瓦的需求?
4.下周我会获得多少新粉丝?
5.这种型号的轴承,每一千个中有多少能工作超过一万小时?
通常来说,回归算法给出一个实值作为答案。答案可能会有小数或负数。对于一些问题,尤其是以“多少个”开头的问题,负数需要被解读为0,分数要取近似整数。
多类分类作为回归问题
有时看似多元分类的问题事实上比较适合做回归。比如,“哪个新闻故事对读者来说更有趣?”看似在询问类别——新闻故事清单里的一个条目。然而,问题可以重新组织成“对于读者来说,清单上的每个故事在多大程度上有趣?”给每篇文章一个数字作为分数。之后就是一个简单的识别最高分文章问题。这种类型的问题通常以排名或比较形式出现。
1.“我船队的哪个货舱最需要维修?”可以被转述为“我船队的货舱各在多大程度上需要维修?”
2.“我的顾客中,哪5%明年会转向我的竞争对手?可以被转述为“我的每个客户明年各有多大可能转向我的竞争对手?”
二类分类作为回归问题
并不奇怪,二元分类也可以被转述为回归问题。(事实上,一些算法私下把所有二元分类问题转化为回归。)当一个案例可能属于A或B,或有一定几率属于任意一方时,这种方法尤其有帮助。当答案可能为部分的“是”或“否”,可能是“开”也可能是“关”,回归能够体现这种情况。这种问题通常由“多大可能”或“多大比例”开头:
1.这个用户有多大可能点击我的广告?
2.这个老虎机上多大比例的拉动导致了吐钱?
3.这个员工有多大可能是一个内部安全隐患?
4.今天的航班有多大比例准时起飞?
你可能已经猜到,二元分类、多类分类、异常检测和回归全部是紧密相关的。它们属于同一个延伸的家庭,监督学习。它们有许多相同之处,问题通常能被修改为不止一种形式。它们的共性是,它们都是通过一组加了标签的样本建立(被称作“训练”的过程),之后它们能对于无标签的样本赋予值或类别(被称作“打分”的过程)。
无监督学习和增强学习的算法家族则有完全不同的数据科学问题。
数据是如何构成?
有关数据如何构成的问题属于无监督学习。有许多技术试图提炼数据的结构。其中一组算法进行聚类,也被称作分块、分组、聚群、分隔等。它们试图把一个数据集分为一些直觉式的区块。聚类与监督学习的不同之处,是没有数字或名称可以告诉你数据点属于哪个类别,这些分组代表什么,或应该有多少个组。如果监督学习是在夜空群星中挑选出星球,那么聚类就是在构造星座。聚类试图把数据分成自然的“丛”,以便作为分析师的人类能更轻易地向他人解释。聚类一贯依赖于一个紧密度或相似性的定义,如智商差异、相同基因对或鸟瞰直线距离。聚类问题都试着把数据分解成近乎一致的群组。
1.哪些顾客对农产品有相似的喜好?
2.哪些观众喜欢同类的电影?
3.这个变电所在一周的哪些日子有相似的用电需求?
4.用什么办法把这些文件自然地分成五类?
另一组无监督学习算法叫维度归约(dimensionality reduction)技术。维度归约是另一种简化数据的方式,让数据能更容易传播,更快速计算,更容易存储。
在根本上,维度归约都是在创造一种描述数据点的简易方法。一个简单的例子是GPA学分绩点。一个大学生的学术能力,由数十个课程的数百场考试和数千个作业衡量。每个作业在某种程度上反映学生在多大程度上理解课程资料,但一个完整的作业清单任何招聘者来说都消化不了。幸运的是,你可以创造一个简易方法把所有分数平均在一起。靠这个大型的简化可以蒙混过关,因为在一项作业/课程表现突出的学生通常在其他作业/课程依然如此。通过使用学分绩点而不是整个清单,丰富性无疑会受到损失。 比如,你不会知道是否这学生更擅长数学/英文,以及是否她在编程家庭作业中比随堂测验表现更好。但却收获了简单,使得谈论和比较学生能力变得容易许多。
维度归约相关问题大多有关倾向于共同变化的因素。
1.直升机的哪些传感器倾向于共同(或不共同)变化?
2.成功的CEO有哪些共同的领导实践?
3.哪些是整个美国汽油价格变化的最常见模式?
4.这个文件集中哪些词组倾向于一同出现?(它们是有关什么主题?)
如果目标是总结、简化、压缩或提炼一些数据,要选用的工具就是维度归约和聚类。
我现在该做什么?
第三个机器学习算法家族重视采取行动。它们被称为增强学习(reinforcement learning)算法。回归算法能预测出明天的最高气温是37°C,但它无法决定对此做些什么。增强学习算法迈向下一步并选择一种行为,如,趁天气还凉爽提前为办公楼高层降温。
增强学习的灵感最早来源于老鼠和人类大脑如何对奖惩做出反应。它们采取行动,努力获得能带来最高奖励的行为。你提供给它们一系列可能的选项。它们需要对于某个行为获得反馈,判断此行为是好或中性或大错特错。
通常增强学习算法很适合需要在无人类监督下做出许多小决策的自动化系统。电梯、供热、降温和灯光系统是不错的选择。增强学习最初是被开发用于控制机器人,以便所有东西能够自动,不管是侦察无人机还是真空吸尘器。增强学习回答的问题一贯关于该采取什么行为,尽管这行为通常是由机器执行。
1.我该把这则广告放置在网页什么位置,以使浏览者最大可能打开它?
2.我是该把温度调高、调低还是维持现状?
3.我是该在打扫一遍起居室还是继续充电?
4.我现在该买多少股这个股票?
5.面对黄灯,我是该继续以这个速度行驶还是刹车,或者加速?
增强学习通常需要比其他算法做更多努力,因为它与系统的其他部分紧密相连。这里的优势是多数增强学习算法可以在没有数据的情况下开始工作。它们在运行中收集数据,从尝试和错误中学习。
原文作者:Brandon Rohrer
翻译:数据工匠
原文链接:http://www.kdnuggets.com/2015/09/questions-data-science-can-answer.html

- 本文固定链接: https://zxbcw.cn/post/4762/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)