
2021
09-14
09-14
带你入门java雪花算法原理
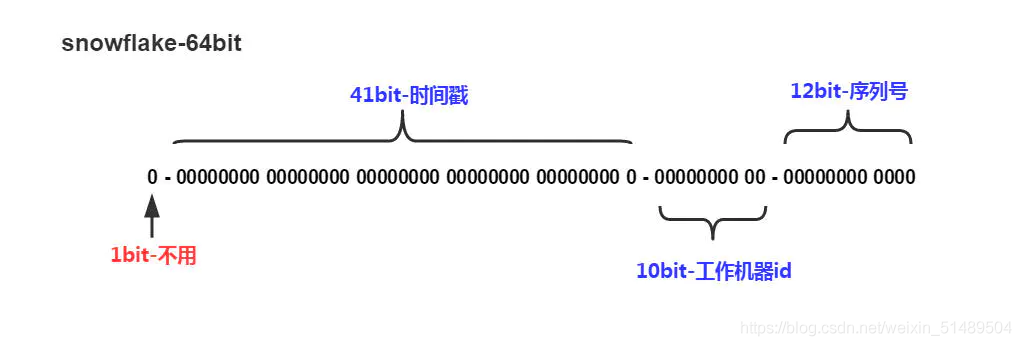 雪花算法(SnowFlake)雪花算法是Twitter开源的分布式ID生成算法.主要是由64bit的long型生成的全局ID,引入了时间戳和ID保持自增的属性.64bit分为四个部分:第一个部分是1bit,这不使用,没有意义;第二个部分是41bit,组成时间戳;第三个部分是10bit,工作机器ID,里面分为两个部分,5个bit是的是机房号,代表最多有25即32个机房,5个bit是指机器的ID,代表最多有25个机器,即32个机器.第四部分是12bit,代表是同一个毫秒类产生不同的ID,区分...
继续阅读 >
雪花算法(SnowFlake)雪花算法是Twitter开源的分布式ID生成算法.主要是由64bit的long型生成的全局ID,引入了时间戳和ID保持自增的属性.64bit分为四个部分:第一个部分是1bit,这不使用,没有意义;第二个部分是41bit,组成时间戳;第三个部分是10bit,工作机器ID,里面分为两个部分,5个bit是的是机房号,代表最多有25即32个机房,5个bit是指机器的ID,代表最多有25个机器,即32个机器.第四部分是12bit,代表是同一个毫秒类产生不同的ID,区分...
继续阅读 >
 SnowFlake算法,是Twitter开源的分布式id生成算法。其核心思想就是:使用一个64bit的long型的数字作为全局唯一id。在分布式系统中的应用十分广泛,且ID引入了时间戳,基本上保持自增的,后面的代码中有详细的注解。这64个bit中,其中1个bit是不用的,然后用其中的41bit作为毫秒数,用10bit作为工作机器id,12bit作为序列号。给大家举个例子吧,比如下面那个64bit的long型数字:第一个部分,...
SnowFlake算法,是Twitter开源的分布式id生成算法。其核心思想就是:使用一个64bit的long型的数字作为全局唯一id。在分布式系统中的应用十分广泛,且ID引入了时间戳,基本上保持自增的,后面的代码中有详细的注解。这64个bit中,其中1个bit是不用的,然后用其中的41bit作为毫秒数,用10bit作为工作机器id,12bit作为序列号。给大家举个例子吧,比如下面那个64bit的long型数字:第一个部分,...
 1、snowflake-id插件 importSnowflakeIdfrom"snowflake-id";constguid=num=>{constid=newSnowflakeId();returnid.generate();};2、原生使用 varSnowflake=/**@class*/(function(){functionSnowflake(_workerId,_dataCenterId,_sequence){this.twepoch=1288834974657n;//this.twepoch=0n;this.workerIdBits=5n;this.dataCenterIdBits=5n;this.maxWrokerId=-1n^(-1n<<t...
1、snowflake-id插件 importSnowflakeIdfrom"snowflake-id";constguid=num=>{constid=newSnowflakeId();returnid.generate();};2、原生使用 varSnowflake=/**@class*/(function(){functionSnowflake(_workerId,_dataCenterId,_sequence){this.twepoch=1288834974657n;//this.twepoch=0n;this.workerIdBits=5n;this.dataCenterIdBits=5n;this.maxWrokerId=-1n^(-1n<<t...
 一、为何要用雪花算法1、问题产生的背景现如今越来越多的公司都在用分布式、微服务,那么对应的就会针对不同的服务进行数据库拆分,然后当数据量上来的时候也会进行分表,那么随之而来的就是分表以后id的问题。例如之前单体项目中一个表中的数据主键id都是自增的,mysql是利用autoincrement来实现自增,而oracle是利用序列来实现的,但是当单表数据量上来以后就要进行水平分表,阿里java开发建议是单表大于500w的时候就要分表,但...
一、为何要用雪花算法1、问题产生的背景现如今越来越多的公司都在用分布式、微服务,那么对应的就会针对不同的服务进行数据库拆分,然后当数据量上来的时候也会进行分表,那么随之而来的就是分表以后id的问题。例如之前单体项目中一个表中的数据主键id都是自增的,mysql是利用autoincrement来实现自增,而oracle是利用序列来实现的,但是当单表数据量上来以后就要进行水平分表,阿里java开发建议是单表大于500w的时候就要分表,但...