
 目录pyspark操作hive表1>saveAsTable写入2>insertInto写入2.1>问题说明2.2>解决办法3>saveAsTextFile写入直接操作文件pyspark操作hive表pyspark操作hive表,hive分区表动态写入;最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约4:1。针对该问题整理了spark操作hive表的几种方式。1>saveAsTable写入saveAsTable(self,name,format=None,mode=None,partitionBy=None,**options)示例:df.w...
继续阅读 >
目录pyspark操作hive表1>saveAsTable写入2>insertInto写入2.1>问题说明2.2>解决办法3>saveAsTextFile写入直接操作文件pyspark操作hive表pyspark操作hive表,hive分区表动态写入;最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约4:1。针对该问题整理了spark操作hive表的几种方式。1>saveAsTable写入saveAsTable(self,name,format=None,mode=None,partitionBy=None,**options)示例:df.w...
继续阅读 >
分类:pyspark
目录pyspark操作hive表1>saveAsTable写入2>insertInto写入2.1>问题说明2.2>解决办法3>saveAsTextFile写入直接操作文件pyspark操作hive表pyspark操作hive表,hive分区表动态写入;最近发现spark动态写入hive分区,和saveAsTable存表方式相比,文件压缩比大约4:1。针对该问题整理了spark操作hive表的几种方式。1>saveAsTable写入saveAsTable(self,name,format=None,mode=None,partitionBy=None,**options)示例:df.w...
继续阅读 >
2021
07-04
07-04
pycharm利用pyspark远程连接spark集群的实现
 0背景由于工作需要,利用spark完成机器学习。因此需要对spark集群进行操作。所以利用pycharm和pyspark远程连接spark集群。这里记录下遇到的问题及方法。主要是参照下面的文献完成相应的内容,但是具体问题要具体分析。1方法1.1软件配置spark2.3.3,hadoop2.6,python31.2spark配置Spark集群的每个节点的Python版本必须保持一致。在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你的安装目录。exportPYSPARK_PYT...
继续阅读 >
0背景由于工作需要,利用spark完成机器学习。因此需要对spark集群进行操作。所以利用pycharm和pyspark远程连接spark集群。这里记录下遇到的问题及方法。主要是参照下面的文献完成相应的内容,但是具体问题要具体分析。1方法1.1软件配置spark2.3.3,hadoop2.6,python31.2spark配置Spark集群的每个节点的Python版本必须保持一致。在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你的安装目录。exportPYSPARK_PYT...
继续阅读 >
2020
12-30
12-30
pyspark对Mysql数据库进行读写的实现
 pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘。其中,数据的读写是基础操作,pyspark的子模块pyspark.sql可以完成大部分类型的数据读写。文本介绍在pyspark中读写Mysql数据库。1软件版本在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息。win1064bitjava13.0.1spark3.0python3.8pyspark3...
继续阅读 >
pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘。其中,数据的读写是基础操作,pyspark的子模块pyspark.sql可以完成大部分类型的数据读写。文本介绍在pyspark中读写Mysql数据库。1软件版本在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息。win1064bitjava13.0.1spark3.0python3.8pyspark3...
继续阅读 >
2020
10-06
10-06
在python中使用pyspark读写Hive数据操作
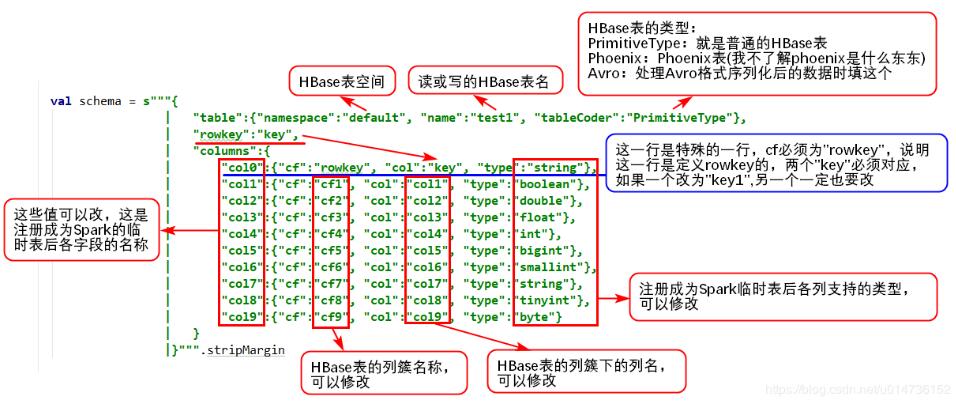 1、读Hive表数据pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下:frompyspark.sqlimportHiveContext,SparkSession_SPARK_HOST="spark://spark-master:7077"_APP_NAME="test"spark_session=SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()h...
继续阅读 >
1、读Hive表数据pyspark读取hive数据非常简单,因为它有专门的接口来读取,完全不需要像hbase那样,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL语句从hive里面查询需要的数据,代码如下:frompyspark.sqlimportHiveContext,SparkSession_SPARK_HOST="spark://spark-master:7077"_APP_NAME="test"spark_session=SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate()h...
继续阅读 >
2020
09-27
09-27
pyspark 随机森林的实现
 随机森林是由许多决策树构成,是一种有监督机器学习方法,可以用于分类和回归,通过合并汇总来自个体决策树的结果来进行预测,采用多数选票作为分类结果,采用预测结果平均值作为回归结果。“森林”的概念很好理解,“随机”是针对森林中的每一颗决策树,有两种含义:第一种随机是数据采样随机,构建决策树的训练数据集通过有放回的随机采样,并且只会选择一定百分比的样本,这样可以在数据集合存在噪声点、异常点的情况下,有些决...
继续阅读 >
随机森林是由许多决策树构成,是一种有监督机器学习方法,可以用于分类和回归,通过合并汇总来自个体决策树的结果来进行预测,采用多数选票作为分类结果,采用预测结果平均值作为回归结果。“森林”的概念很好理解,“随机”是针对森林中的每一颗决策树,有两种含义:第一种随机是数据采样随机,构建决策树的训练数据集通过有放回的随机采样,并且只会选择一定百分比的样本,这样可以在数据集合存在噪声点、异常点的情况下,有些决...
继续阅读 >
2020
09-27
09-27
pyspark给dataframe增加新的一列的实现示例
熟悉pandas的pythoner应该知道给dataframe增加一列很容易,直接以字典形式指定就好了,pyspark中就不同了,摸索了一下,可以使用如下方式增加frompysparkimportSparkContextfrompysparkimportSparkConffrompypsark.sqlimportSparkSessionfrompyspark.sqlimportfunctionsspark=SparkSession.builder.config(conf=SparkConf()).getOrCreate()data=[['Alice',19,'blue','["Alice",19,"blue"]'],['Jane',20...
继续阅读 >
2020
09-24
09-24
Pyspark获取并处理RDD数据代码实例
弹性分布式数据集(RDD)是一组不可变的JVM对象的分布集,可以用于执行高速运算,它是ApacheSpark的核心。在pyspark中获取和处理RDD数据集的方法如下:1.首先是导入库和环境配置(本测试在linux的pycharm上完成)importosfrompysparkimportSparkContext,SparkConffrompyspark.sql.sessionimportSparkSessionos.environ["PYSPARK_PYTHON"]="/usr/bin/python3"conf=SparkConf().setAppName('test_rdd')sc=SparkContext...
继续阅读 >
2020
09-24
09-24
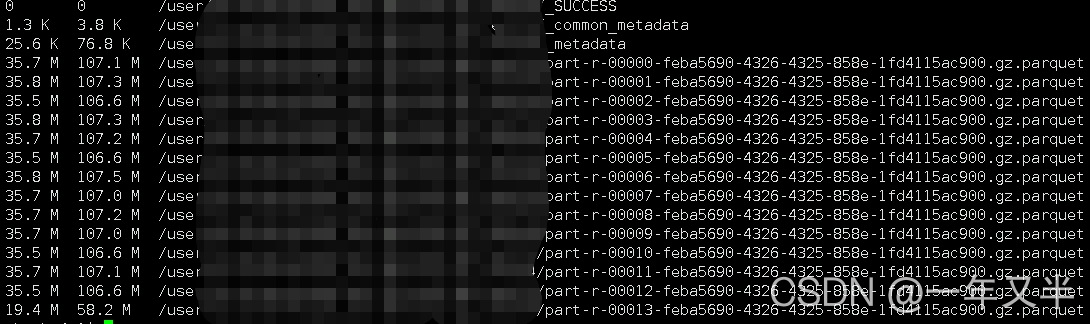
Pyspark读取parquet数据过程解析
 parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。首先,导入库文件和配置环境:importosfrompysparki...
继续阅读 >
parquet数据:列式存储结构,由Twitter和Cloudera合作开发,相比于行式存储,其特点是:可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量;压缩编码可以降低磁盘存储空间,使用更高效的压缩编码节约存储空间;只读取需要的列,支持向量运算,能够获取更好的扫描性能。那么我们怎么在pyspark中读取和使用parquet数据呢?我以local模式,linux下的pycharm执行作说明。首先,导入库文件和配置环境:importosfrompysparki...
继续阅读 >