
一、环境配置
安装Anaconda
具体安装过程,请点击本文
配置Pytorch
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision
二、数据集的准备
1.数据集的下载
kaggle网站的数据集下载地址:
https://www.kaggle.com/lizhensheng/-2000
2.数据集的分类
将下载的数据集进行解压操作,然后进行分类
分类如下(每个文件夹下包括cats和dogs文件夹)
三、猫狗分类的实例
导入相应的库
# 导入库 import torch.nn.functional as F import torch.optim as optim import torch import torch.nn as nn import torch.nn.parallel import torch.optim import torch.utils.data import torch.utils.data.distributed import torchvision.transforms as transforms import torchvision.datasets as datasets
设置超参数
# 设置超参数
#每次的个数
BATCH_SIZE = 20
#迭代次数
EPOCHS = 10
#采用cpu还是gpu进行计算
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
图像处理与图像增强
# 数据预处理
transform = transforms.Compose([
transforms.Resize(100),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(50),
transforms.RandomResizedCrop(150),
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
读取数据集和导入数据
# 读取数据
dataset_train = datasets.ImageFolder('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\train', transform)
print(dataset_train.imgs)
# 对应文件夹的label
print(dataset_train.class_to_idx)
dataset_test = datasets.ImageFolder('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\validation', transform)
# 对应文件夹的label
print(dataset_test.class_to_idx)
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=True)
定义网络模型
# 定义网络
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 64, 3)
self.conv4 = nn.Conv2d(64, 64, 3)
self.max_pool3 = nn.MaxPool2d(2)
self.conv5 = nn.Conv2d(64, 128, 3)
self.conv6 = nn.Conv2d(128, 128, 3)
self.max_pool4 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(4608, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.max_pool3(x)
x = self.conv5(x)
x = F.relu(x)
x = self.conv6(x)
x = F.relu(x)
x = self.max_pool4(x)
# 展开
x = x.view(in_size, -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
modellr = 1e-4
# 实例化模型并且移动到GPU
model = ConvNet().to(DEVICE)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.Adam(model.parameters(), lr=modellr)
调整学习率
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
modellrnew = modellr * (0.1 ** (epoch // 5))
print("lr:",modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew
定义训练过程
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device).float().unsqueeze(1)
optimizer.zero_grad()
output = model(data)
# print(output)
loss = F.binary_cross_entropy(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
# 定义测试过程
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device).float().unsqueeze(1)
output = model(data)
# print(output)
test_loss += F.binary_cross_entropy(output, target, reduction='mean').item()
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).to(device)
correct += pred.eq(target.long()).sum().item()
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
定义保存模型和训练
# 训练
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model, DEVICE, train_loader, optimizer, epoch)
val(model, DEVICE, test_loader)
torch.save(model, 'E:\\Cat_And_Dog\\kaggle\\model.pth')
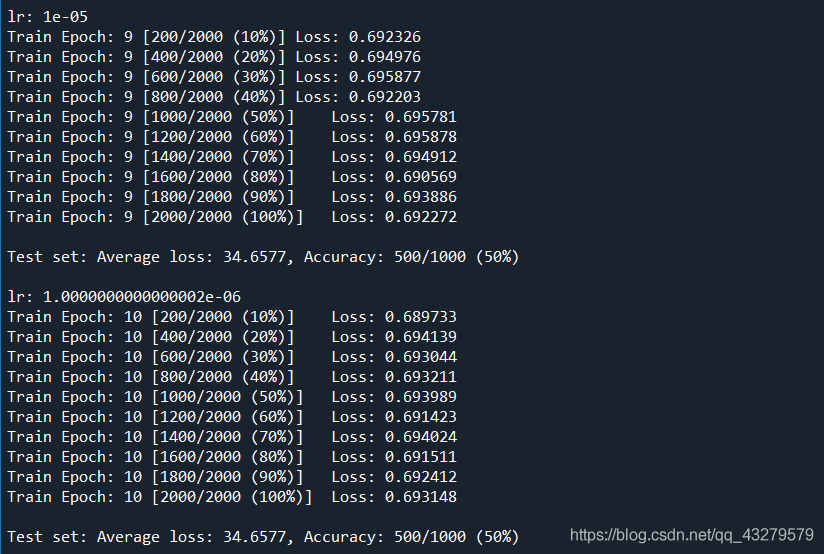
训练结果
四、实现分类预测测试
准备预测的图片进行测试
from __future__ import print_function, division
from PIL import Image
from torchvision import transforms
import torch.nn.functional as F
import torch
import torch.nn as nn
import torch.nn.parallel
# 定义网络
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.max_pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(32, 64, 3)
self.max_pool2 = nn.MaxPool2d(2)
self.conv3 = nn.Conv2d(64, 64, 3)
self.conv4 = nn.Conv2d(64, 64, 3)
self.max_pool3 = nn.MaxPool2d(2)
self.conv5 = nn.Conv2d(64, 128, 3)
self.conv6 = nn.Conv2d(128, 128, 3)
self.max_pool4 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(4608, 512)
self.fc2 = nn.Linear(512, 1)
def forward(self, x):
in_size = x.size(0)
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.max_pool3(x)
x = self.conv5(x)
x = F.relu(x)
x = self.conv6(x)
x = F.relu(x)
x = self.max_pool4(x)
# 展开
x = x.view(in_size, -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = torch.sigmoid(x)
return x
# 模型存储路径
model_save_path = 'E:\\Cat_And_Dog\\kaggle\\model.pth'
# ------------------------ 加载数据 --------------------------- #
# Data augmentation and normalization for training
# Just normalization for validation
# 定义预训练变换
# 数据预处理
transform_test = transforms.Compose([
transforms.Resize(100),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(50),
transforms.RandomResizedCrop(150),
transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
class_names = ['cat', 'dog'] # 这个顺序很重要,要和训练时候的类名顺序一致
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# ------------------------ 载入模型并且训练 --------------------------- #
model = torch.load(model_save_path)
model.eval()
# print(model)
image_PIL = Image.open('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\test\\cats\\cat.1500.jpg')
#
image_tensor = transform_test(image_PIL)
# 以下语句等效于 image_tensor = torch.unsqueeze(image_tensor, 0)
image_tensor.unsqueeze_(0)
# 没有这句话会报错
image_tensor = image_tensor.to(device)
out = model(image_tensor)
pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in out]).to(device)
print(class_names[pred])
预测结果


实际训练的过程来看,整体看准确度不高。而经过测试发现,该模型只能对于猫进行识别,对于狗则会误判。
五、参考资料
到此这篇关于Python机器学习之基于Pytorch实现猫狗分类的文章就介绍到这了,更多相关Pytorch实现猫狗分类内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/214392/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)