
CategoricalDtype自定义排序
当我们的透视表生成完毕后,有很多情况下需要我们对某列或某行值进行排序。排序有很多种方法。例如sort_index及sort_values函数也可以对数据进行排序,这里就不多说了。
对于数值和字母的排序很容易,但是对于中文的排序就有点麻烦了。默认情况下是按照utf-8的编码来进行排序的但是即使如此也很难满足我们对汉字排序的要求。所以通过CategoricalDtye可以把数据类型转成Category类型
然后通过指定参数列表的顺序来自定义那个元素先那个元素后,完全取决于你把那个元素放在List的前面,这样就大大方便了我们对中文排序的操作。
代码如下:
1. 自动生成DataFrame数据
#%%
import pandas as pd
from datetime import datetime
city =["上海","北京","深圳","杭州","苏州","青岛","大连","齐齐哈尔","大理","丽江",
"天津","济南","南京","广州","无锡","连云港","张家界"]
#创建自动从list中选取valuse值的get_list函数
#replace=True代表允许选出的元素重复
def get_list(items,size=20):
return pd.Series(items).sample(n=size,replace=True).to_list()
#通过get_list自动生成数据,最终生成一个DataFrame
df = pd.DataFrame({
"城市":get_list(city),
"仓位":get_list(["经济舱","商务舱","头等舱"]),
"航线":get_list(["单程","往返"]),
"日期": get_list([datetime(2020,8,1),datetime(2020,8,2),
datetime(2020,8,3),datetime(2020,8,4)]),
"时间": get_list(["09:00 - 12:00",
"13:00 - 15:30",
"06:30 - 15:00",
"18:00 - 21:00",
"20:00 - 23:20",
"10:00 - 15:00"]),
"航空公司": get_list(["东方航空","南方航空","深圳航空","山东航空","中国航空"]),
"出票数量":get_list([10,15,20,25,30,35,40,45,50,55,60]),
})
#%%
df
结果如下:
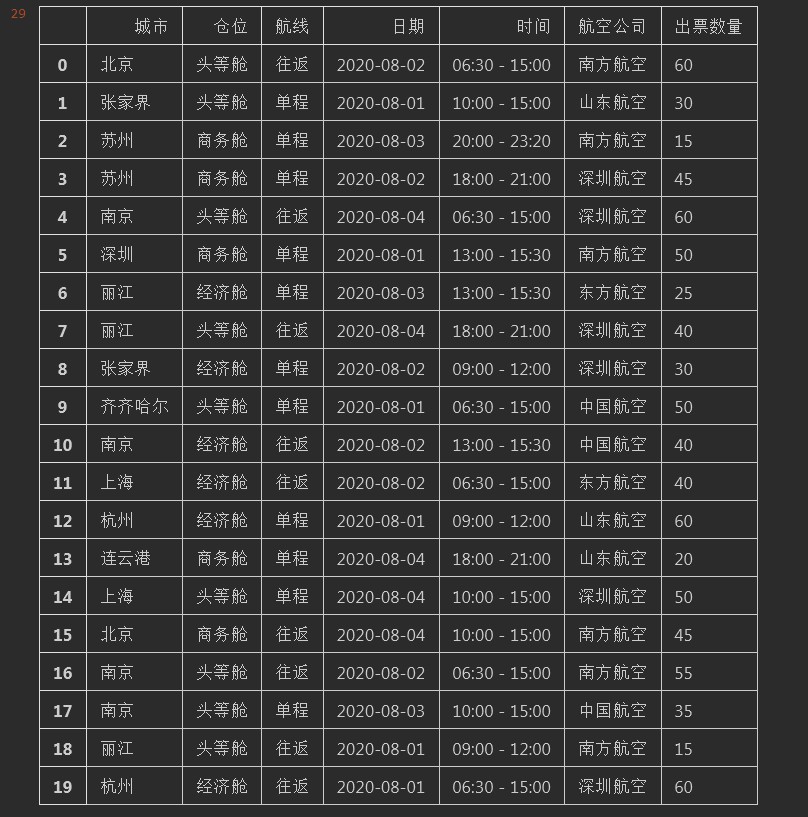
2. 查看数据类型
#%%
df.dtypes

3. 自定义数据类型(Category)按照指定顺序排序,并通过透视表展示数据
#%% #自定义type,以及自定义排序的顺序 my_type = pd.CategoricalDtype( categories=["头等舱","商务舱","经济舱"], ordered=True ) df["仓位"] = df["仓位"].astype(my_type) #将指定列转成自定义的type df.dtypes #%% #通过透视表统计数据 tb = pd.pivot_table( df, index=["城市","仓位","航线","日期","时间"], values="出票数量", aggfunc=sum ) tb
先查看数据类型:可以看出仓位的数据类型已经从Object变成了category类型了。
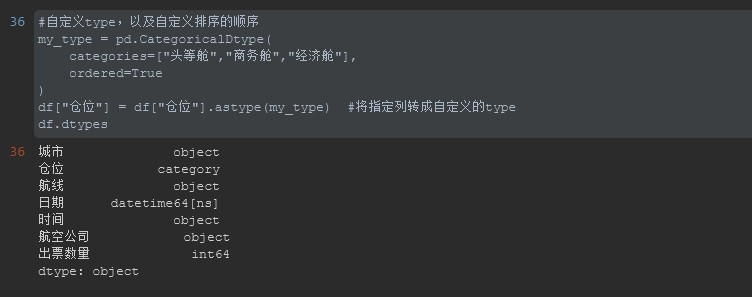
结果为:
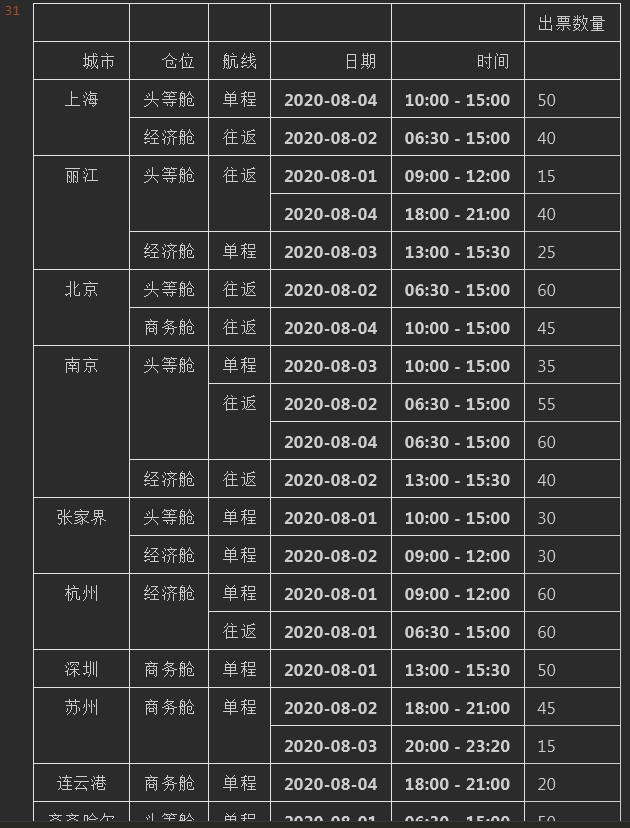
分析上述数据可以看出,我们把仓位按照["头等舱","商务舱","经济舱"]的顺序进行了排序,排序结果也是按照这个顺序排列的,成功的满足了我们对中文列自定义排序的需求。
通过Pivot_table函数更加清晰的对原有数据进行了展示。也可以按照自己的需求展示其中的一部分数据。这样对数据的清洗及展示变得更加的灵活。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/195471/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)