
(一)CSV格式文件
1.说明
CSV是一种以逗号分隔数值的文件类型,在数据库或电子表格中,常见的导入导出文件格式就是CSV格式,CSV格式存储数据通常以纯文本的方式存数数据表。
(二)CSV库操作csv格式文本
操作一下表格数据:

1.读取表头的2中方式
#方式一
import csv
with open("D:\\test.csv") as f:
reader = csv.reader(f)
rows=[row for row in reader]
print(rows[0])
----------
#方式二
import csv
with open("D:\\test.csv") as f:
#1.创建阅读器对象
reader = csv.reader(f)
#2.读取文件第一行数据
head_row=next(reader)
print(head_row)
结果演示:['姓名', '年龄', '职业', '家庭地址', '工资']
2.读取文件某一列数据
#1.获取文件某一列数据
import csv
with open("D:\\test.csv") as f:
reader = csv.reader(f)
column=[row[0] for row in reader]
print(column)
结果演示:['姓名', '张三', '李四', '王五', 'Kaina']
3.向csv文件中写入数据
#1.向csv文件中写入数据
import csv
with open("D:\\test.csv",'a') as f:
row=['曹操','23','学生','黑龙江','5000']
write=csv.writer(f)
write.writerow(row)
print("写入完毕!")
结果演示:
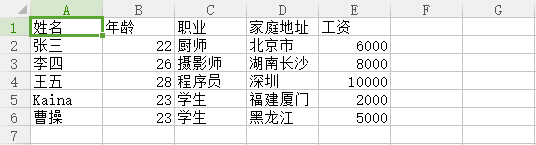
4.获取文件头及其索引
import csv
with open("D:\\test.csv") as f:
#1.创建阅读器对象
reader = csv.reader(f)
#2.读取文件第一行数据
head_row=next(reader)
print(head_row)
#4.获取文件头及其索引
for index,column_header in enumerate(head_row):
print(index,column_header)
结果演示:
['姓名', '年龄', '职业', '家庭地址', '工资']
0 姓名
1 年龄
2 职业
3 家庭地址
4 工资
5.获取某列的最大值
# ['姓名', '年龄', '职业', '家庭地址', '工资']
import csv
with open("D:\\test.csv") as f:
reader = csv.reader(f)
header_row=next(reader)
# print(header_row)
salary=[]
for row in reader:
#把第五列数据保存到列表salary中
salary.append(int(row[4]))
print(salary)
print("员工最高工资为:"+str(max(salary)))
结果演示:员工最高工资为:10000
6.复制CSV格式文件
原文件test.csv
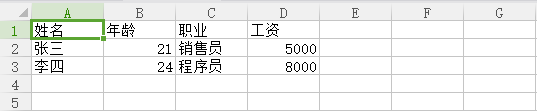
import csv
f=open('test.csv')
#1.newline=''消除空格行
aim_file=open('Aim.csv','w',newline='')
write=csv.writer(aim_file)
reader=csv.reader(f)
rows=[row for row in reader]
#2.遍历rows列表
for row in rows:
#3.把每一行写到Aim.csv中
write.writerow(row)
01.未添加关键字参数newline=' '的结果:
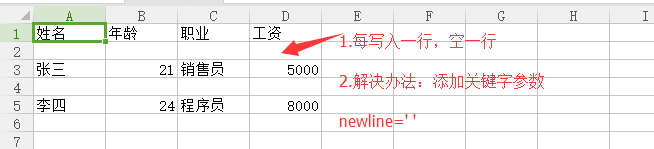
02添加关键字参数newline=' '的Aim.csv文件的内容:
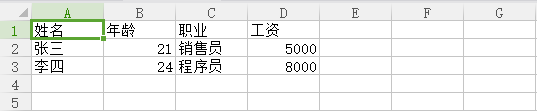
(三)pandas库操作CSV文件
csv文件内容:
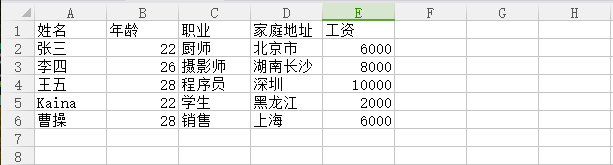
1.安装pandas库:pip install pandas
2.读取csv文件所有数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
print(data)
结果演示:
姓名 年龄 职业 家庭地址 工资
0 张三 22 厨师 北京市 6000
1 李四 26 摄影师 湖南长沙 8000
2 王五 28 程序员 深圳 10000
3 Kaina 22 学生 黑龙江 2000
4 曹操 28 销售 上海 6000
3.describe()方法数据统计
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
#了解更多describe()知识,ctr+鼠标左键
print(data.describe())
结果演示:
年龄 工资
count 5.00000 5.000000
mean 25.20000 6400.000000
std 3.03315 2966.479395
min 22.00000 2000.000000
25% 22.00000 6000.000000
50% 26.00000 6000.000000
75% 28.00000 8000.000000
max 28.00000 10000.000000
4.读取文件前几行数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
#读取前2行数据
# head_datas = data.head(0)
head_datas=data.head(2)
print(head_datas)
结果演示:
姓名 年龄 职业 家庭地址 工资
0 张三 22 厨师 北京市 6000
1 李四 26 摄影师 湖南长沙 8000
5.读取某一行所有数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
#读取第一行所有数据
print(data.ix[0,])
结果演示:
姓名 张三
年龄 22
职业 厨师
家庭地址 北京市
工资 6000
6.读取某几行的数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
#读取第一行、第二行、第四行的所有数据
print(data.ix[[0,1,3],:])
结果演示:
姓名 年龄 职业 家庭地址 工资
0 张三 22 厨师 北京市 6000
1 李四 26 摄影师 湖南长沙 8000
3 Kaina 22 学生 黑龙江 2000
7.读取所有行和列数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
#读取所有行和列数据
print(data.ix[:,:])
结果演示:
姓名 年龄 职业 家庭地址 工资
0 张三 22 厨师 北京市 6000
1 李四 26 摄影师 湖南长沙 8000
2 王五 28 程序员 深圳 10000
3 Kaina 22 学生 黑龙江 2000
4 曹操 28 销售 上海 6000
8.读取某一列的所有行数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
# print(data.ix[:, 4])
print(data.ix[:,'工资'])
结果演示:
0 6000
1 8000
2 10000
3 2000
4 6000
Name: 工资, dtype: int64
9.读取某几列的某几行
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
print(data.ix[[0,1,3],['姓名','职业','工资']])
结果演示:
姓名 职业 工资
0 张三 厨师 6000
1 李四 摄影师 8000
3 Kaina 学生 2000
10.读取某一行和某一列对应的数据
import pandas as pd
path= 'D:\\test.csv'
with open(path)as file:
data=pd.read_csv(file)
#读取第三行的第三列
print("职业---"+data.ix[2,2])
结果演示:职业---程序员
11.CSV数据的导入导出(复制CSV文件)
读方式01:
import pandas as pd #1.读入数据 data=pd.read_csv(file)
写出数据02:
import pandas as pd
#1.写出数据,目标文件是Aim.csv
data.to_csv('Aim.csv')
其他:
01.读取网络数据: import pandas as pd data_url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/tips.csv" #填写url读取 df = pd.read_csv(data_url) ---------- 02.读取excel文件数据 import pandas as pd data = pd.read_excel(filepath)
实例演示:
1.test.csv原文件内容
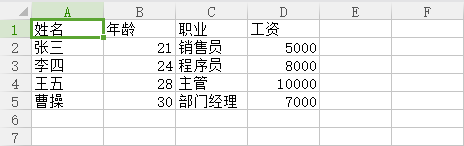
2.现在把test.csv中的内容复制到Aim.csv中
import pandas as pd
file=open('test.csv')
#1.读取file中的数据
data=pd.read_csv(file)
#2.把data写到目标文件Aim.csv中
data.to_csv('Aim.csv')
print(data)
结果演示:
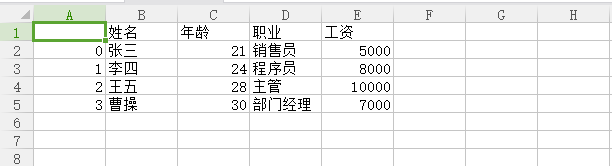
注:pandas模块处理Excel文件和处理CSV文件差不多!
参考文档:https://docs.python.org/3.6/library/csv.html
总结
到此这篇关于Python操作CSV格式文件的文章就介绍到这了,更多相关Python操作CSV文件内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/217415/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)