
2021
05-26
05-26
Python机器学习之Kmeans基础算法
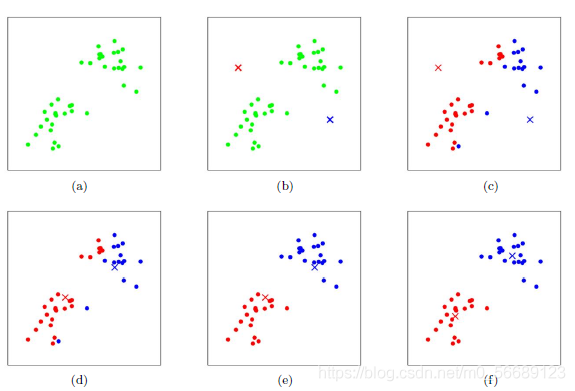 一、K-means基础算法简介k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。二、算法过程K-means中心思想:事先确定常数K,常数K意味着最终的聚类(或者叫簇)类别数,首先随机选定初始...
继续阅读 >
一、K-means基础算法简介k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。二、算法过程K-means中心思想:事先确定常数K,常数K意味着最终的聚类(或者叫簇)类别数,首先随机选定初始...
继续阅读 >
 手写数字识别算法importpandasaspdimportnumpyasnpfromsklearn.neural_networkimportMLPRegressor#从sklearn的神经网络中引入多层感知器data_tr=pd.read_csv('BPdata_tr.txt')#训练集样本data_te=pd.read_csv('BPdata_te.txt')#测试集样本X=np.array([[0.568928884039633],[0.379569493792951]]).reshape(1,-1)#预测单个样本#参数:hidden_layer_sizes中间层的个数activation激活函数默认reluf(x)=ma...
手写数字识别算法importpandasaspdimportnumpyasnpfromsklearn.neural_networkimportMLPRegressor#从sklearn的神经网络中引入多层感知器data_tr=pd.read_csv('BPdata_tr.txt')#训练集样本data_te=pd.read_csv('BPdata_te.txt')#测试集样本X=np.array([[0.568928884039633],[0.379569493792951]]).reshape(1,-1)#预测单个样本#参数:hidden_layer_sizes中间层的个数activation激活函数默认reluf(x)=ma...
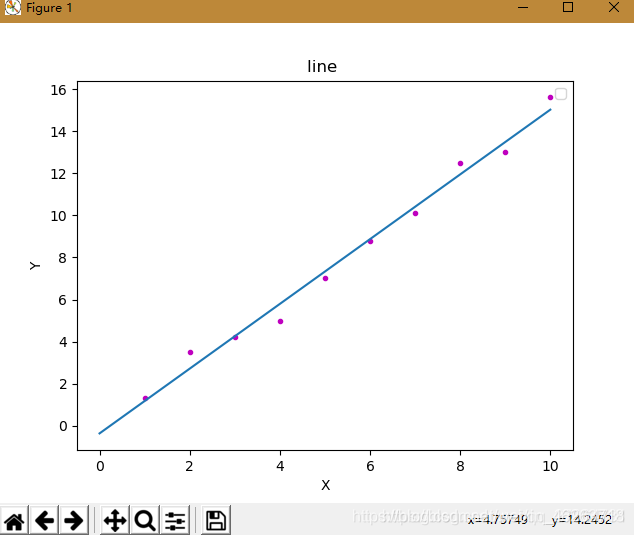 一、python机器学习?线性回归线性回归是最简单的机器学习模型,其形式简单,易于实现,同时也是很多机器学习模型的基础。对于一个给定的训练集数据,线性回归的目的就是找到一个与这些数据最吻合的线性函数。二、OLS线性回归2.1OrdinaryLeastSquares最小二乘法一般情况下,线性回归假设模型为下,其中w为模型参数线性回归模型通常使用MSE(均方误差)作为损失函数,假设有m个样本,均方损失函数为:(所有实例预测值与实际值误...
一、python机器学习?线性回归线性回归是最简单的机器学习模型,其形式简单,易于实现,同时也是很多机器学习模型的基础。对于一个给定的训练集数据,线性回归的目的就是找到一个与这些数据最吻合的线性函数。二、OLS线性回归2.1OrdinaryLeastSquares最小二乘法一般情况下,线性回归假设模型为下,其中w为模型参数线性回归模型通常使用MSE(均方误差)作为损失函数,假设有m个样本,均方损失函数为:(所有实例预测值与实际值误...