
 如下:将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parsertmp_soup.select里面的参数为:div标签中class中带有listbg下面span标签中带有title,这种意思:并且他们的类型如下:都是ResultSet类型。可以通过下面这种方式获取,find('某个标签')['中包含的域']当为li标签的时候,可以通过这样的方式获取:到此这篇关于PythonBeautifulSoup基本用法(通过标签及class定位元素)的文章就介绍到这了,更多相关PythonBea...
继续阅读 >
如下:将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parsertmp_soup.select里面的参数为:div标签中class中带有listbg下面span标签中带有title,这种意思:并且他们的类型如下:都是ResultSet类型。可以通过下面这种方式获取,find('某个标签')['中包含的域']当为li标签的时候,可以通过这样的方式获取:到此这篇关于PythonBeautifulSoup基本用法(通过标签及class定位元素)的文章就介绍到这了,更多相关PythonBea...
继续阅读 >
分类:beautifulsoup
如下:将html文件下载后,使用BeauifulSoup读取文件,并且使用html.parsertmp_soup.select里面的参数为:div标签中class中带有listbg下面span标签中带有title,这种意思:并且他们的类型如下:都是ResultSet类型。可以通过下面这种方式获取,find('某个标签')['中包含的域']当为li标签的时候,可以通过这样的方式获取:到此这篇关于PythonBeautifulSoup基本用法(通过标签及class定位元素)的文章就介绍到这了,更多相关PythonBea...
继续阅读 >
2021
02-21
02-21
使用Python爬取小姐姐图片(beautifulsoup法)
 Python有许多强大的库用于爬虫,如beautifulsoup、requests等,本文将以网站https://www.xiurenji.cc/XiuRen/为例(慎点!!),讲解网络爬取图片的一般步骤。为什么选择这个网站?其实与网站的内容无关。主要有两项技术层面的原因:①该网站的页面构造较有规律,适合新手对爬虫的技巧加强认识。②该网站没有反爬虫机制,可以放心使用爬虫。第三方库需求 beautifulsouprequests 步骤打开网站,点击不同的页面:发现...
继续阅读 >
Python有许多强大的库用于爬虫,如beautifulsoup、requests等,本文将以网站https://www.xiurenji.cc/XiuRen/为例(慎点!!),讲解网络爬取图片的一般步骤。为什么选择这个网站?其实与网站的内容无关。主要有两项技术层面的原因:①该网站的页面构造较有规律,适合新手对爬虫的技巧加强认识。②该网站没有反爬虫机制,可以放心使用爬虫。第三方库需求 beautifulsouprequests 步骤打开网站,点击不同的页面:发现...
继续阅读 >
2020
12-17
12-17
python BeautifulSoup库的安装与使用
1.BeautifulSoup简介BeautifulSoup4和lxml一样,BeautifulSoup也是一个HTML/XML的解析器,主要的功能也是如何解析和提取HTML/XML数据。BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则Python会使用Python默认的解析器,lxml解析器更加强大,速度更快,推荐使用lxml解析器。BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方...
继续阅读 >
2020
12-07
12-07
详解BeautifulSoup获取特定标签下内容的方法
以下是个人在学习beautifulSoup过程中的一些总结,目前我在使用爬虫数据时使用的方法的是:先用find_all()找出需要内容所在的标签,如果所需内容一个find_all()不能满足,那就用两个或者多个。接下来遍历find_all的结果,用get_txt()、get(‘href')、得到文本或者链接,然后放入各自的列表中。这样做有一个缺点就是txt的数据是一个单独的列表,链接的数据也是一个单独的列表,一方面不能体现这些数据之间的结构性,另一方面当想...
继续阅读 >
Selenium爬虫遇到数据是以JSON字符串的形式包裹在Script标签中,假设Script标签下代码如下:<scriptid="DATA_INFO"type="application/json">{"user":{"isLogin":true,"userInfo":{"id":123456,"nickname":"LiMing","intro":"人生苦短,我用python"}}}</script>此时drive.find_elements_by_xpath('//*[@id="DATA_INFO"]只能定位到元素,但是无法通过.text方法,获取Script标签下...
继续阅读 >
2020
12-07
12-07
Python中BeautifulSoup通过查找Id获取元素信息
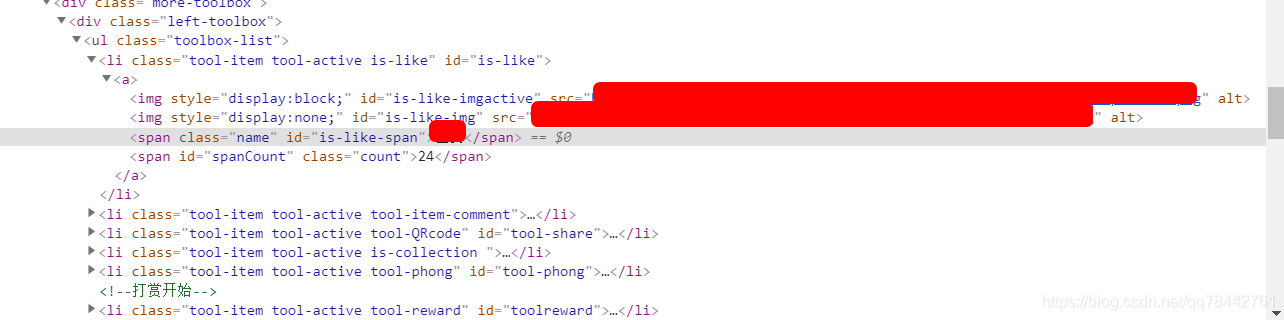 比如如下的html他是在span标签下的class为name,id为is-like-span这样就可以通过这样的代码进行方法:isCliked=soup.find('span',id='is-like-span'通过这种方式去获取即可,如果里面的为字符串则调用get_text()即可到此这篇关于Python中BeautifulSoup通过查找Id获取元素信息的文章就介绍到这了,更多相关BeautifulSoupId获取元素信息内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网...
继续阅读 >
比如如下的html他是在span标签下的class为name,id为is-like-span这样就可以通过这样的代码进行方法:isCliked=soup.find('span',id='is-like-span'通过这种方式去获取即可,如果里面的为字符串则调用get_text()即可到此这篇关于Python中BeautifulSoup通过查找Id获取元素信息的文章就介绍到这了,更多相关BeautifulSoupId获取元素信息内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网...
继续阅读 >
2020
12-07
12-07
BeautifulSoup中find和find_all的使用详解
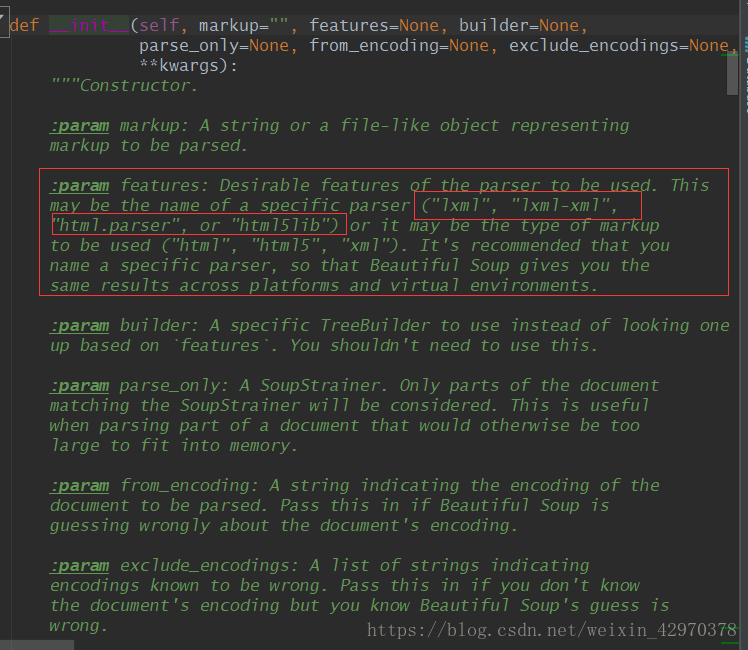 爬虫利器BeautifulSoup中find和find_all的使用方法二话不说,先上段HTML例子<html><head><title>index</title></head><body><div><ul><liid="flask"class="item-0"><ahref="link1.html"rel="externalnofollow"rel="externalnofollow"rel="externalnofollow"rel="externalnofollow"rel="externalnofollow">firstitem</a></li><liclass="item-1"><ahref="lin...
继续阅读 >
爬虫利器BeautifulSoup中find和find_all的使用方法二话不说,先上段HTML例子<html><head><title>index</title></head><body><div><ul><liid="flask"class="item-0"><ahref="link1.html"rel="externalnofollow"rel="externalnofollow"rel="externalnofollow"rel="externalnofollow"rel="externalnofollow">firstitem</a></li><liclass="item-1"><ahref="lin...
继续阅读 >
2020
10-01
10-01
Python基于BeautifulSoup爬取京东商品信息
今天小编利用美丽的汤来为大家演示一下如何实现京东商品信息的精准匹配~~HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;因此可以说BeautifulSoup库是解析、遍历、维护“标签树”的功能库。如何利用BeautifulSoup抓取京东网商品信息首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这...
继续阅读 >