
首先我们先用随机函数编造一个包含1000个数值的一维numpy数组,如下:
// An highlighted block rng = np.random.RandomState(seed=12345) samples = stats.norm.rvs(size=1000, random_state=rng)
接下来我们将使用各种方法画出以上数据的累积分布图
1、matplotlib.pyplot.hist()
def hist(self, x, bins=None, range=None, density=None, weights=None,
cumulative=False, bottom=None, histtype='bar', align='mid',
orientation='vertical', rwidth=None, log=False,
color=None, label=None, stacked=False, normed=None,
**kwargs):
第一种方法,我们使用matplotlib图形库中的hist函数,熟悉该库的人应该知道这是一个直方图绘制函数,以上是从API中找到的hist函数的所有参数,我们给出一维数组或者列表x,使用hist画出该数据的直方图。
直方图有两种形式,分别是概率分布直方图和累积分布直方图(可能说的不准确- -!),可以通过参数cucumulative来调节,默认为False,画出的是PDF,那么True画出的便是CDF直方图。
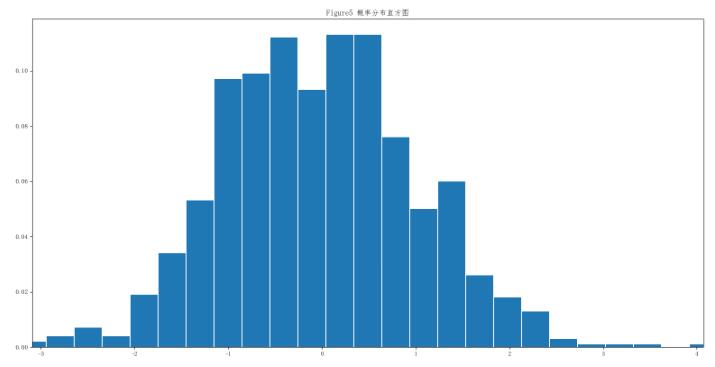
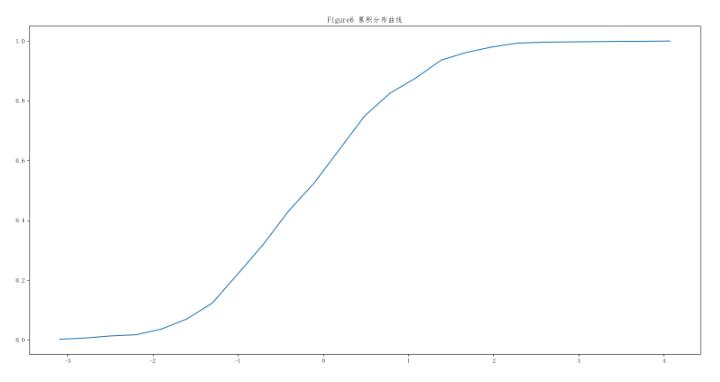
PDF(figure1)可以观察到整个数据在横轴范围内的分布,CDF(figure2)则可以看出不同的数据分布间的差异性,也可以观察到整个数据的增长趋势和波动情况。
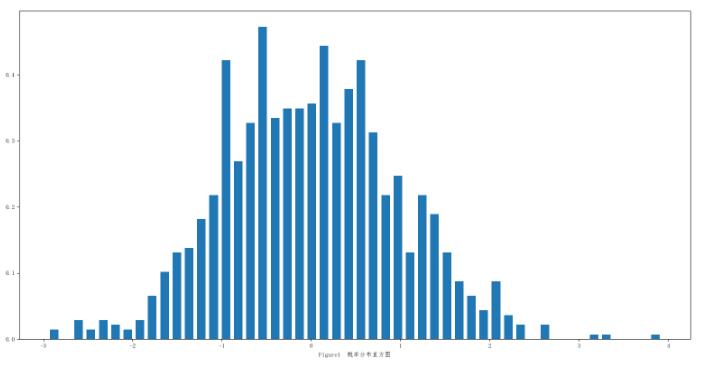
上图是概率分布直方图,纵轴代表概率,如果置参数normed=False,纵轴代表频数
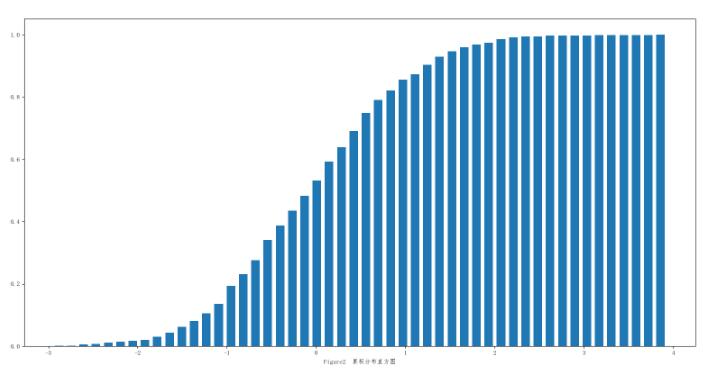
如果我们要观察两种数据分布的差异,可能使用直方图就不是很直观,各种直方柱会相互重叠,我们只需更改直方图的图像类型,令histtype=‘step',就会画出一条曲线来(Figure3,实际上就是将直方柱并在一起,除边界外颜色透明),类似于累积分布曲线。这时,我们就能很好地观察到不同数据分布曲线间的差异。
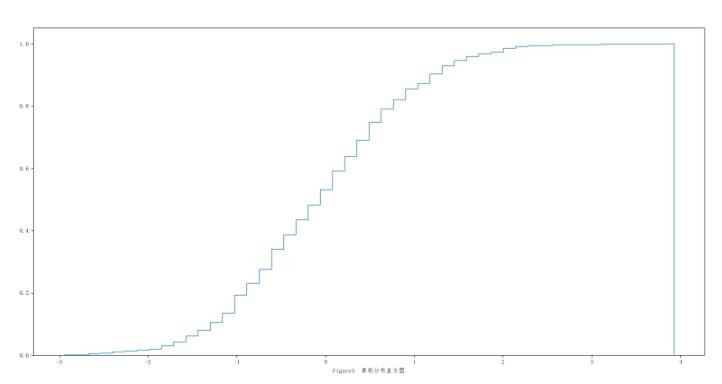
2、numpy.histogram
def histogram(a, bins=10, range=None, normed=False, weights=None,
density=None)
第二种方法我们使用numpy中画直方图的函数histogram,该函数不是一个直接的绘图函数(废话- -!过渡句,哈哈),给定一组数据a,它会返回两个数组hist和bin_edges,默认情况下hist是数据在各个区间上的频率,bin_edges是划分的各个区间的边界,说到这我们大概可以想到其实该函数算是上一个函数的底层函数,我们可以依据得到的这两个数组来画直方图,我们也可以用频率数组来直接画分布曲线(Figure4)
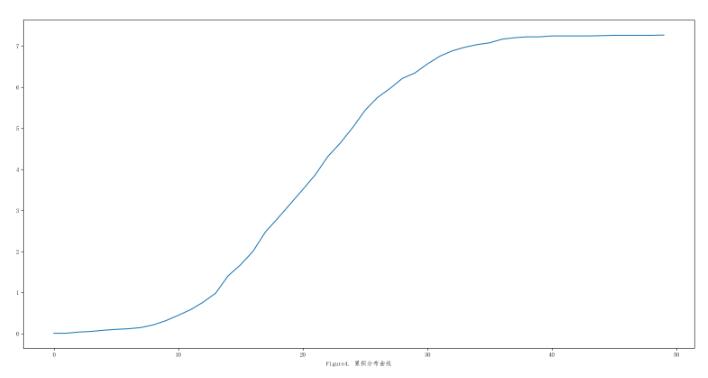
这里我只给出了一个最原始的图像,直接用hist数组画的,如果想要变成合格的累积分布曲线图,纵轴为概率(频率乘区间长度),横轴为区间(从bin_edges数组中取n-1个)就可以了
3、stats.relfreq
def relfreq(a, numbins=10, defaultreallimits=None, weights=None) Returns ------- frequency : ndarray Binned values of relative frequency. lowerlimit : float Lower real limit binsize : float Width of each bin. extrapoints : int Extra points.
第三种方法我们使用stats中的relfreq函数,该函数和第二种的方法类似,也并非是直接画图,而是返回关于直方图的一些数据,这里的frequency直接是概率而非频率,可以直接作为CDF图的纵轴,但是横轴需要自己计算,计算公式:
res.lowerlimit + np.linspace(0,res.binsize*res.frequency.size, res.frequency.size)
这个公式应该很好理解,我就不多说了,当然这些返回值都要依赖我们所给出的bins的数目。下面我给出一段代码,便是使用stats.relfreq画出概率分布直方图和累积分布曲线图。
rng = np.random.RandomState(seed=12345)
samples = stats.norm.rvs(size=1000, random_state=rng)
res = stats.relfreq(samples, numbins=25)
x = res.lowerlimit + np.linspace(0, res.binsize*res.frequency.size,res.frequency.size)
fig = plt.figure(figsize=(5, 4))
ax = fig.add_subplot(1, 1, 1)
ax.bar(x, res.frequency, width=res.binsize)
ax.set_title('Relative frequency histogram')
ax.set_xlim([x.min(), x.max()])
plt.show()
rng = np.random.RandomState(seed=12345)
samples = stats.norm.rvs(size=1000, random_state=rng)
res = stats.relfreq(samples, numbins=25)
x = res.lowerlimit + np.linspace(0, res.binsize*res.frequency.size,res.frequency.size)
y=np.cumsum(res.frequency)
plt.plot(x,y)
plt.title('Figure6 累积分布直方图')
plt.show()
以上就是本人整理出来的关于画cdf直方图和曲线的三种方法,整理这方面东西的初忠是在发现在进行数据分析的时候,概率分布直方图只能观察到数据大概的分布情况,而在不同的数据样本进行比较时却很难直观滴反映其差异性,通过看论文发现cdf可以做到这一点。
本人并不是数学专业出身,想要表达其意义,但有些描述和用词不当,大家借鉴就好。希望大家多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/181324/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)