
今天做了一个关于keras保存模型的实验,希望有助于大家了解keras保存模型的区别。
我们知道keras的模型一般保存为后缀名为h5的文件,比如final_model.h5。同样是h5文件用save()和save_weight()保存效果是不一样的。
我们用宇宙最通用的数据集MNIST来做这个实验,首先设计一个两层全连接网络:
inputs = Input(shape=(784, )) x = Dense(64, activation='relu')(inputs) x = Dense(64, activation='relu')(x) y = Dense(10, activation='softmax')(x) model = Model(inputs=inputs, outputs=y)
然后,导入MNIST数据训练,分别用两种方式保存模型,在这里我还把未训练的模型也保存下来,如下:
from keras.models import Model
from keras.layers import Input, Dense
from keras.datasets import mnist
from keras.utils import np_utils
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train=x_train.reshape(x_train.shape[0],-1)/255.0
x_test=x_test.reshape(x_test.shape[0],-1)/255.0
y_train=np_utils.to_categorical(y_train,num_classes=10)
y_test=np_utils.to_categorical(y_test,num_classes=10)
inputs = Input(shape=(784, ))
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
y = Dense(10, activation='softmax')(x)
model = Model(inputs=inputs, outputs=y)
model.save('m1.h5')
model.summary()
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=10)
#loss,accuracy=model.evaluate(x_test,y_test)
model.save('m2.h5')
model.save_weights('m3.h5')
如上可见,我一共保存了m1.h5, m2.h5, m3.h5 这三个h5文件。那么,我们来看看这三个玩意儿有什么区别。首先,看看大小:

m2表示save()保存的模型结果,它既保持了模型的图结构,又保存了模型的参数。所以它的size最大的。
m1表示save()保存的训练前的模型结果,它保存了模型的图结构,但应该没有保存模型的初始化参数,所以它的size要比m2小很多。
m3表示save_weights()保存的模型结果,它只保存了模型的参数,但并没有保存模型的图结构。所以它的size也要比m2小很多。
通过可视化工具,我们发现:(打开m1和m2均可以显示出以下结构)
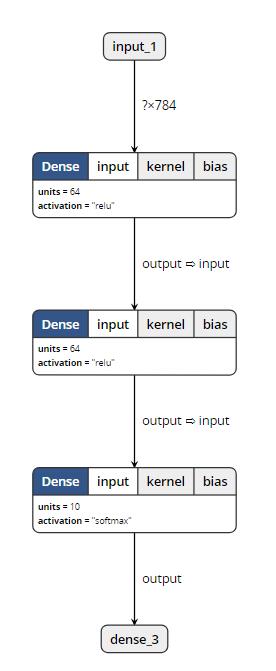
而打开m3的时候,可视化工具报错了。由此可以论证, save_weights()是不含有模型结构信息的。
加载模型
两种不同方法保存的模型文件也需要用不同的加载方法。
from keras.models import load_model
model = load_model('m1.h5')
#model = load_model('m2.h5')
#model = load_model('m3.h5')
model.summary()
只有加载m3.h5的时候,这段代码才会报错。其他输出如下:

可见,由save()保存下来的h5文件才可以直接通过load_model()打开!
那么,我们保存下来的参数(m3.h5)该怎么打开呢?
这就稍微复杂一点了,因为m3不含有模型结构信息,所以我们需要把模型结构再描述一遍才可以加载m3,如下:
from keras.models import Model
from keras.layers import Input, Dense
inputs = Input(shape=(784, ))
x = Dense(64, activation='relu')(inputs)
x = Dense(64, activation='relu')(x)
y = Dense(10, activation='softmax')(x)
model = Model(inputs=inputs, outputs=y)
model.load_weights('m3.h5')
以上把m3换成m1和m2也是没有问题的!可见,save()保存的模型除了占用内存大一点以外,其他的优点太明显了。所以,在不怎么缺硬盘空间的情况下,还是建议大家多用save()来存。
注意!如果要load_weights(),必须保证你描述的有参数计算结构与h5文件中完全一致!什么叫有参数计算结构呢?就是有参数坑,直接填进去就行了。我们把上面的非参数结构换了一下,发现h5文件依然可以加载成功,比如将softmax换成relu,依然不影响加载。
对于keras的save()和save_weights(),完全没问题了吧
以上这篇浅谈keras保存模型中的save()和save_weights()区别就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/187057/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)