
1 predict()方法
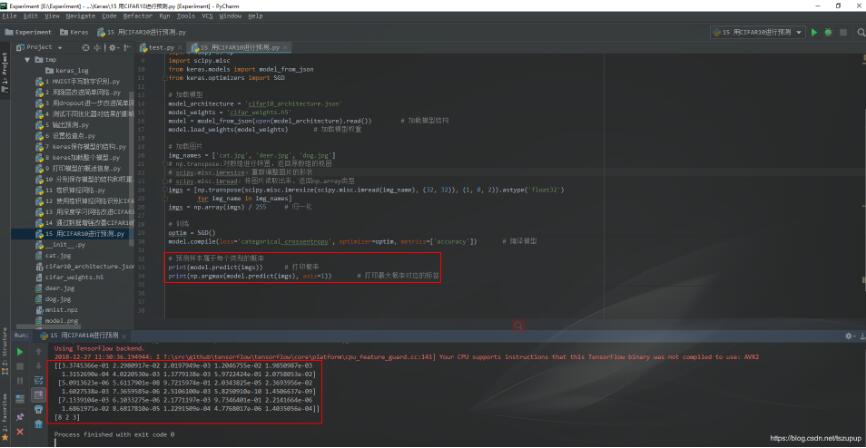
当使用predict()方法进行预测时,返回值是数值,表示样本属于每一个类别的概率,我们可以使用numpy.argmax()方法找到样本以最大概率所属的类别作为样本的预测标签。
2 predict_classes()方法
当使用predict_classes()方法进行预测时,返回的是类别的索引,即该样本所属的类别标签。以卷积神经网络中的图片分类为例说明,代码如下:

补充知识:keras中model.evaluate、model.predict和model.predict_classes的区别
1、model.evaluate 用于评估您训练的模型。它的输出是model的acc和loss,而不是对输入数据的预测。
2、model.predict 实际预测,输入为test sample,输出为label。
3、在keras中有两个预测函数model.predict_classes(test) 和model.predict(test)。如果标签经过了one-hot编码,如[1,2,3,4,5]是标签类别,经编码后为[1 0 0 0 0],[0 1 0 0 0]…[0 0 0 0 1]。
model.predict_classes(test)预测的是类别,打印出来的值就是类别号。并且只能用于序列模型来预测,不能用于函数式模型。
而model.predict(test)输出的还是5个编码值,要经过argmax(predict_test,axis=1)转化为类别号。
以上这篇对Keras中predict()方法和predict_classes()方法的区别说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/188353/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)