
详细的解释,读者自行打开这个链接查看,我这里只把最重要的说下
fit() 方法会返回一个训练期间历史数据记录对象,包含 training error, training accuracy, validation error, validation accuracy 字段,如下打印
# list all data in history
print(history.history.keys())
完整代码
# Visualize training history
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
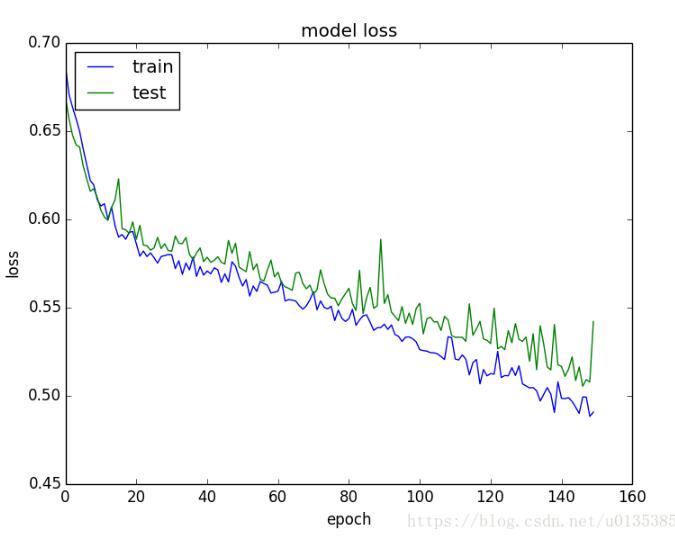
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
补充知识:训练时同时输出实时cost、准确率图
首先定义画图函数:
train_prompt = "Train cost" cost_ploter = Ploter(train_prompt) def event_handler_plot(ploter_title, step, cost): cost_ploter.append(ploter_title, step, cost) cost_ploter.plot()
在训练时如下方式使用:
EPOCH_NUM = 8
# 开始训练
lists = []
step = 0
for epochs in range(EPOCH_NUM):
# 开始训练
for batch_id, train_data in enumerate(train_reader()): #遍历train_reader的迭代器,并为数据加上索引batch_id
train_cost,sult,lab,vgg = exe.run(program=main_program, #运行主程序
feed=feeder.feed(train_data), #喂入一个batch的数据
fetch_list=[avg_cost,predict,label,VGG]) #fetch均方误差和准确率
if step % 10 == 0:
event_handler_plot(train_prompt,step,train_cost[0])
# print(batch_id)
if batch_id % 10 == 0: #每100次batch打印一次训练、进行一次测试
p = [np.sum(pre) for pre in sult]
l = [np.sum(pre) for pre in lab]
print(p,l,np.sum(sult),np.sum(lab))
print('Pass:%d, Batch:%d, Cost:%0.5f' % (epochs, batch_id, train_cost[0]))
step += 1
# 保存模型
if model_save_dir is not None:
fluid.io.save_inference_model(model_save_dir, ['images'], [predict], exe)
print('训练模型保存完成!')
end = time.time()
print(time.strftime('V100训练用时:%M分%S秒',time.localtime(end-start)))
实时显示准确率用同样的方法
以上这篇Keras在训练期间可视化训练误差和测试误差实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/188766/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)