
在一个比较好的数据集中,比如在分辨不同文字的任务中,一下是几个样本

使用VGG19,vol_acc和acc基本是同步保持增长的,比如
40/40 [==============================] - 23s 579ms/step - loss: 1.3896 - acc: 0.95 - val_loss: 1.3876 - val_acc: 0.95 Epoch 13/15 40/40 [==============================] - 23s 579ms/step - loss: 1.3829 - acc: 0.96 - val_loss: 1.3964 - val_acc: 0.96 Epoch 14/15 40/40 [==============================] - 23s 580ms/step - loss: 1.3844 - acc: 0.97 - val_loss: 1.3892 - val_acc: 0.97 Epoch 15/15 40/40 [==============================] - 24s 591ms/step - loss: 1.3833 - acc: 0.98 - val_loss: 1.4145 - val_acc: 0.98
这表明训练集和测试集同分布,在训练集中学习的特征确实可以应用到测试集中,这是最好的情况。
通过观察热力图也可以看到,最热的地方集中在特征上。比如在分辨不同的文字。
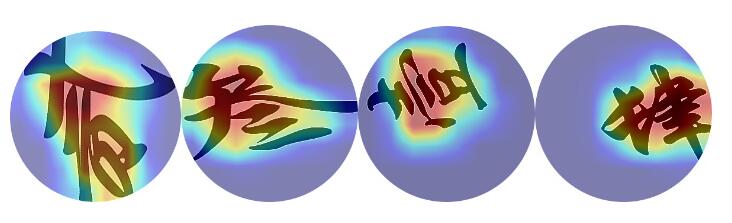
但很多时候,自己建立的数据集并不完美,或者可能不同类的特征分辨并不明显,这时候用cnn强行进行分类就会出现很多奇葩的情况。
考虑一种极端的情况,比如有四个类,而四个类都是同样的简单图形

那么在学习过程中,会出现如下特征的acc和vol_acc
40/40 [==============================] - 23s 579ms/step - loss: 1.3896 - acc: 0.2547 - val_loss: 1.3876 - val_acc: 0.2500 Epoch 13/15 40/40 [==============================] - 23s 579ms/step - loss: 1.3829 - acc: 0.2844 - val_loss: 1.3964 - val_acc: 0.2281 Epoch 14/15 40/40 [==============================] - 23s 580ms/step - loss: 1.3844 - acc: 0.2922 - val_loss: 1.3892 - val_acc: 0.2469 Epoch 15/15 40/40 [==============================] - 24s 591ms/step - loss: 1.3833 - acc: 0.2578 - val_loss: 1.4145 - val_acc: 0.2500
从热力图上看
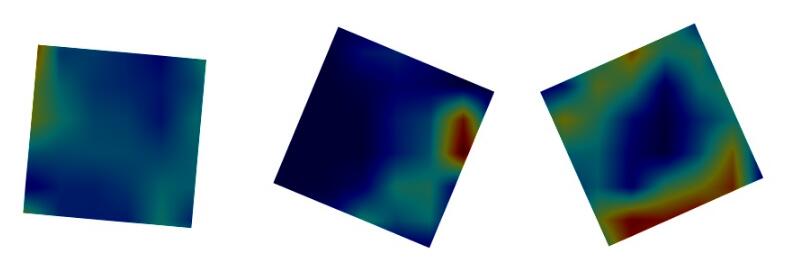
可以看到因为没有什么特征,所有热力图分布也没有规律,可以说网络什么都没学到。
那么考虑中间的情况,比如很相似的类学习会怎么样?比如不同年份的硬币

40/40 [==============================] - 25s 614ms/step - loss: 0.0967 - acc: 0.9891 - val_loss: 0.3692 - val_acc: 0.8313 40/40 [==============================] - 23s 580ms/step - loss: 0.0476 - acc: 0.9953 - val_loss: 0.3994 - val_acc: 0.7906 40/40 [==============================] - 23s 578ms/step - loss: 0.0237 - acc: 0.9984 - val_loss: 0.5067 - val_acc: 0.7344 40/40 [==============================] - 23s 579ms/step - loss: 0.0184 - acc: 1.0000 - val_loss: 0.5192 - val_acc: 0.7531 40/40 [==============================] - 23s 582ms/step - loss: 0.0286 - acc: 0.9953 - val_loss: 0.9653 - val_acc: 0.6344 40/40 [==============================] - 23s 584ms/step - loss: 0.0138 - acc: 1.0000 - val_loss: 0.4780 - val_acc: 0.7688 40/40 [==============================] - 23s 583ms/step - loss: 0.0115 - acc: 0.9984 - val_loss: 0.5485 - val_acc: 0.7438 40/40 [==============================] - 23s 581ms/step - loss: 0.0096 - acc: 1.0000 - val_loss: 0.5658 - val_acc: 0.7406 40/40 [==============================] - 23s 578ms/step - loss: 0.0046 - acc: 1.0000 - val_loss: 0.5070 - val_acc: 0.7562

可以看到,虽然网络有一定分辨力,但是学习的特征位置并不对,这可能是网络的分辨力有限,或者数据集过小导致的,具体怎么解决还没有想清楚??可以看到,可以看到除非完全没有特征,否则train acc一定能到100%,但是这个是事没有意义的,这就是过拟合。
一开始同步增长,是在学习特征,后来volacc和acc开始有差异,就是过拟合
这可能是训练集过小导致的,如果图片中只有年份呢?

acc = 0.85,vol_acc=0.85 acc = 0.90,vol_acc=0.90 acc = 0.92,vol_acc=0.92 acc = 0.94,vol_acc=0.92

可以看到,还是能正确分类的,之所以硬币不能正确分类,是因为训练数据集过小,其他特征掩盖了年份的特征,只要增大数据量就行了。
另外。还有几点训练技巧:
1、拓展函数不要怕极端,极端的拓展函数有利于学到目标真正的特征。
2、使用灰度图作为训练集?如果以纹理为主,使用灰度图,灰度图能增强网络的鲁棒性,因为可以减少光照的影响,但是会损失颜色信息,可以用结果看看到底该使用哪种图?
3、使用小的分辨率图片可能错过某些特征,尤其是在小数据集的时候,所以可能的话使用大数据集,或者提高分辨率,根据使用者的目标。
以上这篇浅谈keras使用中val_acc和acc值不同步的思考就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/188940/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)