
1、模型结果设计
2、代码
from keras import Input, Model
from keras.layers import Dense, Concatenate
import numpy as np
from keras.utils import plot_model
from numpy import random as rd
samples_n = 3000
samples_dim_01 = 2
samples_dim_02 = 2
# 样本数据
x1 = rd.rand(samples_n, samples_dim_01)
x2 = rd.rand(samples_n, samples_dim_02)
y_1 = []
y_2 = []
y_3 = []
for x11, x22 in zip(x1, x2):
y_1.append(np.sum(x11) + np.sum(x22))
y_2.append(np.max([np.max(x11), np.max(x22)]))
y_3.append(np.min([np.min(x11), np.min(x22)]))
y_1 = np.array(y_1)
y_1 = np.expand_dims(y_1, axis=1)
y_2 = np.array(y_2)
y_2 = np.expand_dims(y_2, axis=1)
y_3 = np.array(y_3)
y_3 = np.expand_dims(y_3, axis=1)
# 输入层
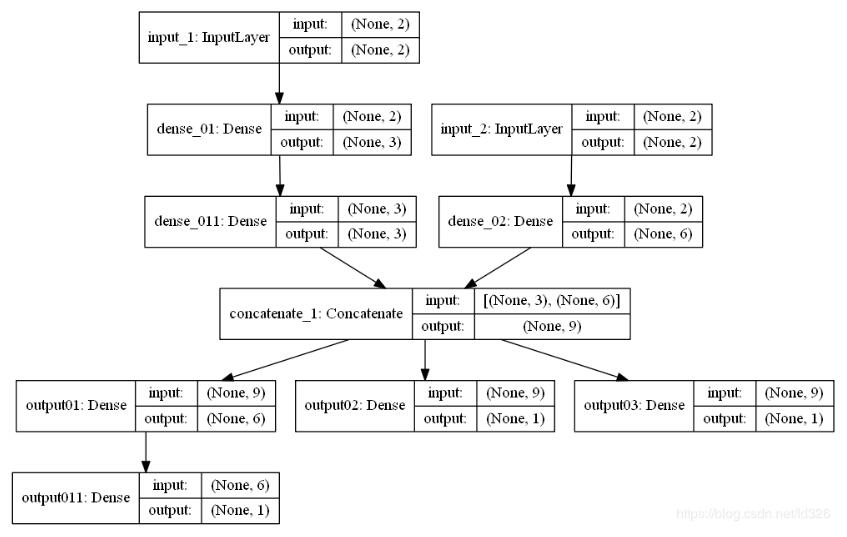
inputs_01 = Input((samples_dim_01,), name='input_1')
inputs_02 = Input((samples_dim_02,), name='input_2')
# 全连接层
dense_01 = Dense(units=3, name="dense_01", activation='softmax')(inputs_01)
dense_011 = Dense(units=3, name="dense_011", activation='softmax')(dense_01)
dense_02 = Dense(units=6, name="dense_02", activation='softmax')(inputs_02)
# 加入合并层
merge = Concatenate()([dense_011, dense_02])
# 分成两类输出 --- 输出01
output_01 = Dense(units=6, activation="relu", name='output01')(merge)
output_011 = Dense(units=1, activation=None, name='output011')(output_01)
# 分成两类输出 --- 输出02
output_02 = Dense(units=1, activation=None, name='output02')(merge)
# 分成两类输出 --- 输出03
output_03 = Dense(units=1, activation=None, name='output03')(merge)
# 构造一个新模型
model = Model(inputs=[inputs_01, inputs_02], outputs=[output_011,
output_02,
output_03
])
# 显示模型情况
plot_model(model, show_shapes=True)
print(model.summary())
# # 编译
# model.compile(optimizer="adam", loss='mean_squared_error', loss_weights=[1,
# 0.8,
# 0.8
# ])
# # 训练
# model.fit([x1, x2], [y_1,
# y_2,
# y_3
# ], epochs=50, batch_size=32, validation_split=0.1)
# 以下的方法可灵活设置
model.compile(optimizer='adam',
loss={'output011': 'mean_squared_error',
'output02': 'mean_squared_error',
'output03': 'mean_squared_error'},
loss_weights={'output011': 1,
'output02': 0.8,
'output03': 0.8})
model.fit({'input_1': x1,
'input_2': x2},
{'output011': y_1,
'output02': y_2,
'output03': y_3},
epochs=50, batch_size=32, validation_split=0.1)
# 预测
test_x1 = rd.rand(1, 2)
test_x2 = rd.rand(1, 2)
test_y = model.predict(x=[test_x1, test_x2])
# 测试
print("测试结果:")
print("test_x1:", test_x1, "test_x2:", test_x2, "y:", test_y, np.sum(test_x1) + np.sum(test_x2))
补充知识:Keras多输出(多任务)如何设置fit_generator
在使用Keras的时候,因为需要考虑到效率问题,需要修改fit_generator来适应多输出
# create model
model = Model(inputs=x_inp, outputs=[main_pred, aux_pred])
# complie model
model.compile(
optimizer=optimizers.Adam(lr=learning_rate),
loss={"main": weighted_binary_crossentropy(weights), "auxiliary":weighted_binary_crossentropy(weights)},
loss_weights={"main": 0.5, "auxiliary": 0.5},
metrics=[metrics.binary_accuracy],
)
# Train model
model.fit_generator(
train_gen, epochs=num_epochs, verbose=0, shuffle=True
)
generator: A generator or an instance of Sequence (keras.utils.Sequence) object in order to avoid duplicate data when using multiprocessing. The output of the generator must be either
a tuple (inputs, targets)
a tuple (inputs, targets, sample_weights).
Keras设计多输出(多任务)使用fit_generator的步骤如下:
根据官方文档,定义一个generator或者一个class继承Sequence
class Batch_generator(Sequence):
"""
用于产生batch_1, batch_2(记住是numpy.array格式转换)
"""
y_batch = {'main':batch_1,'auxiliary':batch_2}
return X_batch, y_batch
# or in another way
def batch_generator():
"""
用于产生batch_1, batch_2(记住是numpy.array格式转换)
"""
yield X_batch, {'main': batch_1,'auxiliary':batch_2}
重要的事情说三遍(亲自采坑,搜了一大圈才发现滴):
如果是多输出(多任务)的时候,这里的target是字典类型
如果是多输出(多任务)的时候,这里的target是字典类型
如果是多输出(多任务)的时候,这里的target是字典类型
以上这篇Keras-多输入多输出实例(多任务)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/189193/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)