
源码:
from pyecharts import Bar
import re
import requests
num=0
b=[]
for i in range(1,11):
link='https://www.cnblogs.com/echoDetected/default.html?page='+str(i)
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
r=requests.get(link,headers=headers)
html=r.text
post=re.findall('<span class="post-view-count">(.*?)</span>',html)
for i in post:
i = i.replace("阅读(", "")
i = i.replace(")","")
b.append(i)
num=num+1
columns=[]
for i in range(1,num+1):
#设置行名
columns.append('博客'+str(i))
#设置数据
#设置柱状图的主标题与副标题
bar = Bar("柱状图", "每个博客阅读数量")
#添加柱状图的数据及配置项,先行后列
bar.add("阅读量", columns, b, mark_line=["average"], mark_point=["max", "min"])
#生成本地文件(默认为.html文件)
bar.render()
爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点
这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客
pyecharts安装:
pip install wheelpip install pyecharts==0.1.9.4
直接pip install pyecharts会下载最新版无法调用
注意点:pyecharts调用,貌似无法实现多个py文件一起调用(意思是编写时不能在多个文件里出现import语句)
步骤解释:
1.爬虫爬取阅读数
2.去除非法字符装入新的数组
3.设置横轴数据,生成柱状图
4.在当前目录下生成render.html,打开查看柱状图
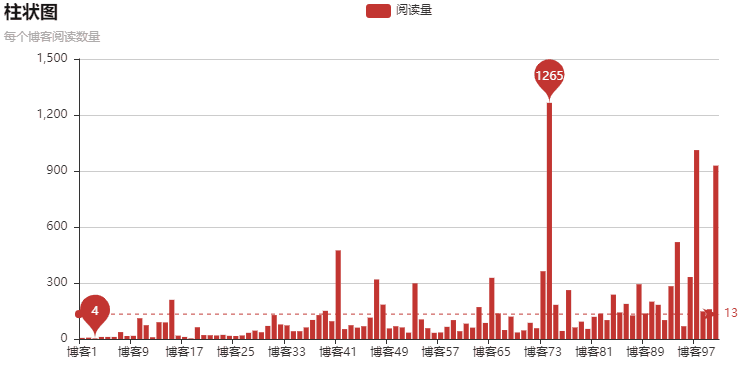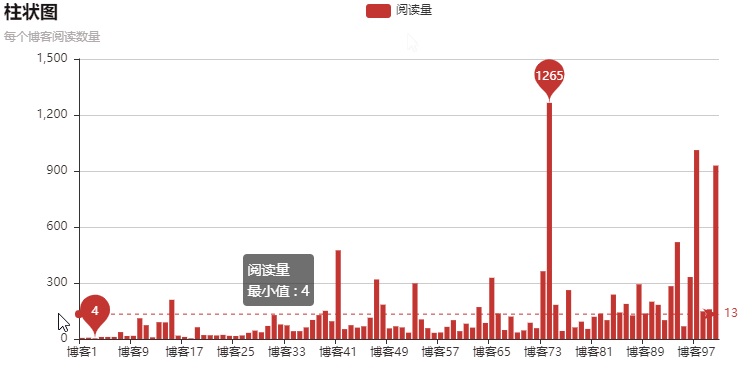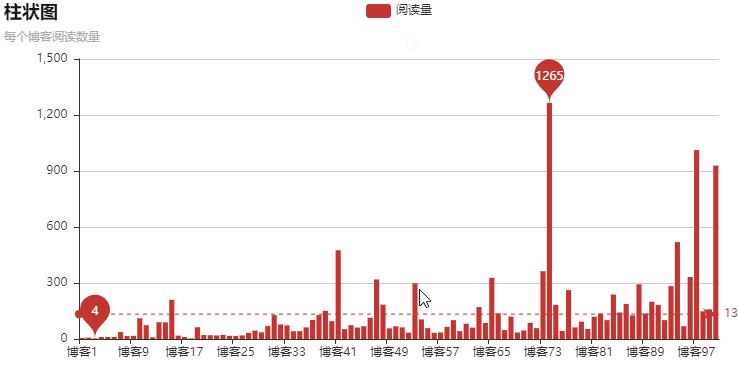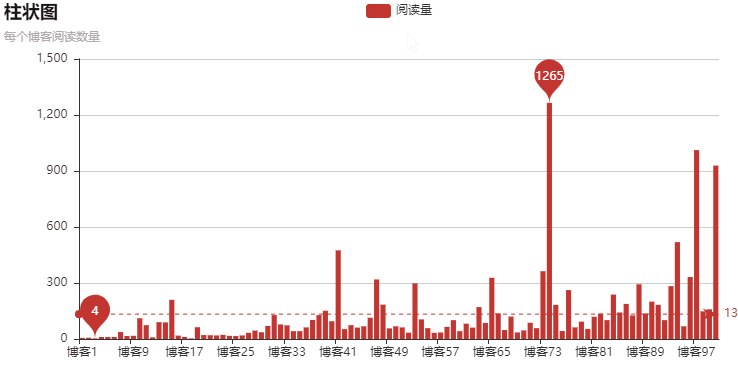
结果:
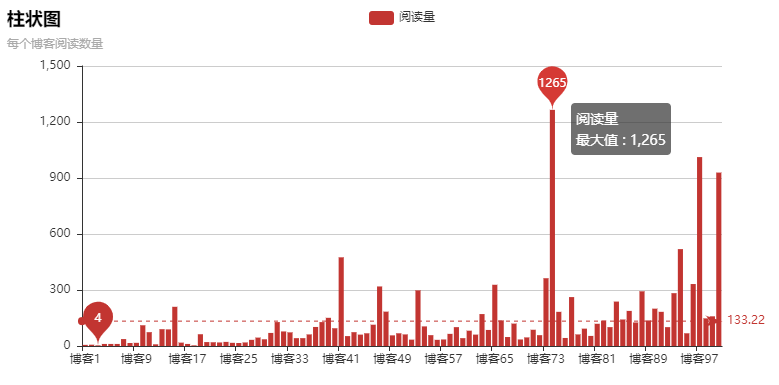
柱状图是动态的,不是静态的
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/189648/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)