
前言:随之vue3.0beta版本的发布,vue3.0正式版本相信不久就会与我们相遇。尤玉溪在直播中也说了vue3.0的新特性typescript强烈支持,proxy响应式原理,重新虚拟dom,优化diff算法性能提升等等。小编在这里仔细研究了vue3.0beta版本diff算法的源码,并希望把其中的细节和奥妙和大家一起分享。

首先我们来思考一些大中厂面试中,很容易问到的问题:
1 什么时候用到diff算法,diff算法作用域在哪里?
2 diff算法是怎么运作的,到底有什么作用?
3 在v-for 循环列表 key 的作用是什么
4 用索引index做key真的有用? 到底用什么做key才是最佳方案。
如果遇到这些问题,大家是怎么回答的呢?我相信当你读完这篇文章,这些问题也会迎刃而解。
一 什么时候用到了diff算法,diff算法作用域?
1.1diff算法的作用域
patch概念引入
在vue update过程中在遍历子代vnode的过程中,会用不同的patch方法来patch新老vnode,如果找到对应的 newVnode 和 oldVnode,就可以复用利用里面的真实dom节点。避免了重复创建元素带来的性能开销。毕竟浏览器创造真实的dom,操纵真实的dom,性能代价是昂贵的。
patch过程中,如果面对当前vnode存在有很多chidren的情况,那么需要分别遍历patch新的children Vnode和老的 children vnode。
存在chidren的vnode类型
首先思考一下什么类型的vnode会存在children。
①element元素类型vnode
第一中情况就是element类型vnode 会存在 children vode,此时的三个span标签就是chidren vnode情况
<div> <span> 苹果🍎 </span> <span> 香蕉🍌 </span> <span> 鸭梨🍐 </span> </div>
在vue3.0源码中 ,patchElement用于处理element类型的vnode ②flagment碎片类型vnode
在Vue3.0中,引入了一个fragment碎片概念。
你可能会问,什么是碎片?如果你创建一个Vue组件,那么它只能有一个根节点。
<template> <span> 苹果🍎 </span> <span> 香蕉🍌 </span> <span> 鸭梨🍐 </span> </template>
这样可能会报出警告,原因是代表任何Vue组件的Vue实例需要绑定到一个单一的DOM元素中。唯一可以创建一个具有多个DOM节点的组件的方法就是创建一个没有底层Vue实例的功能组件。
flagment出现就是用看起来像一个普通的DOM元素,但它是虚拟的,根本不会在DOM树中呈现。这样我们可以将组件功能绑定到一个单一的元素中,而不需要创建一个多余的DOM节点。
<Fragment> <span> 苹果🍎 </span> <span> 香蕉🍌 </span> <span> 鸭梨🍐 </span> </Fragment>
在vue3.0源码中 ,processFragment用于处理Fragment类型的vnode
1.2 patchChildren
从上文中我们得知了存在children的vnode类型,那么存在children就需要patch每一个
children vnode依次向下遍历。那么就需要一个patchChildren方法,依次patch子类vnode。
patchChildren
vue3.0中 在patchChildren方法中有这么一段源码
if (patchFlag > 0) {
if (patchFlag & PatchFlags.KEYED_FRAGMENT) {
/* 对于存在key的情况用于diff算法 */
patchKeyedChildren(
c1 as VNode[],
c2 as VNodeArrayChildren,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
return
} else if (patchFlag & PatchFlags.UNKEYED_FRAGMENT) {
/* 对于不存在key的情况,直接patch */
patchUnkeyedChildren(
c1 as VNode[],
c2 as VNodeArrayChildren,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
return
}
}
patchChildren根据是否存在key进行真正的diff或者直接patch。 既然diff算法存在patchChildren方法中,而patchChildren方法用在Fragment类型和element类型的vnode中,这样也就解释了diff算法的作用域是什么。 1.3 diff算法作用?
通过前言我们知道,存在这children的情况的vnode,需要通过patchChildren遍历children依次进行patch操作,如果在patch期间,再发现存在vnode情况,那么会递归的方式依次向下patch,那么找到与新的vnode对应的vnode显的如此重要。
我们用两幅图来向大家展示vnode变化。

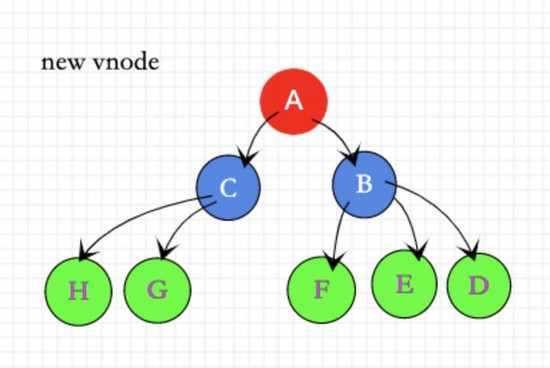
如上两幅图表示在一次更新中新老dom树变化情况。
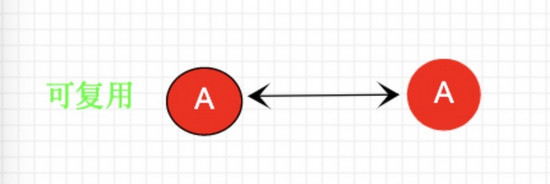
假设不存在diff算法,依次按照先后顺序patch会发生什么
如果 不存在diff算法 ,而是直接patchchildren 就会出现如下图的逻辑。

第一次patchChidren
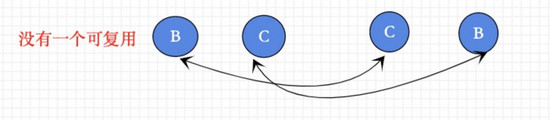
第二次patchChidren
第三次patchChidren‘
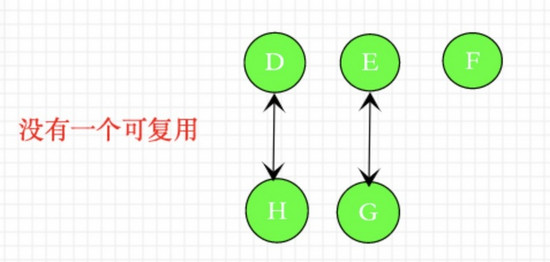
第四次patchChidren
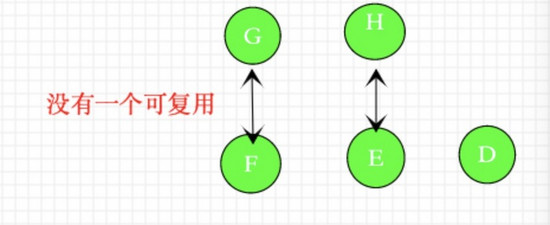
如果没有用到diff算法,而是依次patch虚拟dom树,那么如上稍微 修改dom顺序 ,就会在patch过程中没有一对正确的新老vnode,所以老vnode的节点没有一个可以复用,这样就需要重新创造新的节点,浪费了性能开销,这显然不是我们需要的。
那么diff算法的作用就来了。
diff作用就是在patch子vnode过程中,找到与新vnode对应的老vnode,复用真实的dom节点,避免不必要的性能开销
二 diff算法具体做了什么(重点)?
在正式讲diff算法之前,在patchChildren的过程中,存在 patchKeyedChildren
patchUnkeyedChildren
patchKeyedChildren 是正式的开启diff的流程,那么patchUnkeyedChildren的作用是什么呢? 我们来看看针对没有key的情况patchUnkeyedChildren会做什么。
c1 = c1 || EMPTY_ARR
c2 = c2 || EMPTY_ARR
const oldLength = c1.length
const newLength = c2.length
const commonLength = Math.min(oldLength, newLength)
let i
for (i = 0; i < commonLength; i++) { /* 依次遍历新老vnode进行patch */
const nextChild = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
patch(
c1[i],
nextChild,
container,
null,
parentComponent,
parentSuspense,
isSVG,
optimized
)
}
if (oldLength > newLength) { /* 老vnode 数量大于新的vnode,删除多余的节点 */
unmountChildren(c1, parentComponent, parentSuspense, true, commonLength)
} else { /* /* 老vnode 数量小于于新的vnode,创造新的即诶安 */
mountChildren(
c2,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized,
commonLength
)
}
我们可以得到结论,对于不存在key情况
① 比较新老children的length获取最小值 然后对于公共部分,进行从新patch工作。
② 如果老节点数量大于新的节点数量 ,移除多出来的节点。
③ 如果新的节点数量大于老节点的数量,从新 mountChildren新增的节点。
那么对于存在key情况呢? 会用到diff算法 , diff算法做了什么呢?
patchKeyedChildren方法究竟做了什么?
我们先来看看一些声明的变量。
/* c1 老的vnode c2 新的vnode */ let i = 0 /* 记录索引 */ const l2 = c2.length /* 新vnode的数量 */ let e1 = c1.length - 1 /* 老vnode 最后一个节点的索引 */ let e2 = l2 - 1 /* 新节点最后一个节点的索引 */
①第一步从头开始向尾寻找
(a b) c
(a b) d e
/* 从头对比找到有相同的节点 patch ,发现不同,立即跳出*/
while (i <= e1 && i <= e2) {
const n1 = c1[i]
const n2 = (c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i]))
/* 判断key ,type是否相等 */
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
} else {
break
}
i++
}
第一步的事情就是从头开始寻找相同的vnode,然后进行patch,如果发现不是相同的节点,那么立即跳出循环。
具体流程如图所示
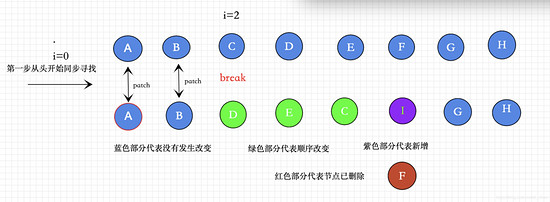
isSameVNodeType
export function isSameVNodeType(n1: VNode, n2: VNode): boolean {
return n1.type === n2.type && n1.key === n2.key
}
isSameVNodeType 作用就是判断当前vnode类型 和 vnode的 key是否相等
②第二步从尾开始同前diff
a (b c)
d e (b c)
/* 如果第一步没有patch完,立即,从后往前开始patch ,如果发现不同立即跳出循环 */
while (i <= e1 && i <= e2) {
const n1 = c1[e1]
const n2 = (c2[e2] = optimized
? cloneIfMounted(c2[e2] as VNode)
: normalizeVNode(c2[e2]))
if (isSameVNodeType(n1, n2)) {
patch(
n1,
n2,
container,
parentAnchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
} else {
break
}
e1--
e2--
}
经历第一步操作之后,如果发现没有patch完,那么立即进行第二部,从尾部开始遍历依次向前diff。
如果发现不是相同的节点,那么立即跳出循环。
具体流程如图所示
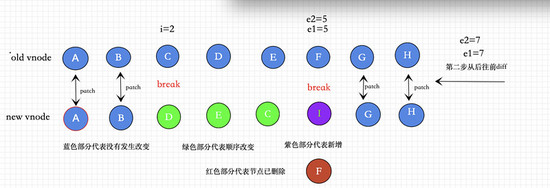
③④主要针对新增和删除元素的情况,前提是元素没有发生移动, 如果有元素发生移动就要走⑤逻辑。 ③ 如果老节点是否全部patch,新节点没有被patch完,创建新的vnode
(a b)
(a b) c
i = 2, e1 = 1, e2 = 2
(a b)
c (a b)
i = 0, e1 = -1, e2 = 0
/* 如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode ) */
if (i > e1) {
if (i <= e2) {
const nextPos = e2 + 1
const anchor = nextPos < l2 ? (c2[nextPos] as VNode).el : parentAnchor
while (i <= e2) {
patch( /* 创建新的节点*/
null,
(c2[i] = optimized
? cloneIfMounted(c2[i] as VNode)
: normalizeVNode(c2[i])),
container,
anchor,
parentComponent,
parentSuspense,
isSVG
)
i++
}
}
}
i > e1
如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode ),也就是要全部create新的vnode.
具体逻辑如图所示
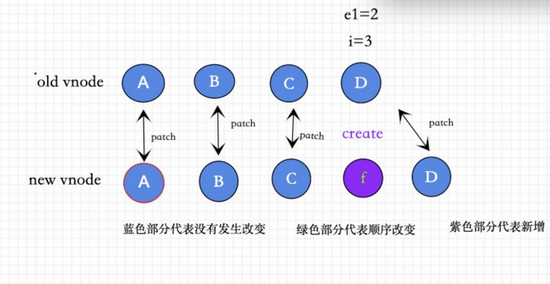
④ 如果新节点全部被patch,老节点有剩余,那么卸载所有老节点
i > e2
(a b) c
(a b)
i = 2, e1 = 2, e2 = 1
a (b c)
(b c)
i = 0, e1 = 0, e2 = -1
else if (i > e2) {
while (i <= e1) {
unmount(c1[i], parentComponent, parentSuspense, true)
i++
}
}
对于老的节点大于新的节点的情况 ,对于超出的节点全部卸载 ( 这种情况说明已经patch完相同的vnode )
具体逻辑如图所示
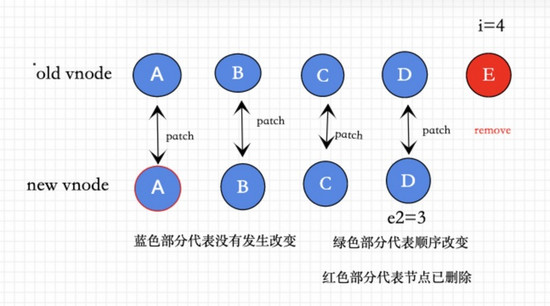
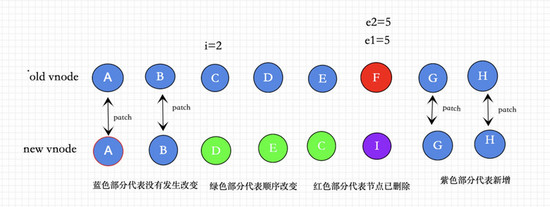
⑤ 不确定的元素 ( 这种情况说明没有patch完相同的vnode ),我们可以接着①②的逻辑继续往下看 diff核心
在①②情况下没有遍历完的节点如下图所示。
剩下的节点。
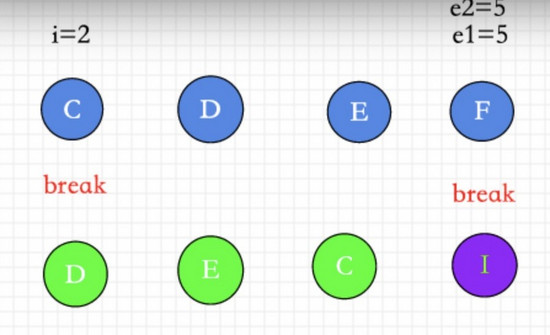
const s1 = i //第一步遍历到的index
const s2 = i
const keyToNewIndexMap: Map<string | number, number> = new Map()
/* 把没有比较过的新的vnode节点,通过map保存 */
for (i = s2; i <= e2; i++) {
if (nextChild.key != null) {
keyToNewIndexMap.set(nextChild.key, i)
}
}
let j
let patched = 0
const toBePatched = e2 - s2 + 1 /* 没有经过 path 新的节点的数量 */
let moved = false /* 证明是否 */
let maxNewIndexSoFar = 0
const newIndexToOldIndexMap = new Array(toBePatched)
for (i = 0; i < toBePatched; i++) newIndexToOldIndexMap[i] = 0
/* 建立一个数组,每个子元素都是0 [ 0, 0, 0, 0, 0, 0, ] */
遍历所有新节点把索引和对应的key,存入map keyToNewIndexMap中
keyToNewIndexMap存放 key -> index 的map
D : 2
E : 3
C : 4
I : 5
接下来声明一个新的指针 j ,记录剩下新的节点的索引。
patched,记录在第⑤步patched新节点过的数量
toBePatched记录⑤步之前,没有经过patched 新的节点的数量。
moved代表是否发生过移动,咱们的demo是已经发生过移动的。
newIndexToOldIndexMap用来存放新节点索引和老节点索引的数组。
newIndexToOldIndexMap 数组的index是新vnode的索引 , value是老vnode的索引。
接下来
for (i = s1; i <= e1; i++) { /* 开始遍历老节点 */
const prevChild = c1[i]
if (patched >= toBePatched) { /* 已经patch数量大于等于, */
/* ① 如果 toBePatched新的节点数量为0 ,那么统一卸载老的节点 */
unmount(prevChild, parentComponent, parentSuspense, true)
continue
}
let newIndex
/* ② 如果,老节点的key存在 ,通过key找到对应的index */
if (prevChild.key != null) {
newIndex = keyToNewIndexMap.get(prevChild.key)
} else { /* ③ 如果,老节点的key不存在 */
for (j = s2; j <= e2; j++) { /* 遍历剩下的所有新节点 */
if (
newIndexToOldIndexMap[j - s2] === 0 && /* newIndexToOldIndexMap[j - s2] === 0 新节点没有被patch */
isSameVNodeType(prevChild, c2[j] as VNode)
) { /* 如果找到与当前老节点对应的新节点那么 ,将新节点的索引,赋值给newIndex */
newIndex = j
break
}
}
}
if (newIndex === undefined) { /* ①没有找到与老节点对应的新节点,删除当前节点,卸载所有的节点 */
unmount(prevChild, parentComponent, parentSuspense, true)
} else {
/* ②把老节点的索引,记录在存放新节点的数组中, */
newIndexToOldIndexMap[newIndex - s2] = i + 1
if (newIndex >= maxNewIndexSoFar) {
maxNewIndexSoFar = newIndex
} else {
/* 证明有节点已经移动了 */
moved = true
}
/* 找到新的节点进行patch节点 */
patch(
prevChild,
c2[newIndex] as VNode,
container,
null,
parentComponent,
parentSuspense,
isSVG,
optimized
)
patched++
}
}
这段代码算是diff算法的核心。
第一步: 通过老节点的key找到对应新节点的index:开始遍历老的节点,判断有没有key, 如果存在key通过新节点的keyToNewIndexMap找到与新节点index,如果不存在key那么会遍历剩下来的新节点试图找到对应index。 第二步:如果存在index证明有对应的老节点,那么直接复用老节点进行patch,没有找到与老节点对应的新节点,删除当前老节点。 第三步:newIndexToOldIndexMap找到对应新老节点关系。
到这里,我们patch了一遍,把所有的老vnode都patch了一遍。
如图所示
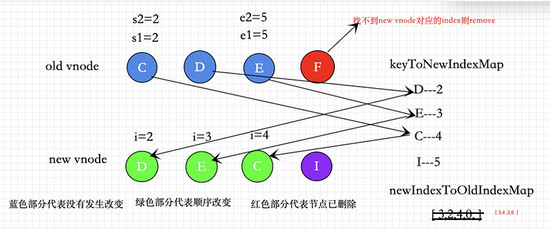
但是接下来的问题。
1 虽然已经patch过所有的老节点。可以对于已经发生移动的节点,要怎么真正移动dom元素。
2 对于新增的节点,(图中节点I)并没有处理,应该怎么处理。
/*移动老节点创建新节点*/
/* 根据最长稳定序列移动相对应的节点 */
const increasingNewIndexSequence = moved
? getSequence(newIndexToOldIndexMap)
: EMPTY_ARR
j = increasingNewIndexSequence.length - 1
for (i = toBePatched - 1; i >= 0; i--) {
const nextIndex = s2 + i
const nextChild = c2[nextIndex] as VNode
const anchor =
nextIndex + 1 < l2 ? (c2[nextIndex + 1] as VNode).el : parentAnchor
if (newIndexToOldIndexMap[i] === 0) { /* 没有老的节点与新的节点对应,则创建一个新的vnode */
patch(
null,
nextChild,
container,
anchor,
parentComponent,
parentSuspense,
isSVG
)
} else if (moved) {
if (j < 0 || i !== increasingNewIndexSequence[j]) { /*如果没有在长*/
/* 需要移动的vnode */
move(nextChild, container, anchor, MoveType.REORDER)
} else {
j--
}
⑥最长稳定序列
首选通过getSequence得到一个最长稳定序列,对于index === 0 的情况也就是 新增节点(图中I) 需要从新mount一个新的vnode,然后对于发生移动的节点进行统一的移动操作
什么叫做最长稳定序列
对于以下的原始序列
0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15
最长递增子序列为
0, 2, 6, 9, 11, 15.
为什么要得到最长稳定序列
因为我们需要一个序列作为基础的参照序列,其他未在稳定序列的节点,进行移动。
总结
经过上述我们大致知道了diff算法的流程
1 从头对比找到有相同的节点 patch ,发现不同,立即跳出。
2如果第一步没有patch完,立即,从后往前开始patch ,如果发现不同立即跳出循环。 3如果新的节点大于老的节点数 ,对于剩下的节点全部以新的vnode处理( 这种情况说明已经patch完相同的vnode )。 4 对于老的节点大于新的节点的情况 , 对于超出的节点全部卸载 ( 这种情况说明已经patch完相同的vnode )。 5不确定的元素( 这种情况说明没有patch完相同的vnode ) 与 3 ,4对立关系。
1 把没有比较过的新的vnode节点,通过map保存
记录已经patch的新节点的数量 patched
没有经过 path 新的节点的数量 toBePatched
建立一个数组newIndexToOldIndexMap,每个子元素都是[ 0, 0, 0, 0, 0, 0, ] 里面的数字记录老节点的索引 ,数组索引就是新节点的索引
开始遍历老节点
① 如果 toBePatched新的节点数量为0 ,那么统一卸载老的节点
② 如果,老节点的key存在 ,通过key找到对应的index
③ 如果,老节点的key不存在
1 遍历剩下的所有新节点
2 如果找到与当前老节点对应的新节点那么 ,将新节点的索引,赋值给newIndex
④ 没有找到与老节点对应的新节点,卸载当前老节点。
⑤ 如果找到与老节点对应的新节点,把老节点的索引,记录在存放新节点的数组中,
1 如果节点发生移动 记录已经移动了
2 patch新老节点 找到新的节点进行patch节点
遍历结束 如果发生移动
① 根据 newIndexToOldIndexMap 新老节点索引列表找到最长稳定序列
② 对于 newIndexToOldIndexMap -item =0 证明不存在老节点 ,从新形成新的vnode
③ 对于发生移动的节点进行移动处理。
三 key的作用,如何正确key。
1key的作用
在我们上述diff算法中,通过isSameVNodeType方法判断,来判断key是否相等判断新老节点。
那么由此我们可以总结出?
在v-for循环中,key的作用是:通过判断newVnode和OldVnode的key是否相等,从而复用与新节点对应的老节点,节约性能的开销。
2如何正确使用key
①错误用法 1:用index做key。
用index做key的效果实际和没有用diff算法是一样的,为什么这么说呢,下面我就用一幅图来说明:

如果所示当我们用index作为key的时候,无论我们怎么样移动删除节点,到了diff算法中都会从头到尾依次patch(图中: 所有节点均未有效的复用 )
②错误用法2 :用index拼接其他值作为key。
当已用index拼接其他值作为索引的时候,因为每一个节点都找不到对应的key,导致所有的节点都不能复用,所有的新vnode都需要重新创建。都需要重新create
如图所示。

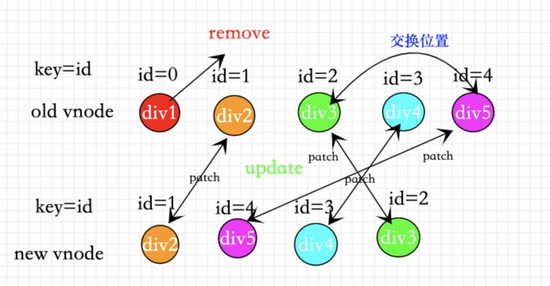
③正确用法 :用唯一值id做key(我们可以用前后端交互的数据源的id为key)。
如图所示。每一个节点都做到了复用。起到了diff算法的真正作用。
四 总结
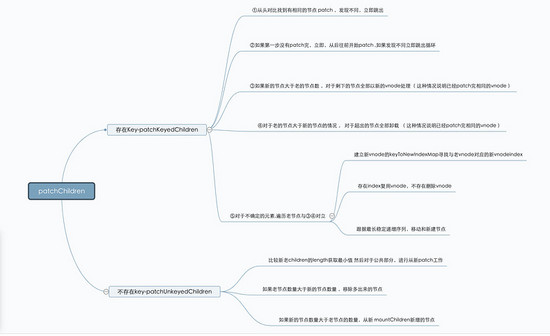
我们在上面,已经把刚开始的问题统统解决了,最后用一张思维脑图来从新整理一下整个流程。
到此这篇关于详解vue3.0 diff算法的使用(超详细)的文章就介绍到这了,更多相关vue3.0 diff算法内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/189862/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)