
一、Steam的优势
java8中Stream配合Lambda表达式极大提高了编程效率,代码简洁易懂(可能刚接触的人会觉得晦涩难懂),不需要写传统的多线程代码就能写出高性能的并发程序
二、项目中遇到的问题
由于微信接口限制,每次导入code只能100个,所以需要分割list。但是由于code数量可能很大,这样执行效率就会很低。
1.首先想到是用多线程写传统并行程序,但是博主不是很熟练,写出代码可能会出现不可预料的结果,容易出错也难以维护。
2.然后就想到Steam中的parallel,能提高性能又能利用java8的特性,何乐而不为。
三、废话不多说,直接先贴代码,然后再解释(java8分割list代码在标题四)。

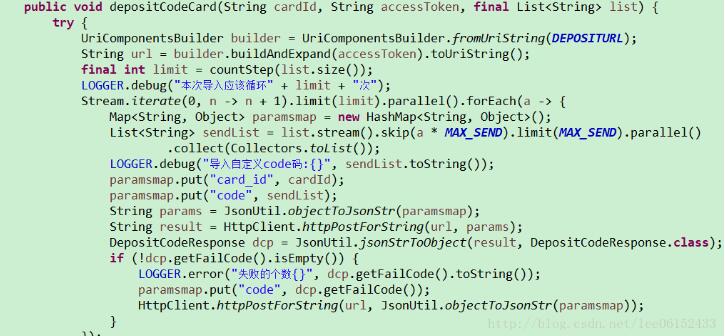
1.该方法是根据传入数量生成codes,private String getGeneratorCode(int tenantId)是我根据编码规则生成唯一code这个不需要管,我们要看的是Stream.iterate
2.iterate()第一个参数为起始值,第二个函数表达式(看自己想要生成什么样的流关键在这里),http://write.blog.csdn.net/postedit然后必须要通过limit方法来限制自己生成的Stream大小。parallel()是开启并行处理。map()就是一对一的把Stream中的元素映射成ouput Steam中的 元素。最后用collect收集,
2.1 构造流的方法还有Stream.of(),结合或者数组可直接list.stream();
String[] array = new String[]{"1","2","3"} ;
stream = Stream.of(array)或者Arrays.Stream(array);
2.2 数值流IntStream
int[] array = new int[]{1,2,3};
IntStream.of(array)或者IntStream.ranage(0,3)
3.以上构造流的方法都是已经知道大小,对于通过入参确定的应该图中方法自己生成流。
四、java8分割list,利用StreamApi实现。
没用java8前代码,做个鲜明对比():
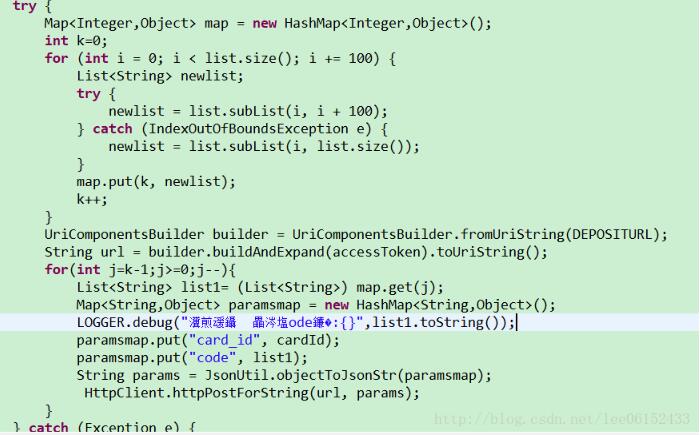
1.list是我的编码集合(codes)。MAX_SEND为100(即每次100的大小去分割list),limit为按编码集合大小算出的本次需要分割多少次。
2.我们可以看到其实就是多了个skip跟limit方法。skip就是舍弃stream前多少个元素,那么limit就是返回流前面多少个元素(如果流里元素少于该值,则返回全部)。然后开启并行处理。通过循环我们的分割list的目标就达到了,每次取到的sendList就是100,100这样子的。
3.因为我这里业务就只需要到这里,如果我们分割之后需要收集之后再做处理,那只需要改写一下就ok;如:
List<List<String>> splitList = Stream.iterate(0,n->n+1).limit(limit).parallel().map(a->{
List<String> sendList = list.stream().skip(a*MAX_SEND).limit(MAX_SEND).parallel().collect(Collectors.toList());
}).collect(Collectors.toList());
五、java8流里好像拿不到下标,所以我才用到构造一个递增数列当下标用,这就是我用java8分割list的过程,比以前的for循环看的爽心悦目,优雅些,性能功也提高了。
如果各位有更好的实现方式,欢迎留言指教。
补充知识:聊聊flink DataStream的split操作
序
本文主要研究一下flink DataStream的split操作
实例
SplitStream<Integer> split = someDataStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
}
else {
output.add("odd");
}
return output;
}
});
本实例将dataStream split为两个dataStream,一个outputName为even,另一个outputName为odd
DataStream.split
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/datastream/DataStream.java
@Public
public class DataStream<T> {
//......
public SplitStream<T> split(OutputSelector<T> outputSelector) {
return new SplitStream<>(this, clean(outputSelector));
}
//......
}
DataStream的split操作接收OutputSelector参数,然后创建并返回SplitStream
OutputSelector
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/collector/selector/OutputSelector.java
@PublicEvolving
public interface OutputSelector<OUT> extends Serializable {
Iterable<String> select(OUT value);
}
OutputSelector定义了select方法用于给element打上outputNames
SplitStream
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/datastream/SplitStream.java
@PublicEvolving
public class SplitStream<OUT> extends DataStream<OUT> {
protected SplitStream(DataStream<OUT> dataStream, OutputSelector<OUT> outputSelector) {
super(dataStream.getExecutionEnvironment(), new SplitTransformation<OUT>(dataStream.getTransformation(), outputSelector));
}
public DataStream<OUT> select(String... outputNames) {
return selectOutput(outputNames);
}
private DataStream<OUT> selectOutput(String[] outputNames) {
for (String outName : outputNames) {
if (outName == null) {
throw new RuntimeException("Selected names must not be null");
}
}
SelectTransformation<OUT> selectTransform = new SelectTransformation<OUT>(this.getTransformation(), Lists.newArrayList(outputNames));
return new DataStream<OUT>(this.getExecutionEnvironment(), selectTransform);
}
}
SplitStream继承了DataStream,它定义了select方法,可以用来根据outputNames选择split出来的dataStream;select方法创建了SelectTransformation
StreamGraphGenerator
flink-streaming-java_2.11-1.7.0-sources.jar!/org/apache/flink/streaming/api/graph/StreamGraphGenerator.java
@Internal
public class StreamGraphGenerator {
//......
private Collection<Integer> transform(StreamTransformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from theExecutionConfig.
int globalMaxParallelismFromConfig = env.getConfig().getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to trigger exceptions about MissingTypeInfo
transform.getOutputType();
Collection<Integer> transformedIds;
if (transform instanceof OneInputTransformation<?, ?>) {
transformedIds = transformOneInputTransform((OneInputTransformation<?, ?>) transform);
} else if (transform instanceof TwoInputTransformation<?, ?, ?>) {
transformedIds = transformTwoInputTransform((TwoInputTransformation<?, ?, ?>) transform);
} else if (transform instanceof SourceTransformation<?>) {
transformedIds = transformSource((SourceTransformation<?>) transform);
} else if (transform instanceof SinkTransformation<?>) {
transformedIds = transformSink((SinkTransformation<?>) transform);
} else if (transform instanceof UnionTransformation<?>) {
transformedIds = transformUnion((UnionTransformation<?>) transform);
} else if (transform instanceof SplitTransformation<?>) {
transformedIds = transformSplit((SplitTransformation<?>) transform);
} else if (transform instanceof SelectTransformation<?>) {
transformedIds = transformSelect((SelectTransformation<?>) transform);
} else if (transform instanceof FeedbackTransformation<?>) {
transformedIds = transformFeedback((FeedbackTransformation<?>) transform);
} else if (transform instanceof CoFeedbackTransformation<?>) {
transformedIds = transformCoFeedback((CoFeedbackTransformation<?>) transform);
} else if (transform instanceof PartitionTransformation<?>) {
transformedIds = transformPartition((PartitionTransformation<?>) transform);
} else if (transform instanceof SideOutputTransformation<?>) {
transformedIds = transformSideOutput((SideOutputTransformation<?>) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
if (transform.getBufferTimeout() >= 0) {
streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());
}
if (transform.getUid() != null) {
streamGraph.setTransformationUID(transform.getId(), transform.getUid());
}
if (transform.getUserProvidedNodeHash() != null) {
streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash());
}
if (transform.getMinResources() != null && transform.getPreferredResources() != null) {
streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources());
}
return transformedIds;
}
private <T> Collection<Integer> transformSelect(SelectTransformation<T> select) {
StreamTransformation<T> input = select.getInput();
Collection<Integer> resultIds = transform(input);
// the recursive transform might have already transformed this
if (alreadyTransformed.containsKey(select)) {
return alreadyTransformed.get(select);
}
List<Integer> virtualResultIds = new ArrayList<>();
for (int inputId : resultIds) {
int virtualId = StreamTransformation.getNewNodeId();
streamGraph.addVirtualSelectNode(inputId, virtualId, select.getSelectedNames());
virtualResultIds.add(virtualId);
}
return virtualResultIds;
}
private <T> Collection<Integer> transformSplit(SplitTransformation<T> split) {
StreamTransformation<T> input = split.getInput();
Collection<Integer> resultIds = transform(input);
// the recursive transform call might have transformed this already
if (alreadyTransformed.containsKey(split)) {
return alreadyTransformed.get(split);
}
for (int inputId : resultIds) {
streamGraph.addOutputSelector(inputId, split.getOutputSelector());
}
return resultIds;
}
//......
}
StreamGraphGenerator里头的transform会对SelectTransformation以及SplitTransformation进行相应的处理
transformSelect方法会根据select.getSelectedNames()来addVirtualSelectNode
transformSplit方法则根据split.getOutputSelector()来addOutputSelector
小结
DataStream的split操作接收OutputSelector参数,然后创建并返回SplitStream
OutputSelector定义了select方法用于给element打上outputNames
SplitStream继承了DataStream,它定义了select方法,可以用来根据outputNames选择split出来的dataStream
doc
以上这篇java8中Stream的使用以及分割list案例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/193603/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)