
读取键盘输入
package com.zjx.io;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
/**
* 面试题
* 读取键盘各个数据类型
*
*/
public class TestFaceIo {
public static void main(String[] args) {
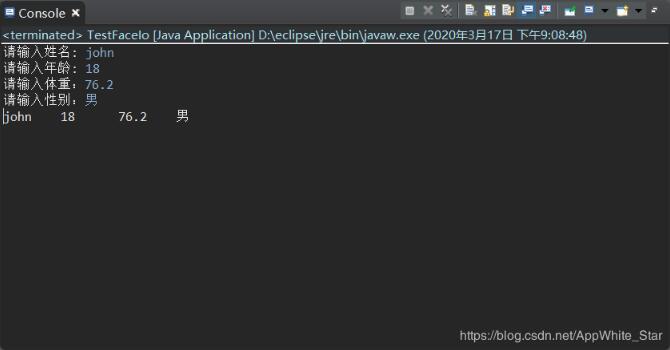
System.out.print("请输入姓名: ");
String name = MyInput.readString();
System.out.print("请输入年龄: ");
int age = MyInput.readInt();
System.out.print("请输入体重:");
double weight = MyInput.readDouble();
System.out.print("请输入性别:");
char sex = MyInput.readChar();
System.out.println(name + "\t" + age + "\t" + weight + "\t" + sex);
MyInput.close();
}
}
class MyInput{
static BufferedReader reader = null;
/**
* 读取整数
* @return
*/
public static int readInt(){
int num = Integer.parseInt(readString());
return num;
}
/**
* 读取浮点数
* @return
*/
public static double readDouble(){
double num = Double.parseDouble(readString());
return num;
}
/**
* 读取char单个字符
* @return
*/
public static char readChar(){
char ch = readString().charAt(0);
return ch;
}
/**
* 读取字符串
* @return
*/
public static String readString(){
try {
reader = new BufferedReader(new InputStreamReader(System.in));
String line = reader.readLine();
return line;
} catch (Exception e) {
//编译异常--》运行异常
throw new RuntimeException(e);
}
}
/**
* 关闭
*/
public static void close(){
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
补充知识:java的Scanner与Fmatting
Scanner扫描仪与Fmatting
Programming I/O often involves translating to and from the neatly formatted data humans like to work with. 译文:对I / O进行编程通常涉及到人们喜欢使用的格式正确的数据的转换。(机器翻译的,有点拗口,欢迎大神帮忙翻译的顺口一点,总而言之,将数据转换为人们喜欢的)
为了帮助您完成这些杂务,Java平台提供了两个API。 扫描程序API将输入分为与数据位相关联的各个令牌。 格式API将数据组合成格式良好,易于阅读的格式。(细心地人会发现,扫描程序Scanner和格式化Fmatting是相反的两个操作,一个是分散数据,一个是组合数组)
Scanner
定义:Scanner类型的对象可用于将格式化的输入分解为令牌,并根据其数据类型转换单个令牌。
Scanner我看做用于格式化读取文本文件
scanner扫描流。可以扫描文件与控制台的输入
默认情况下,scanner (扫描器)使用空格分隔令牌。 (空白字符包括空格,制表符和行终止符。有关完整列表,请参阅Character.isWhitespace的文档。)要查看扫描的工作方式,让我们看一下案例,该程序可读取文本文件中的各个单词。 并打印出来,每行一个。
package ff;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Scanner;
public class CopyCytes {
public static void main(String[] args) throws IOException {
Scanner s=null;
try {
s=new Scanner(new BufferedReader(new FileReader("txt/input.txt")));
//s.useDelimiter(",\\s*");也可以自定义分隔符
while(s.hasNext()) {
System.out.println(s.next());
}
}finally {
if(s!=null) {
s.close();
}
}
}
}
programe result:
By default, a scanner uses white space to separate tokens.
从以上程序测试可以看出来Scanner扫描仪根据某一个分割符号一行一行的打印数据。
Scanner用完必须关闭底层流
注意:类在处理Scanner对象时调用Scanner的close方法。即使Scanner扫描仪不是流,您也需要关闭它,以表明您已处理完其底层流。
Scanner可以自定义分隔符
若要使用其他标记分隔符,请调用useDelimiter(),指定一个正则表达式。例如,假设您希望令牌分隔符是逗号,后面有空格。你会调用
s.useDelimiter(",\\s*");
Scanner扫描仪支持多种数据类型
上面的示例将所有输入标记视为简单的字符串值
Scanner还支持所有Java语言的基元类型(char除外)以及BigInteger和BigDecimal的标记。
此外,数值可以使用数千个分隔符。
因此,在US语言环境中,Scanner正确地读取字符串“32767”表示整数值。
We have to mention the locale, because thousands separators and decimal symbols are locale specific. So, the following example would not work correctly in all locales if we didn't specify that the scanner should use the US locale. That's not something you usually have to worry about, because your input data usually comes from sources that use the same locale as you do. But this example is part of the Java Tutorial and gets distributed all over the world.
译文:
我们必须提到语言环境,因为数千个分隔符和十进制符号是特定于语言环境的。 因此,如果我们未指定扫描仪应使用美国语言环境,则以下示例在所有语言环境中均无法正常工作。 通常不必担心,因为您的输入数据通常来自与您使用相同语言环境的源。 但是此示例是Java教程的一部分,并在全世界范围内分发。
package ff;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Locale;
import java.util.Scanner;
public class CopyCytes {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
try {
s = new Scanner(new BufferedReader(new FileReader("txt/input.txt")));
// s.useDelimiter(",\\s*");
s.useLocale(Locale.US);
while (s.hasNext()) {
if (s.hasNextDouble()) {
sum = sum + s.nextDouble();
} else {
s.next();
}
}
} finally {
if (s != null) {
s.close();
}
System.out.println(sum);
}
}
}
input.txt文件内容是:
8.5 32,767 3.14159 1,000,000.1
program result:
输出字符串为“ 1032778.74159”。
在某些语言环境( in some locales)中,句点将是一个不同的字符,因为System.out是一个PrintStream对象,并且该类没有提供重写默认语言环境的方法。 我们可以覆盖整个程序的语言环境,也可以只使用格式化,如下一主题“格式化”中所述。
重点:
设置语言环境
format
实现(格式fammatting)的流对象是字符流类PrintWriter或字节流类PrintStream的实例。
Note: The only PrintStream objects you are likely to need are System.out and System.err. (See I/O from the Command Line for more on these objects.) When you need to create a formatted output stream, instantiate PrintWriter, not PrintStream.
原文:
Like all byte and character stream objects, instances of PrintStream and PrintWriter implement a standard set of write methods for simple byte and character output. In addition, both PrintStream and PrintWriter implement the same set of methods for converting internal data into formatted output. Two levels of formatting are provided: print and println format individual values in a standard way. format formats almost any number of values based on a format string, with many options for precise formatting.
译文:
像所有字节和字符流对象一样,PrintStream和PrintWriter的实例实现一组标准的写Write方法,用于简单的字节和字符输出。 此外字节流输出类PrintStream和字符流类PrintWriter都实现了将内部数据转换为格式化输出的相同方法集。 提供了两种格式设置:
print和println以标准方式格式化各个值。
Fammatting(格式)会基于一个格式字符串对几乎任何数量的值进行格式设置,并提供许多用于精确格式设置的选项。
原文:
Invoking print or println outputs a single value after converting the value using the appropriate toString method. We can see this in the Root example:
译文:
调用print或println将输出一个经过toString方法转换的值。 我们可以在以下示例中看到这一点:
package ff;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Locale;
import java.util.Scanner;
public class CopyCytes {
public static void main(String[] args) throws IOException {
Scanner s = null;
double sum = 0;
int i = 2;
double r = Math.sqrt(i);
System.out.print("the square root of ");
// i的第一次格式化,使用的是print的重载
System.out.print(i);
System.out.print(" is ");
// r的第一次格式化也是使用的Print的重载
System.out.print(r);
System.out.println(".");
i = 5;
r = Math.sqrt(i);
// i 和 r的第二次格式化是使用的编译器隐藏的自动的格式化
System.out.println("The square root of " + i + " is " + r + ".");
}
}
原文:
The i and r variables are formatted twice: the first time using code in an overload of print, the second time by conversion code automatically generated by the Java compiler,which also utilizes toString You can format any value this way, but you don't have much control over the results.
译文:
变量i和r被格式化两次,第一次使用在一个print的重载中
第二次使用在使用了tostring方法的java编译器生成的的自动转换代码中
通过这种方式你可以格式化任何值,但是你对结果没有任何控制权(重点是你对格式化的结果没有控制权)。
Format方法
原文:
The format method formats multiple arguments based on a format string. The format string consists of static text embedded with format specifiers; except for the format specifiers, the format string is output unchanged.
译文:
format方法基于格式化的字符串格式化多个参数。 格式字符串由嵌入了格式说明符的静态文本组成。
除格式说明符外,格式字符串的输出保持不变。(简单点,格式符号起到占位的作用,其他的字符正常输出)
格式字符串支持许多功能。 在本教程中,我们将仅介绍一些基础知识。 有关完整说明,请参阅API规范中的格式字符串语法。
Format案例:
package ff;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Locale;
import java.util.Scanner;
public class CopyCytes {
public static void main(String[] args) throws IOException {
int i=2;
double r=Math.sqrt(i);
System.out.format("The square root of %d is %f.%n", i,r);
}
}
Like the three used in this example, all format specifiers begin with a % and end with a 1- or 2-character conversion that specifies the kind of formatted output being generated. The three conversions used here are://所有格式说明符都以%开头,并以1或2个字符的转换结尾,该转换指定要生成的格式化输出的种类
注意:
除%%和%n外,所有格式说明符必须与参数匹配。 如果没有,则抛出异常。
原文:
In the Java programming language, the \n escape always generates the linefeed character (\u000A). Don't use \n unless you specifically want a linefeed character. To get the correct line separator for the local platform, use %n.
译文:
在Java编程语言中,\ n转义始终生成换行符(\ u000A)。 除非特别需要换行符,否则请勿使用\ n。 要为本地平台获取正确的行分隔符,请使用%n。(这里的言外之意是,一个是生成转义字符,一个是格式化占位符,两者有本质区别,虽然在程序中看起来实现了一样的效果。)
以上这篇java自定义Scanner类似功能类的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/193815/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)