
网上http接口自动化测试Python实现有很多,我也是在慕课网上学习了相关课程,并实际操作了一遍,于是进行一些总结,便于以后回顾温习,有许多不完善的地方,希望大神们多多指教!
接口测试常用的工具有fiddler,postman,jmeter等,使用这些工具测试时,需要了解常用的接口类型和区别,比如我用到的post和get请求,表面上看get用于获取数据post用于修改数据,两者传递参数的方式也有不一样,get是直接在url里通过?来连接参数,而post则是把数据放在HTTP的包体内(request body),两者的本质就是TCP链接,并无差别,但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。具体的可以参考此博文,讲解的比较通俗易懂。这些在工具中可以直接选择,python需要借助requests包。
确定好接口类型后,需要做的就是准备测试数据和设计测试用例了,测试用例比如说可以判断返回状态响应码,或者对返回数据进行判别等,具体可以参考postman中的echo.collections,对于python可以用unittest来组织测试用例和添加断言进行判断。而对于测试数据的准备,需要做到数据和业务尽量分离,即将测试数据参数化,在工具中可以通过添加变量的形式实现,对于python设计到的有关包有xlrd,json,如果需要连接数据库还需要mysql。
测试完成后生产报告或者发送邮件,也可以使用HTMLTestRunner和smtplib等。
我也从这三大方面进行总结:
1. 接口方法实现和封装
requests库可以很好的帮助我们实现HTTP请求,API参考文档,这里我创建了runmethod.py,里面包含RunMethod类:
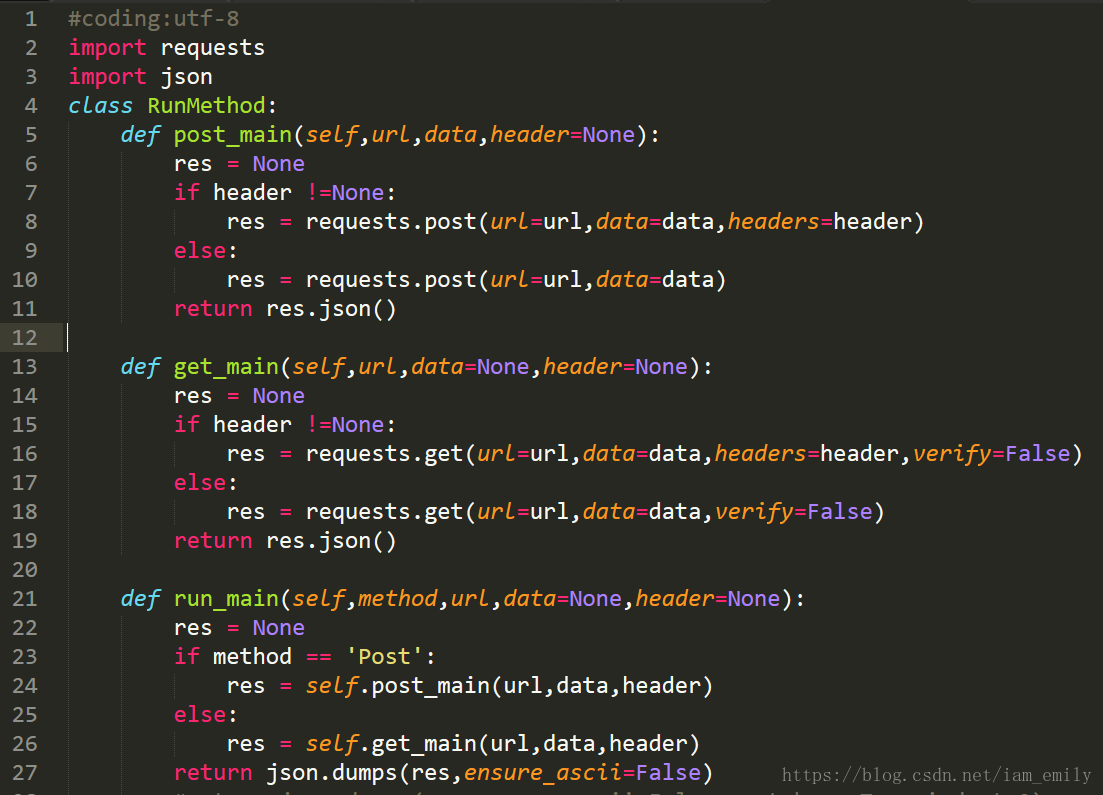
这里需要注意就是python默认参数和可选参数要放在必选参数后面,对于相应数据使用json格式进行返回。参数verify=false表示忽略对 SSL 证书的验证。
2.组织测试和生成报告
使用unittest来组织测试、添加测试用例和断言,测试报告可以下载HTMLTestRunner.py并放在python安装路径lib下即可,代码如下:
#coding:utf-8
import unittest
import json
import HTMLTestRunner
from mock import mock
#from demo import RunMain
from runmethod import RunMethod
from mock_demo import mock_test
import os
class TestMethod(unittest.TestCase):
def setUp(self):
#self.run=RunMain()
self.run = RunMethod()
def test_01(self):
url = 'http://coding.imooc.com/api/cate'
data = {
'timestamp':'1507034803124',
'uid':'5249191',
'uuid':'5ae7d1a22c82fb89c78f603420870ad7',
'secrect':'078474b41dd37ddd5efeb04aa591ec12',
'token':'7d6f14f21ec96d755de41e6c076758dd',
'cid':'0',
'errorCode':1001
}
#self.run.run_main = mock.Mock(return_value=data)
res = mock_test(self.run.run_main,data,url,"POST",data)
#res = self.run.run_main(url,'POST',data)
print(res)
self.assertEqual(res['errorCode'],1001,"测试失败")
@unittest.skip('test_02')
def test_02(self):
url = 'http://coding.imooc.com/api/cate'
data = {
'timestamp':'1507034803124',
'uid':'5249191',
'uuid':'5ae7d1a22c82fb89c78f603420870ad7',
'secrect':'078474b41dd37ddd5efeb04aa591ec12',
'token':'7d6f14f21ec96d755de41e6c076758dd',
'cid':'0'
}
res = self.run.run_main(url,'GET',data)
self.assertEqual(res['errorCode'],1006,"测试失败")
def test_03(self):
url = 'http://coding.imooc.com/api/cate'
data = {
'timestamp':'1507034803124',
'uid':'5249191',
'uuid':'5ae7d1a22c82fb89c78f603420870ad7',
'secrect':'078474b41dd37ddd5efeb04aa591ec12',
'token':'7d6f14f21ec96d755de41e6c076758dd',
'cid':'0',
'status':11
}
res = mock_test(self.run.run_main,data,url,'GET',data)
print(res)
self.assertGreater(res['status'],10,'测试通过')
if __name__ == '__main__':
filepath = os.getcwd()+'\\report.html'
fp = open(filepath,'wb+')
suite = unittest.TestSuite()
suite.addTest(TestMethod('test_01'))
suite.addTest(TestMethod('test_02'))
suite.addTest(TestMethod('test_03'))
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,title='this is demo test')
runner.run(suite)
#unittest.main()
这里setUp()方法用来在测试之前执行,同样的有tearDown()方法,测试case以test开头进行编写,然后使用TestSuit类生成测试套件,将case添加进去,运行run suite即可。当测试用例较多时,可以生成多个测试类别,然后使用TestLoader().LoadTestsFromTestCase(测试类)生成测试用例,再加入testsuite执行。
在这里,我使用了学习到的mock方法,mock即模拟数据,当我们无法实际执行获得数据时可以使用mock方法,模拟生成我们需要判别的数据,这里mock_test方法同样进行了封装:
#coding:utf-8 from mock import mock def mock_test(mock_method,request_data,url,method,response_data): mock_method = mock.Mock(return_value=response_data) res = mock_method(url,method,request_data) return res
这里模拟的是self.run.run_main()方法,将这个方法的返回值设为response_data,而最终我们要判断的是返回值res,可以结合test_02对比,
res = self.run.run_main(url,'GET',data)
所以又需要传入参数url,method,request_data,最后返回相应数据即可,
res = mock_test(self.run.run_main,data,url,'GET',data)
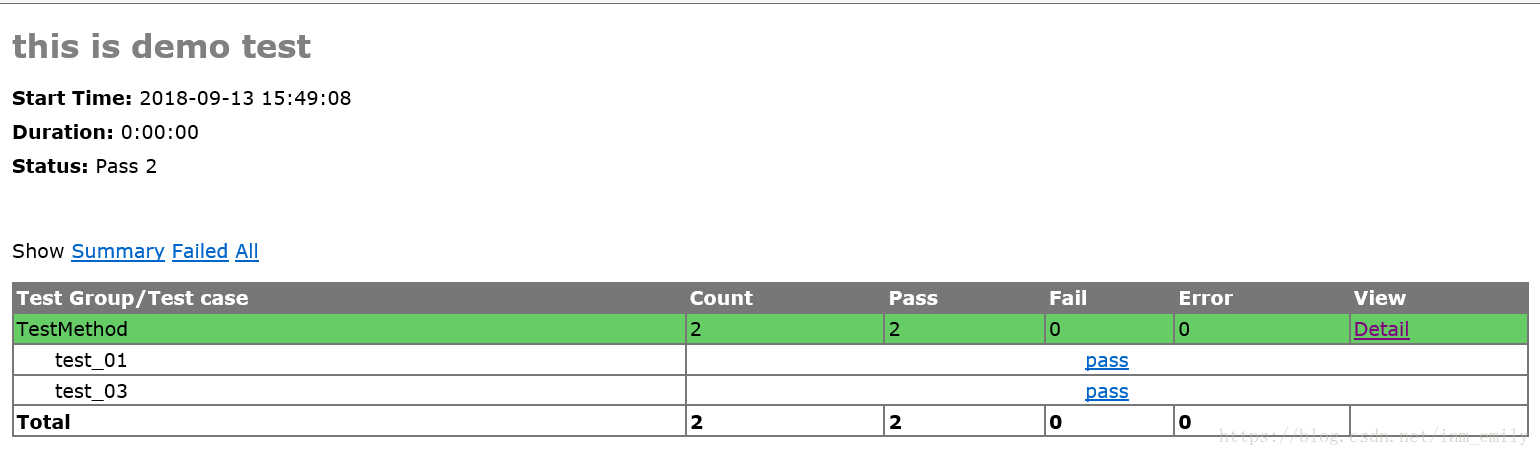
这里我假设返回的数据为data,随意添加了几个判断条件errorCode==1001和status>10作为判断依据。最后生成报告如下:
3 测试数据处理
这一部分主要包括设计测试数据,数据提取和参数化,以及解决数据依赖。这里还是以慕课网上学习的例子为例,主要依据测试目的和使用流程来设计,如下图:
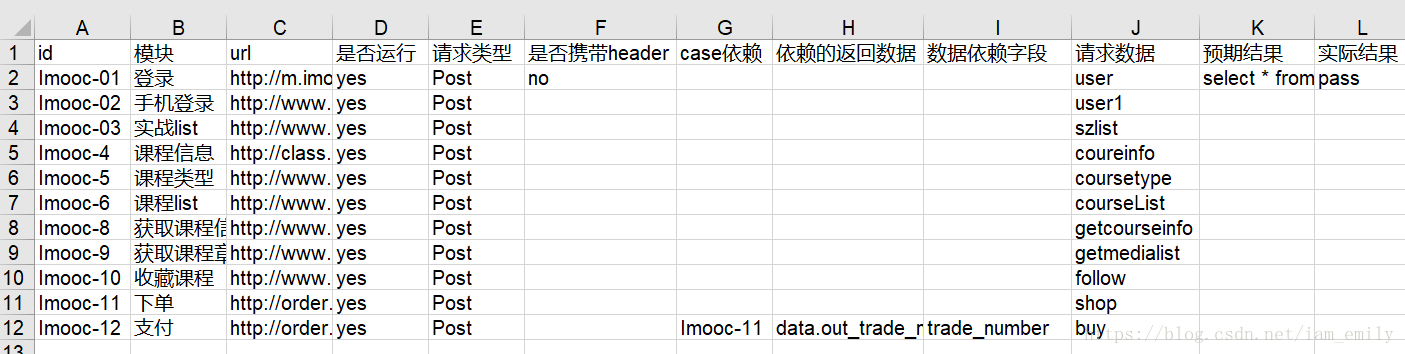
这里首先涉及到的就是对Excel表格的操作,导入相关库import xlrd,先对如上表的测试用例进行配置文件编写:
class global_var: Id = '0' request_name = '1' url = '2' run = '3' request_way = '4' header = '5' case_depend = '6' data_depend = '7' field_depend = '8' data = '9' expect = '10' result = '11'
再定义返回该列的函数,例如获取caseId和URL:
def get_id(): return global_var.Id def get_url(): return global_var.url
3.1操作Excel文件
然后我们再编写操作Excel的模块,主要包含了对Excel表格的操作,获取表单、行、列、单元格内容等。
import xlrd from xlutils.copy import copy class OperationExcel: def __init__(self,file_name=None,sheet_id=None): if file_name: self.file_name = file_name self.sheet_id = sheet_id else: self.file_name = '/dataconfig/case1.xls' self.sheet_id = 0 self.data = self.get_data() #获取sheets的内容 def get_data(self): data = xlrd.open_workbook(self.file_name) tables = data.sheets()[self.sheet_id] return tables #获取单元格的行数 def get_lines(self): tables = self.data return tables.nrows #获取某一个单元格的内容 def get_cell_value(self,row,col): return self.data.cell_value(row,col) #写入数据 def write_value(self,row,col,value): '''写入excel数据row,col,value''' read_data = xlrd.open_workbook(self.file_name) write_data = copy(read_data) sheet_data = write_data.get_sheet(0) sheet_data.write(row,col,value) write_data.save(self.file_name)
其中写数据用于将运行结果写入Excel文件,先用copy复制整个文件,通过get_sheet()获取的sheet有write()方法。
3.2操作json文件
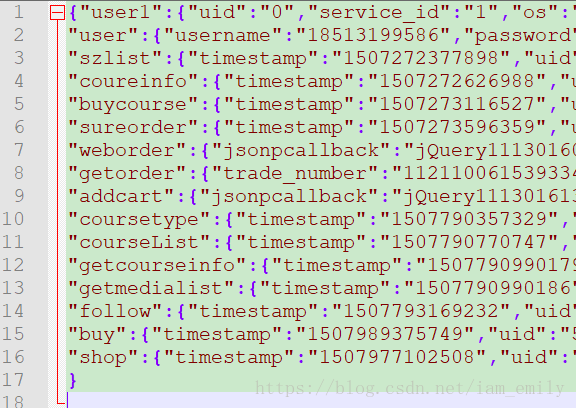
对于请求数据,我是根据关键字从json文件里取出字段,所以还需要json格式的数据文件,如下。对应请求数据中的各个关键字:
所以还需要编写对应操作json文件的模块:
import json class OperetionJson: def __init__(self,file_path=None): if file_path == None: self.file_path = '/dataconfig/user.json' else: self.file_path = file_path self.data = self.read_data() #读取json文件 def read_data(self): with open(self.file_path) as fp: data = json.load(fp) return data #根据关键字获取数据 def get_data(self,id): print(type(self.data)) return self.data[id]
读写操作使用的是json.load(),json.dump() 传入的是文件句柄。
3.3 获得测试数据
在定义好Excel和json操作模块后,我们将其应用于我们的测试表单,定义一个获取数据模块:
from util.operation_excel import OperationExcel import data.data_config from util.operation_json import OperetionJson class GetData: def __init__(self): self.opera_excel = OperationExcel() #去获取excel行数,就是我们的case个数 def get_case_lines(self): return self.opera_excel.get_lines() #获取是否执行 def get_is_run(self,row): flag = None col = int(data_config.get_run()) run_model = self.opera_excel.get_cell_value(row,col) if run_model == 'yes': flag = True else: flag = False return flag #是否携带header def is_header(self,row): col = int(data_config.get_header()) header = self.opera_excel.get_cell_value(row,col) if header != '': return header else: return None #获取请求方式 def get_request_method(self,row): col = int(data_config.get_run_way()) request_method = self.opera_excel.get_cell_value(row,col) return request_method #获取url def get_request_url(self,row): col = int(data_config.get_url()) url = self.opera_excel.get_cell_value(row,col) return url #获取请求数据 def get_request_data(self,row): col = int(data_config.get_data()) data = self.opera_excel.get_cell_value(row,col) if data == '': return None return data #通过获取关键字拿到data数据 def get_data_for_json(self,row): opera_json = OperetionJson() request_data = opera_json.get_data(self.get_request_data(row)) return request_data #获取预期结果 def get_expcet_data(self,row): col = int(data_config.get_expect()) expect = self.opera_excel.get_cell_value(row,col) if expect == '': return None return expect def write_result(self,row,value): col = int(data_config.get_result()) self.opera_excel.write_value(row,col,value)
该模块将Excel操作类实例化后用于操作测试表单,分别获得测试运行所需的各种条件。
3.4 判断条件
这里判断一个case是否通过,是将实际结果和预期结果进行对比,比如,状态码status是不是200,或者在返回数据中查看是否含有某一字段:
import json
import operator as op
class CommonUtil:
def is_contain(self, str_one,str_two):
'''
判断一个字符串是否再另外一个字符串中
str_one:查找的字符串
str_two:被查找的字符串
'''
flag = None
#先将返回的res进行格式转换,unicode转成string类型
if isinstance(str_one,unicode):
str_one = str_one.encode('unicode-escape').decode('string_escape')
return op.eq(str_one,str_two)
if str_one in str_two:
flag = True
else:
flag = False
return flag
def is_equal_dict(self,dict_one,dict_two):
'''判断两个字典是否相等'''
if isinstance(dict_one,str):
dict_one = json.loads(dict_one)
if isinstance(dict_two,str):
dict_two = json.loads(dict_two)
return op.eq(dict_one,dict_two)
所以我们获得expec数据和相应数据,再调用这个类别的is_contain() 方法就能判断。
3.5 数据依赖问题
当我们要执行的某个case的相应数据依赖于前面某个case的返回数据时,我们需要对相应数据进行更新,比如case12的相应数据request_data[数据依赖字段]的值应该更新于case11的返回数据response_data[依赖的返回字段] 。那么我们就需要先执行case11拿到返回数据,再写入case12的相应数据,首先对操作Excel的模块进行更新加入:
#获取某一列的内容 def get_cols_data(self,col_id=None): if col_id != None: cols = self.data.col_values(col_id) else: cols = self.data.col_values(0) return cols #根据对应的caseid找到对应的行号 def get_row_num(self,case_id): num = 0 cols_data = self.get_cols_data() for col_data in cols_data: if case_id in col_data: return num num = num+1 #根据行号,找到该行的内容 def get_row_values(self,row): tables = self.data row_data = tables.row_values(row) return row_data #根据对应的caseid 找到对应行的内容 def get_rows_data(self,case_id): row_num = self.get_row_num(case_id) rows_data = self.get_row_values(row_num) return rows_data
即我们通过依赖的caseId找到对应的行号,拿到整行的内容。我们默认拿到列0的内容(即caseId)循环整列找到依赖的caseId在第几行,然后返回整行数据,即实现方法get_rows_data(case_id) 。然后再去执行和更新,我们编写一个专门处理依赖数据的模块,同时,为了获取依赖数据,还需要对获取数据模块进行更新如下:
#获取依赖数据的key def get_depend_key(self,row): col = int(data_config.get_data_depend()) depent_key = self.opera_excel.get_cell_value(row,col) if depent_key == "": return None else: return depent_key #判断是否有case依赖 def is_depend(self,row): col = int(data_config.get_case_depend()) depend_case_id = self.opera_excel.get_cell_value(row,col) if depend_case_id == "": return None else: return depend_case_id #获取数据依赖字段 def get_depend_field(self,row): col = int(data_config.get_field_depend()) data = self.opera_excel.get_cell_value(row,col) if data == "": return None else: return data
将方法应用于专门处理依赖数据的模块:
from util.operation_excel import OperationExcel from base.runmethod import RunMethod from data.get_data import GetData from jsonpath_rw import jsonpath,parse class DependdentData: def __init__(self,case_id): self.case_id = case_id self.opera_excel = OperationExcel() self.data = GetData() #通过case_id去获取该case_id的整行数据 def get_case_line_data(self): rows_data = self.opera_excel.get_rows_data(self.case_id) return rows_data #执行依赖测试,获取结果 def run_dependent(self): run_method = RunMethod() row_num = self.opera_excel.get_row_num(self.case_id) request_data = self.data.get_data_for_json(row_num) #header = self.data.is_header(row_num) method = self.data.get_request_method(row_num) url = self.data.get_request_url(row_num) res = run_method.run_main(method,url,request_data) return json.loads(res)#返回数据是字符串需要转成json格式方便后续查询 #根据依赖的key去获取执行依赖测试case的响应,然后返回 def get_data_for_key(self,row): depend_data = self.data.get_depend_key(row) response_data = self.run_dependent() json_exe = parse(depend_data) madle = json_exe.find(response_data) return [math.value for math in madle][0]
其中jsonpath用于找到多层级数据,类似于xpath,即通过依赖字段表示的层级关系在返回数据中找到对应的值,最后再执行该case时把数据更新。
3.6 主流程
把上述所有模块导入,编写主流程模块:
from util.operation_excel import OperationExcel from base.runmethod import RunMethod from data.get_data import GetData from jsonpath_rw import jsonpath,parse class DependdentData: def __init__(self,case_id): self.case_id = case_id self.opera_excel = OperationExcel() self.data = GetData() #通过case_id去获取该case_id的整行数据 def get_case_line_data(self): rows_data = self.opera_excel.get_rows_data(self.case_id) return rows_data #执行依赖测试,获取结果 def run_dependent(self): run_method = RunMethod() row_num = self.opera_excel.get_row_num(self.case_id) request_data = self.data.get_data_for_json(row_num) #header = self.data.is_header(row_num) method = self.data.get_request_method(row_num) url = self.data.get_request_url(row_num) res = run_method.run_main(method,url,request_data) return json.loads(res)#返回数据是字符串需要转成json格式方便后续查询 #根据依赖的key去获取执行依赖测试case的响应,然后返回 def get_data_for_key(self,row): depend_data = self.data.get_depend_key(row) response_data = self.run_dependent() json_exe = parse(depend_data) madle = json_exe.find(response_data) return [math.value for math in madle][0]
这样我们就完成了测试执行,并对结果进行了统计,同时解决了数据依赖问题。
到此这篇关于Python实现http接口自动化测试的示例代码的文章就介绍到这了,更多相关Python http接口自动化测试内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/197054/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)