
一、简介
源码地址:https://gitee.com/xiaocheng0902/my-cloud.git
1,定义
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等。Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
"断路器"本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间的、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
2,作用
a)服务降级
服务降级是从整个系统的负荷情况出发和考虑的,对某些负荷会比较高的情况,为了预防某些功能(业务场景)出现负荷过载或者响应慢的情况,在其内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的fallback(退路)错误处理信息。这样,虽然提供的是一个有损的服务,但却保证了整个系统的稳定性和可用性
b)服务熔断
服务熔断的作用类似于我们家用的保险丝,当某服务出现不可用或响应超时的情况时,为了防止整个系统出现雪崩,暂时停止对该服务的调用。
c)熔断vs降级
3,使用依赖
<!--新增hystrix--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> <version>2.2.1.RELEASE</version> </dependency>
二、服务降级
1,服务提供者(自身)
对应源码:cloud-provider-hystrix-payment8001
在主启动类Application上注解
@EnableCircuitBreaker
在service的方法中加入
//主方法
@HystrixCommand(fallbackMethod = "paymentInfo_TimeOutHandler",commandProperties = { //出?超?r,异常调用fallbackMethod方法
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "3000") //3秒钟以内就是正常的业务逻辑
})
public String paymentInfo_TimeOut(Integer id){
int timeNumber = 5; //1 的时候为正常执行当前方法
//throw new RuntimeException(); //异常情况会直接跳过进入paymentInfo_TimeOutHandler
try { TimeUnit.SECONDS.sleep(timeNumber); }catch (Exception e) {e.printStackTrace();}
return "线程池:"+Thread.currentThread().getName()+" paymentInfo_TimeOut,id: "+id+"\t"+"呜呜呜"+" 耗时(秒)"+timeNumber;
}
//备选方法
public String paymentInfo_TimeOutHandler(Integer id){
return "线程池:"+Thread.currentThread().getName()+" 系统繁忙, 请稍候再试 ,id: "+id+"\t"+"哭了哇呜";
}
2,服务调用者(fegin消费者)
对应源码:cloud-consumer-feign-hystrix-order80
yaml文件中添加配置
feign: hystrix: enabled: true #如果处理自身的容错就开启。开启方式与生产端不一样。 client: config: default: connectTimeout: 5000 # feign 的超时设置 readTimeout: 5000 #同时配置一下feign的读取 超时 #超时时间配置,此处全局超时配置时间大于@HystrixProperty配置时间后,@HystrixProperty注解中的超时才生效 hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 10000
主启动类Application上加上注解
@EnableHystrix
业务类controller中加入
//主方法
@GetMapping("/consumer/payment/hystrix/timeout/{id}")
@HystrixCommand(fallbackMethod = "paymentTimeOutFallbackMethod",commandProperties = {
@HystrixProperty(name="execution.isolation.thread.timeoutInMilliseconds", value="1500")//1.5秒钟以内就是正常的业务逻辑
})
public String paymentInfo_TimeOut(@PathVariable("id") Integer id){
String result = paymentHystrixService.paymentInfo_TimeOut(id);
return result;
}
//备用方法
public String paymentTimeOutFallbackMethod(@PathVariable("id") Integer id){
return "我是消费者80,对付支付系统繁忙请10秒钟后再试或者自己运行出错请检查自己,(┬_┬)";
}
3,全局服务降级(feign消费端)
对应源码:cloud-consumer-feign-hystrix-order80
解决主方法一个备用方法的代码冗余。(源码同上)
yaml文件中添加配置
feign: hystrix: enabled: true #如果处理自身的容错就开启。开启方式与生产端不一样。 client: config: default: connectTimeout: 5000 # feign 的超时设置 readTimeout: 5000 #同时配置一下feign的读取 超时 #超时时间配置,此处全局超时配置时间大于@HystrixProperty配置时间后,@HystrixProperty注解中的超时才生效 hystrix: command: default: execution: isolation: thread: timeoutInMilliseconds: 10000
主启动类Application上加上注解
@EnableHystrix
业务类controller中编码
@RestController
@DefaultProperties(defaultFallback="paymentGobalFallbackMethod", commandProperties = {
//如果commandProperties没有对应的内容就会走默认的HystrixCommandProperties中的配置
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1500")})
public class OrderHystrixController {
@Resource
private PaymentHystrixService paymentHystrixService;
//主方法
@GetMapping("/consumer/payment/hystrix/timeout/{id}")
@HystrixCommand //标识走全局的备用策略
public String paymentInfo_TimeOut(@PathVariable("id") Integer id) {
String result = paymentHystrixService.paymentInfo_TimeOut(id);
return result;
}
//全局备用方法
public String paymentGobalFallbackMethod() {
return "Gobal全局备选方法,对象系统繁忙或者已经down机了,请稍后再试";
}
}
4,降级分离(feign消费端)
对应源码:cloud-consumer-feign-hystrix-order80
yaml文件配置
feign: hystrix: enabled: true #如果处理自身的容错就开启。开启方式与生产端不一样
feign调用的接口
@Component
@FeignClient(value = "CLOUD-PROVIDER-HYSTRIX-PAYMENT",fallback = PaymentHystrixFallbackServiceImpl.class) //配置对应的fallback的类
public interface PaymentHystrixFallbackService {
@GetMapping("/payment/hystrix/ok/{id}")
public String paymentInfo_OK(@PathVariable("id") Integer id);
@GetMapping("/payment/hystrix/timeout/{id}")
public String paymentInfo_TimeOut(@PathVariable("id") Integer id);
}
feign调用接口的实现类
/**
* fallback类,用于承载整个类的降级处理
*/
@Component
public class PaymentHystrixFallbackServiceImpl implements PaymentHystrixFallbackService {
@Override
public String paymentInfo_OK(Integer id) {
return "-----PaymentFallbackService fall back-paymentInfo_OK , (┬_┬)";
}
@Override
public String paymentInfo_TimeOut(Integer id) {
return "-----PaymentFallbackService fall back-paymentInfo_TimeOut , (┬_┬)";
}
}
controller中正常调用即可
@Slf4j
@RestController
public class OrderHystrixControllerFallbackClass {
@Resource
private PaymentHystrixFallbackService paymentHystrixFallbackService;
@Value("${server.port}")
private String serverPort;
@GetMapping("/consumer_all/payment/hystrix/ok/{id}")
public String paymentInfo_OK(@PathVariable("id") Integer id) {
String result = paymentHystrixFallbackService.paymentInfo_OK(id);
log.info("*******result:" + result);
return result;
}
@GetMapping("/consumer_all/payment/hystrix/timeout/{id}")
public String paymentInfo_TimeOut(@PathVariable("id") Integer id) {
String result = paymentHystrixFallbackService.paymentInfo_TimeOut(id);
return result;
}
}
三、服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
1,实例(提供端)
源码:cloud-provider-hystrix-payment8001
启动类
@EnableCircuitBreaker //启动熔断
@EnableEurekaClient
@SpringBootApplication
public class CloudHystrixPaymentApplicaiton8001{...}
service
@Service
public class PaymentCircutBreakerService {
//服务熔断
@HystrixCommand(fallbackMethod = "paymentCircuitBreaker_fallback",commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled",value = "true"), //是否开启断路器
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"), //请求次数
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"), //时间范围
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60"), //失败率达到多少后跳闸
})
public String paymentCircuitBreaker(Integer id){
if (id < 0){
throw new RuntimeException("*****id 不能负数");
}
String serialNumber = IdUtil.simpleUUID();
return Thread.currentThread().getName()+"\t"+"调用成功,流水号:"+serialNumber;
}
public String paymentCircuitBreaker_fallback(@PathVariable("id") Integer id){
return "id 不能负数,请稍候再试,(┬_┬)/~~ id: " +id;
}
}
controller
//===服务熔断
@GetMapping("/payment/circuit/{id}")
public String paymentCircuitBreaker(@PathVariable("id") Integer id){
String result = paymentCircutBreakerService.paymentCircuitBreaker(id);
log.info("*******result:"+result);
return result;
}
测试
http://localhost:8001/payment/circuit/-1 //多次调用报错就会开启熔断,此时再调用正确发现不会立马返回正确结果 http://localhost:8001/payment/circuit/1
2,服务熔断原理
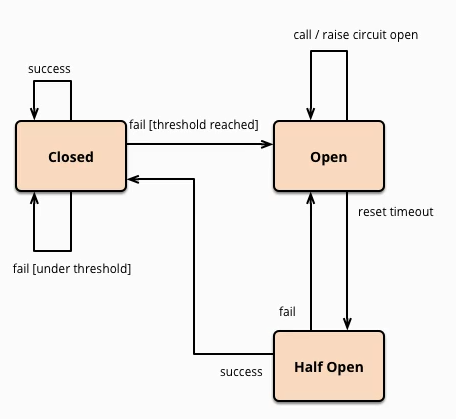
a)熔断类型
熔断打开:请求不在进行调用当前服务,内部设置始终一般为MTTR(平均故障处理时间),当打开时长达到所设时钟则进入熔断状态。
熔断关闭:熔断关闭不会对服务进行熔断。
熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断。
b)断路器开启条件
@HystrixCommand(fallbackMethod = "paymentCircuitBreaker_fallback",commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled",value = "true"), //是否开启断路器
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"), //请求次数
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "10000"), //时间范围
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60"), //失败率达到多少后跳闸
})
涉及到断路器的是哪个重要参数:快照时间窗口、请求总数阈值、错误百分比阈值。
1)快照时间:断路器确定是否打开需要统计一些请求和错误数据,而统计的时间范围就是快照时间窗,默认为最近的10秒。
2)请求总数阈值:在快照时间窗内,必须满足请求总数阈值才有资格熔断。默认为20,意味着在10秒内,如果该hystrix命令的调用总次数不足20次,即使所有的请求都超时或其他原因失败,断路器都不会打开。
3)错误百分比阈值:当请求总数在快照时间窗内超过阈值,比如发生了30次调用,如果在这30次调用中,有15次发生了超时异常,也就是超过50%的错误百分比,在默认设定50%阈值情况下,这时候就会将断路器打开。
c)断路器开启后续
1,再有请求调用的时候,将不会调用主逻辑,而是直接调用降级fallback。通过断路器,实现了自动地发现错误并将降级逻辑切换为主逻辑,减少响应延迟的效果。
2,原来的主逻辑如何恢复:当断路器打开,对主逻辑进行熔断之后,hystrix会启动一个休眠时间窗,在这个窗内,降级逻辑是临时的成为主逻辑;当休眠时间窗到期,断路器会进入半开状态,释放一次请求到原来的主逻辑上,如果此时请求正常返回,那么断路器将继续闭合,主逻辑恢复,如果这次请求依然有问题,断路器继续进入打开状态,休眠时间窗重新计时。
d)各种参数
HystrixCommand:
commandKey:用来标识一个 Hystrix 命令,默认会取被注解的方法名。需要注意:Hystrix 里同一个键的唯一标识并不包括 groupKey,建议取一个独一二无的名字,防止多个方法之间因为键重复而互相影响。 groupKey:一组 Hystrix 命令的集合, 用来统计、报告,默认取类名,可不配置。 threadPoolKey:用来标识一个线程池,如果没设置的话会取 groupKey,很多情况下都是同一个类内的方法在共用同一个线程池,如果两个共用同一线程池的方法上配置了同样的属性,在第一个方法被执行后线程池的属性就固定了,所以属性会以第一个被执行的方法上的配置为准。 commandProperties:与此命令相关的属性。 threadPoolProperties:与线程池相关的属性, observableExecutionMode:当 Hystrix 命令被包装成 RxJava 的 Observer 异步执行时,此配置指定了 Observable 被执行的模式,默认是 ObservableExecutionMode.EAGER,Observable 会在被创建后立刻执行,而 ObservableExecutionMode.EAGER模式下,则会产生一个 Observable 被 subscribe 后执行。我们常见的命令都是同步执行的,此配置项可以不配置。 ignoreExceptions:默认 Hystrix 在执行方法时捕获到异常时执行回退,并统计失败率以修改熔断器的状态,而被忽略的异常则会直接抛到外层,不会执行回退方法,也不会影响熔断器的状态。 raiseHystrixExceptions:当配置项包括 HystrixRuntimeException 时,所有的未被忽略的异常都会被包装成 HystrixRuntimeException,配置其他种类的异常好像并没有什么影响。 fallbackMethod:方法执行时熔断、错误、超时时会执行的回退方法,需要保持此方法与 Hystrix 方法的签名和返回值一致。 defaultFallback:默认回退方法,当配置 fallbackMethod 项时此项没有意义,另外,默认回退方法不能有参数,返回值要与 Hystrix方法的返回值相同。
commandProperties:
线程隔离(Isolation) execution.isolation.strategy: 配置请求隔离的方式,有 threadPool(线程池,默认)和 semaphore(信号量)两种,信号量方式高效但配置不灵活,我们一般采用 Java 里常用的线程池方式。 execution.timeout.enabled:是否给方法执行设置超时,默认为 true。 execution.isolation.thread.timeoutInMilliseconds:方法执行超时时间,默认值是 1000,即 1秒,此值根据业务场景配置。 execution.isolation.thread.interruptOnTimeout: execution.isolation.thread.interruptOnCancel:是否在方法执行超时/被取消时中断方法。需要注意在 JVM 中我们无法强制中断一个线程,如果 Hystrix 方法里没有处理中断信号的逻辑,那么中断会被忽略。 execution.isolation.semaphore.maxConcurrentRequests:默认值是 10,此配置项要在 execution.isolation.strategy 配置为 semaphore 时才会生效,它指定了一个 Hystrix 方法使用信号量隔离时的最大并发数,超过此并发数的请求会被拒绝。信号量隔离的配置就这么一个,也是前文说信号量隔离配置不灵活的原因。
统计器(Metrics) metrics.rollingStats.timeInMilliseconds:此配置项指定了窗口的大小,单位是 ms,默认值是 1000,即一个滑动窗口默认统计的是 1s 内的请求数据。 metrics.healthSnapshot.intervalInMilliseconds:它指定了健康数据统计器(影响 Hystrix 熔断)中每个桶的大小,默认是 500ms,在进行统计时,Hystrix 通过 metrics.rollingStats.timeInMilliseconds / metrics.healthSnapshot.intervalInMilliseconds 计算出桶数,在窗口滑动时,每滑过一个桶的时间间隔时就统计一次当前窗口内请求的失败率。 metrics.rollingStats.numBuckets:Hystrix 会将命令执行的结果类型都统计汇总到一块,给上层应用使用或生成统计图表,此配置项即指定了,生成统计数据流时滑动窗口应该拆分的桶数。此配置项最易跟上面的 metrics.healthSnapshot.intervalInMilliseconds 搞混,认为此项影响健康数据流的桶数。 此项默认是 10,并且需要保持此值能被 metrics.rollingStats.timeInMilliseconds 整除。 metrics.rollingPercentile.enabled:是否统计方法响应时间百分比,默认为 true 时,Hystrix 会统计方法执行的 1%,10%,50%,90%,99% 等比例请求的平均耗时用以生成统计图表。 metrics.rollingPercentile.timeInMilliseconds:统计响应时间百分比时的窗口大小,默认为 60000,即一分钟。 metrics.rollingPercentile.numBuckets:统计响应时间百分比时滑动窗口要划分的桶用,默认为6,需要保持能被metrics.rollingPercentile.timeInMilliseconds 整除。 metrics.rollingPercentile.bucketSize:统计响应时间百分比时,每个滑动窗口的桶内要保留的请求数,桶内的请求超出这个值后,会覆盖最前面保存的数据。默认值为 100,在统计响应百分比配置全为默认的情况下,每个桶的时间长度为 10s = 60000ms / 6,但这 10s 内只保留最近的 100 条请求的数据。
熔断器(Circuit Breaker) circuitBreaker.enabled:是否启用熔断器,默认为 true; circuitBreaker.forceOpen: circuitBreaker.forceClosed:是否强制启用/关闭熔断器,强制启用关闭都想不到什么应用的场景,保持默认值,不配置即可。 circuitBreaker.requestVolumeThreshold:启用熔断器功能窗口时间内的最小请求数。试想如果没有这么一个限制,我们配置了 50% 的请求失败会打开熔断器,窗口时间内只有 3 条请求,恰巧两条都失败了,那么熔断器就被打开了,5s 内的请求都被快速失败。此配置项的值需要根据接口的 QPS 进行计算,值太小会有误打开熔断器的可能,值太大超出了时间窗口内的总请求数,则熔断永远也不会被触发。建议设置为 QPS * 窗口秒数 * 60%。 circuitBreaker.errorThresholdPercentage:在通过滑动窗口获取到当前时间段内 Hystrix 方法执行的失败率后,就需要根据此配置来判断是否要将熔断器打开了。 此配置项默认值是 50,即窗口时间内超过 50% 的请求失败后会打开熔断器将后续请求快速失败。 circuitBreaker.sleepWindowInMilliseconds:熔断器打开后,所有的请求都会快速失败,但何时服务恢复正常就是下一个要面对的问题。熔断器打开时,Hystrix 会在经过一段时间后就放行一条请求,如果这条请求执行成功了,说明此时服务很可能已经恢复了正常,那么会将熔断器关闭,如果此请求执行失败,则认为服务依然不可用,熔断器继续保持打开状态。此配置项指定了熔断器打开后经过多长时间允许一次请求尝试执行,默认值是 5000。
其他(Context/Fallback) requestCache.enabled:是否启用请求结果缓存。默认是 true,但它并不意味着我们的每个请求都会被缓存。缓存请求结果和从缓存中获取结果都需要我们配置 cacheKey,并且在方法上使用 @CacheResult 注解声明一个缓存上下文。 requestLog.enabled:是否启用请求日志,默认为 true。 fallback.enabled:是否启用方法回退,默认为 true 即可。 fallback.isolation.semaphore.maxConcurrentRequests:回退方法执行时的最大并发数,默认是10,如果大量请求的回退方法被执行时,超出此并发数的请求会抛出 REJECTED_SEMAPHORE_FALLBACK 异常。
threadPoolProperties:
coreSize:核心线程池的大小,默认值是 10,一般根据 QPS * 99% cost + redundancy count 计算得出。 allowMaximumSizeToDivergeFromCoreSize:是否允许线程池扩展到最大线程池数量,默认为 false; maximumSize:线程池中线程的最大数量,默认值是 10,此配置项单独配置时并不会生效,需要启用 allowMaximumSizeToDivergeFromCoreSize 项。 maxQueueSize:作业队列的最大值,默认值为 -1,设置为此值时,队列会使用 SynchronousQueue,此时其 size 为0,Hystrix 不会向队列内存放作业。如果此值设置为一个正的 int 型,队列会使用一个固定 size 的 LinkedBlockingQueue,此时在核心线程池内的线程都在忙碌时,会将作业暂时存放在此队列内,但超出此队列的请求依然会被拒绝。 queueSizeRejectionThreshold:由于 maxQueueSize 值在线程池被创建后就固定了大小,如果需要动态修改队列长度的话可以设置此值,即使队列未满,队列内作业达到此值时同样会拒绝请求。此值默认是 5,所以有时候只设置了 maxQueueSize 也不会起作用。 keepAliveTimeMinutes:由上面的 maximumSize,我们知道,线程池内核心线程数目都在忙碌,再有新的请求到达时,线程池容量可以被扩充为到最大数量,等到线程池空闲后,多于核心数量的线程还会被回收,此值指定了线程被回收前的存活时间,默认为 2,即两分钟。
四、Hystrix dashboard
源码:cloud-consumer-hystrix-dashboard9001
1,yaml文件
#指定端口号即可 server: port: 9001
2,application启动类
@SpringBootApplication
@EnableHystrixDashboard
public class HystrixDashboardMain9001 {
public static void main(String[] args) {
SpringApplication.run(HystrixDashboardMain9001.class,args);
}
}
3,被监控类(provider服务)
pom文件
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>
application启动类中添加
//SpringCloud升级方便使用hystrix的dashboard监控
@Bean
public ServletRegistrationBean getServlet(){
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
4,启动并使用
访问地址:http://localhost:9001/hystrix

应用说明

到此这篇关于解析SpringCould中的Hystrix的文章就介绍到这了,更多相关SpringCould中的Hystrix内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/197215/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)