
目标网址:梨视频
然后我们找到科技这一页:https://www.pearvideo.com/category_8。其实你要哪一页都行,你喜欢就行。嘿嘿…
这是动态网站,所以咱们直奔network 然后去到XHR:
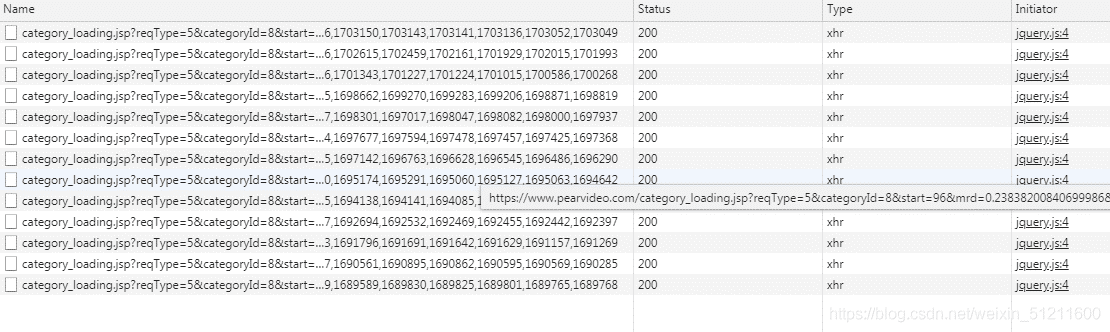
找规律,这个应该不难,我就直接贴网址上来咯,想要锻炼的可以找找看哈:
https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=8&start=0
这个就是我们要找的目标网址啦,后面的0就代表页数,让打开这个网页发现是静态网页,这最好搞啦,直接上:

代码如下:
import requests
import parsel,re
import os
target = "https://www.pearvideo.com/videoStatus.jsp?contId="
url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0"
res = requests.get(url)
res.encoding="utf-8"
html = parsel.Selector(res.text)
lists = html.xpath('/html/body/li/div/a/@href').getall()
for each in lists:
print("https://www.pearvideo.com/"+each)
output;
https://www.pearvideo.com/video_1703486
https://www.pearvideo.com/video_1703189
https://www.pearvideo.com/video_1703161
https://www.pearvideo.com/video_1702880
https://www.pearvideo.com/video_1702773
...
顺利拿到,然后进入播放页面,却发现找不到MP4视频,怎么办?经过我一番努力(扯掉了几十根头发后)发现,它在另外一个网址里面
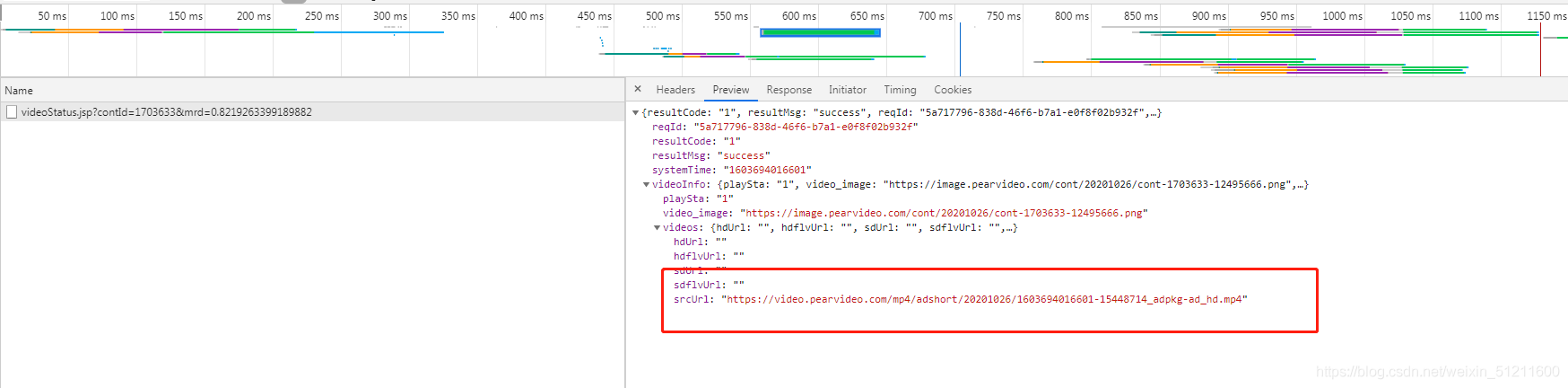
咋办?当然要想办法把这个网址搞到手啦,仔细分析下,发现这个网址非常陌生呀,唯一稍微熟悉点的就是那串数字了,前面我们拿到播放页的网址后面那串数字和这个对比,完全是一模一样的,这样的话那就好搞了,咱们直接用拼接的方式把它接上去就可以了,看代码:
for each in lists:
url_num = each.replace('video_',"")
urls = target+url_num
print(urls)
``
```python
output:
https://www.pearvideo.com/videoStatus.jsp?contId=1703486
https://www.pearvideo.com/videoStatus.jsp?contId=1703189
https://www.pearvideo.com/videoStatus.jsp?contId=1703161
https://www.pearvideo.com/videoStatus.jsp?contId=1702880
https://www.pearvideo.com/videoStatus.jsp?contId=1702773
https://www.pearvideo.com/videoStatus.jsp?contId=1702633
...
出来了,好像稍微有点不一样,后面那啥&mrd=***************** 没有,怎么办?没有就不要呗,看过我发的百度图片那篇的朋友都懂,网址里面有些东西是不需要的,纯粹是搞咱们这些玩爬虫的,恶心咱们。不过没办法,毕竟是咱们要去爬人家的数据的。
网址问题解决了,但是点进去一看,发现这东东:

恩,很明显,是遇到反爬机制了,这个好搞,要什么给什么就行,代码如下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': 'https://www.pearvideo.com/video_'+ str(url_num)
}
html = requests.get(urls,headers=headers).text
print(html)

搞定!!
最后我们看一下MP4能不能播放:

西八!404!!恩,这里就稍微有点麻烦了,还得找数据,把里面的时间戳改成 ‘cont-数字‘,感觉写了好多,手都有点累了,我就直接上代码了:
import requests
import parsel,re
import os
target = "https://www.pearvideo.com/videoStatus.jsp?contId="
url = "https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0"
res = requests.get(url)
res.encoding="utf-8"
html = parsel.Selector(res.text)
lists = html.xpath('/html/body/li/div/a/@href').getall()
# print(lists[2:])
# 提取视频后面的数字,数字是最重要的,需要传给 Referer 和 urls
for each in lists:
url_num = each.replace('video_',"")
urls = target+url_num
# print(urls)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'Referer': 'https://www.pearvideo.com/video_'+ str(url_num)
}
html = requests.get(urls,headers=headers).text
cont = 'cont-' + str(url_num)
# 提取 mp4 视频
srcUrl = re.findall(f'"srcUrl":"(.*?)"',html)[0]
# 替换视频里面的时间戳,改为可以真正播放的数据
new_url = srcUrl.replace(srcUrl.split("-")[0].split("/")[-1],cont)
print(new_url)
# 使用视频后缀当视频名称
filename = srcUrl.split("/")[-1]
# 保存到本地
with open("./images/"+filename,"wb") as f:
f.write(requests.get(new_url).content)

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/199219/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)