
我们平时生活的娱乐中,看电影是大部分小伙伴都喜欢的事情。周围的人总会有意无意的在谈论,有什么影片上映,好不好看之类的话题,没事的时候谈论电影是非常不错的话题。那么,一些好看的影片如果不去电影院的话,在其他地方看都会有大大小小的限制,今天小编就教大家用python中的scrapy获取影片的办法吧。
1. 创建项目
运行命令:
scrapy startproject myfrist(your_project_name)
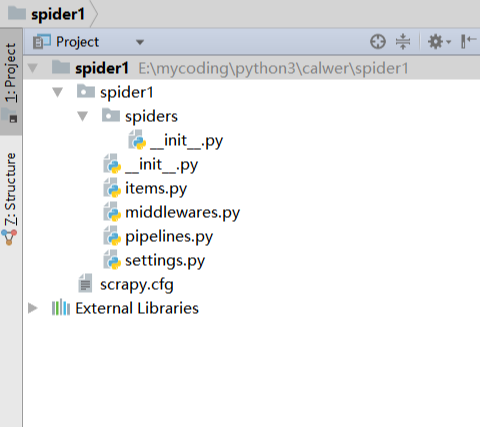
文件说明: 名称 | 作用 --|-- scrapy.cfg | 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中) items.py | 设置数据存储模板,用于结构化数据,如:Django的Model pipelines | 数据处理行为,如:一般结构化的数据持久化 settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 spiders | 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
2 编写 spdier
在spiders目录中新建 daidu_spider.py 文件
2.1 注意
爬虫文件需要定义一个类,并继承scrapy.spiders.Spider
必须定义name,即爬虫名,如果没有name,会报错。因为源码中是这样定义的
2.2 编写内容
在这里可以告诉 scrapy 。要如何查找确切数据,这里必须要定义一些属性
name: 它定义了蜘蛛的唯一名称
allowed_domains: 它包含了蜘蛛抓取的基本URL;
start-urls: 蜘蛛开始爬行的URL列表;
parse(): 这是提取并解析刮下数据的方法;
下面的代码演示了蜘蛛代码的样子:
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'douban'
allwed_url = 'douban.com'
start_urls = [
'https://movie.douban.com/top250/'
]
def parse(self, response):
movie_name = response.xpath("//div[@class='item']//a/span[1]/text()").extract()
movie_core = response.xpath("//div[@class='star']/span[2]/text()").extract()
yield {
'movie_name':movie_name,
'movie_core':movie_core
}
到此这篇关于python爬虫用scrapy获取影片的实例分析的文章就介绍到这了,更多相关python爬虫如何用scrapy获取影片内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/200398/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)