
当我们需要有一批货物需要存放时,最好的方法就是有一个仓库进行保管。我们可以把URL管理器看成一个收集了数据的大仓库,而下载器就是这个仓库货物的搬运者。关于下载器的问题,我们暂且不谈。本篇主要讨论的是在url管理器中,我们遇到重复的数据应该如何识别出来,避免像仓库一样过多的囤积相同的货物。听起来是不是很有意思,下面我们一起进入今天的学习。
URL管理器到底应该具有哪些功能?
- URL下载器应该包含两个仓库,分别存放没有爬取过的链接和已经爬取过的链接。
- 应该有一些函数负责往上述两个仓库里添加链接
- 应该有一个函数负责从新url仓库中随机取出一条链接以便下载器爬取
- URL下载器应该能识别重复的链接,已经爬取过的链接就不需要放进仓库了
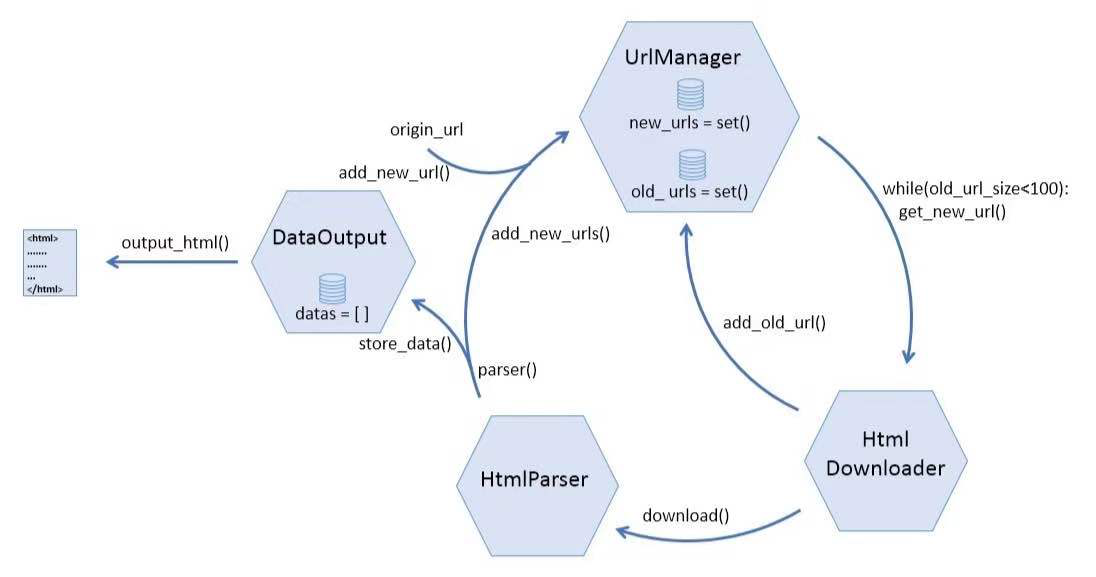
如果一个URL管理器能够具有以上4点功能,也算是“麻雀虽小,五脏俱全”了。然而,链接去重这个功能,应该怎么实现?
链接去重是关系爬虫效率的一个比较关键的点,尤其是爬取的数据量极大的时候。在这个简单的例子里,由于数据量较少,我们不需要太过复杂的算法,直接借助于python的set()函数即可,该函数可以生成一个集合对象,其元素不可重复。
根据以上分析,URL管理器的w代码如下:
'''
UrlManager
class UrlManager(object):
def __init__(self):
#初始化的时候就生成两个url仓库
self.new_urls = set()
self.old_urls = set()
#判断新url仓库中是否还有没有爬取的url
def has_new_url(self):
return len(self.new_urls)
#从new_url仓库获取一个新的url
def get_new_url(self):
return self.new_urls.pop()
def add_new_url(self, url): #这个函数后来用不到了……
'''
将一条url添加到new_urls仓库中
parm url: str
return:
if url is None:
return
#只需要判断old_urls中没有该链接即可,new_urls在添加的时候会自动去重
if url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
将多条url添加到new_urls仓库中
parm url: 可迭代对象
print "start add_new_urls"
if urls is None or len(urls) == 0:
for url in urls:
self.add_new_url(url)
def add_old_url(self, url):
self.old_urls.add(url)
print "add old url succefully"
#获取已经爬取过的url的数目
def old_url_size(self):
return len(self.old_urls)
尝试过以上代码的小伙伴,已经成功学会用url管理器筛选重复的数据了。相信大家经过今天的学习,已经能够了解url的基本功能和简单的使用。
到此这篇关于python爬虫中url管理器去重操作实例的文章就介绍到这了,更多相关python爬虫中url管理器如何去重内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/201011/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)