
我把自己以往的文章汇总成为了 Github ,欢迎各位大佬 star
https://github.com/crisxuan/bestJavaer
我们在日常开发中经常会使用到诸如泛型、自动拆箱和装箱、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等,我们只觉得用的很爽,因为这些特性能够帮助我们减轻开发工作量;但我们未曾认真研究过这些特性的本质是什么,那么这篇文章,cxuan 就来为你揭开这些特性背后的真相。
语法糖
在聊之前我们需要先了解一下 语法糖 的概念:语法糖(Syntactic sugar),也叫做糖衣语法,是英国科学家发明的一个术语,通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会,真是又香又甜。
语法糖指的是计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。因为 Java 代码需要运行在 JVM 中,JVM 是并不支持语法糖的,语法糖在程序编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。所以在 Java 中,真正支持语法糖的是 Java 编译器,真是换汤不换药,万变不离其宗,关了灯都一样。。。。。。
下面我们就来认识一下 Java 中的这些语法糖
泛型
泛型是一种语法糖。在 JDK1.5 中,引入了泛型机制,但是泛型机制的本身是通过类型擦除 来实现的,在 JVM 中没有泛型,只有普通类型和普通方法,泛型类的类型参数,在编译时都会被擦除。泛型并没有自己独特的 Class类型。如下代码所示
List<Integer> aList = new ArrayList(); List<String> bList = new ArrayList(); System.out.println(aList.getClass() == bList.getClass());
List<Ineger> 和 List<String> 被认为是不同的类型,但是输出却得到了相同的结果,这是因为,泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。但是,如果将一个 Integer 类型的数据放入到 List<String> 中或者将一个 String 类型的数据放在 List<Ineger> 中是不允许的。
如下图所示
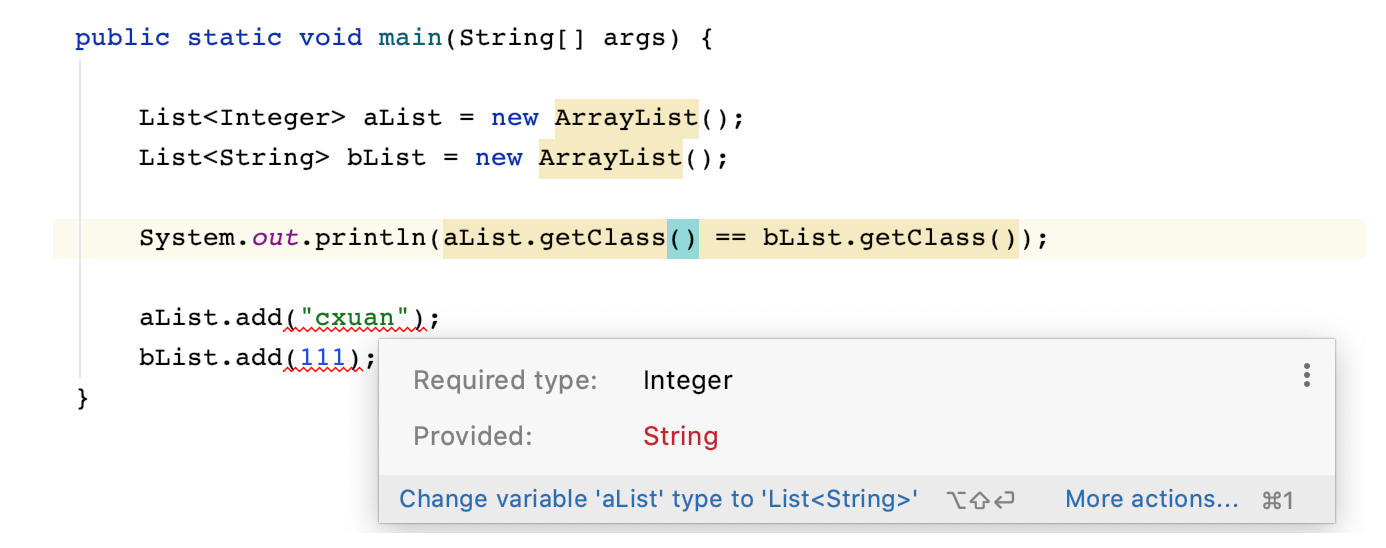
无法将一个 Integer 类型的数据放在 List<String> 和无法将一个 String 类型的数据放在 List<Integer> 中是一样会编译失败。
自动拆箱和自动装箱
自动拆箱和自动装箱是一种语法糖,它说的是八种基本数据类型的包装类和其基本数据类型之间的自动转换。简单的说,装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。
我们先来了解一下基本数据类型的包装类都有哪些
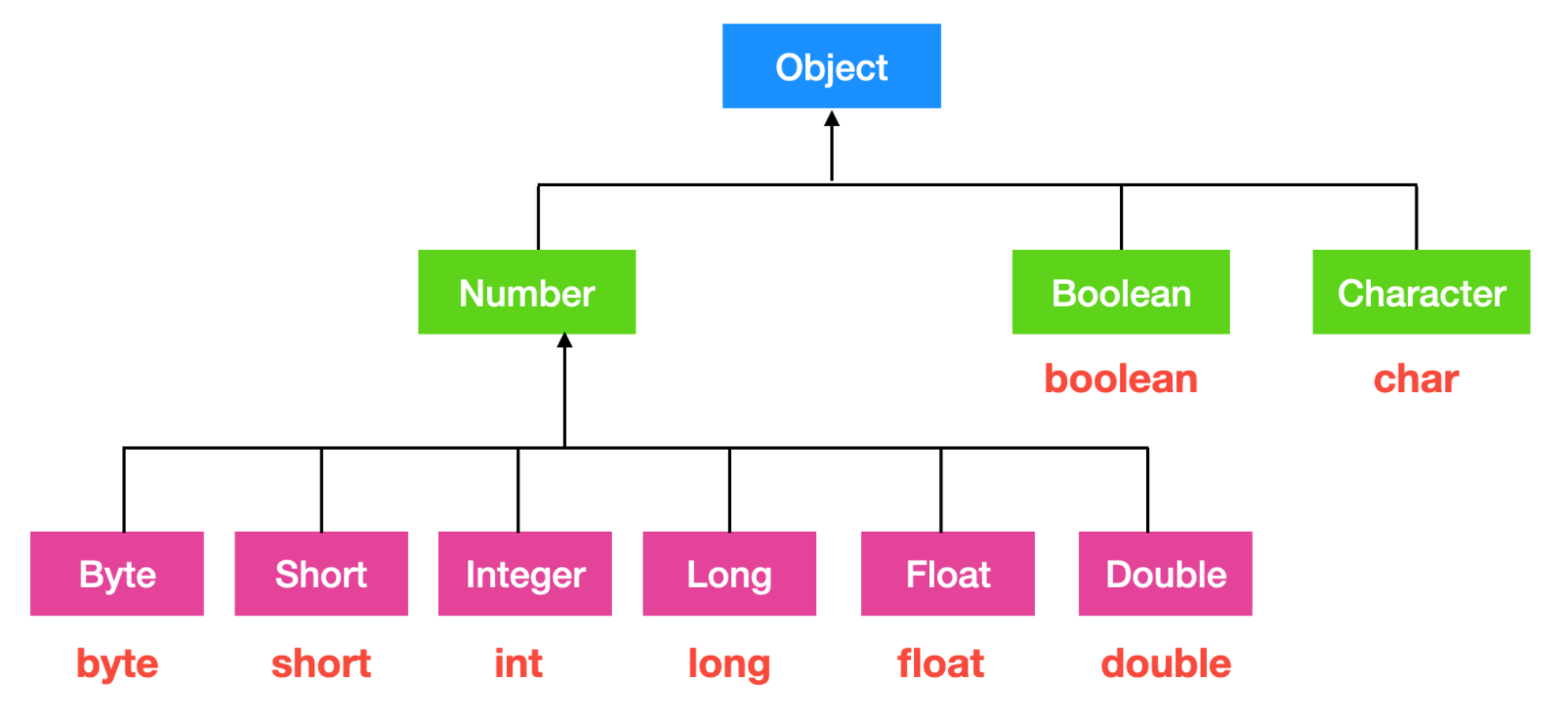
也就是说,上面这些基本数据类型和包装类在进行转换的过程中会发生自动装箱/拆箱,例如下面代码
Integer integer = 66; // 自动拆箱 int i1 = integer; // 自动装箱
上面代码中的 integer 对象会使用基本数据类型来进行赋值,而基本数据类型 i1 却把它赋值给了一个对象类型,一般情况下是不能这样操作的,但是编译器却允许我们这么做,这其实就是一种语法糖。这种语法糖使我们方便我们进行数值运算,如果没有语法糖,在进行数值运算时,你需要先将对象转换成基本数据类型,基本数据类型同时也需要转换成包装类型才能使用其内置的方法,无疑增加了代码冗余。
那么自动拆箱和自动装箱是如何实现的呢?
其实这背后的原理是编译器做了优化。将基本类型赋值给包装类其实是调用了包装类的 valueOf() 方法创建了一个包装类再赋值给了基本类型。
int i1 = Integer.valueOf(1);
而包装类赋值给基本类型就是调用了包装类的 xxxValue() 方法拿到基本数据类型后再进行赋值。
Integer i1 = new Integer(1).intValue();
我们使用 javap -c 反编译一下上面的自动装箱和自动拆箱来验证一下

可以看到,在 Code 2 处调用 invokestatic 的时候,相当于是编译器自动为我们添加了一下 Integer.valueOf 方法从而把基本数据类型转换为了包装类型。
在 Code 7 处调用了 invokevirtual 的时候,相当于是编译器为我们添加了 Integer.intValue() 方法把 Integer 的值转换为了基本数据类型。
枚举
我们在日常开发中经常会使用到 enum 和 public static final ... 这类语法。那么什么时候用 enum 或者是 public static final 这类常量呢?好像都可以。
但是在 Java 字节码结构中,并没有枚举类型。枚举只是一个语法糖,在编译完成后就会被编译成一个普通的类,也是用 Class 修饰。这个类继承于 java.lang.Enum,并被 final 关键字修饰。
我们举个例子来看一下
public enum School {
STUDENT,
TEACHER;
}
这是一个 School 的枚举,里面包括两个字段,一个是 STUDENT ,一个是 TEACHER,除此之外并无其他。
下面我们使用 javap 反编译一下这个 School.class 。反编译完成之后的结果如下

从图中我们可以看到,枚举其实就是一个继承于 java.lang.Enum 类的 class 。而里面的属性 STUDENT 和 TEACHER 本质也就是 public static final 修饰的字段。这其实也是一种编译器的优化,毕竟 STUDENT 要比 public static final School STUDENT 的美观性、简洁性都要好很多。
除此之外,编译器还会为我们生成两个方法,values() 方法和 valueOf 方法,这两个方法都是编译器为我们添加的方法,通过使用 values() 方法可以获取所有的 Enum 属性值,而通过 valueOf 方法用于获取单个的属性值。
注意,Enum 的 values() 方法不属于 JDK API 的一部分,在 Java 源码中,没有 values() 方法的相关注释。
用法如下
public enum School {
STUDENT("Student"),
TEACHER("Teacher");
private String name;
School(String name){
this.name = name;
}
public String getName() {
return name;
}
public static void main(String[] args) {
System.out.println(School.STUDENT.getName());
School[] values = School.values();
for(School school : values){
System.out.println("name = "+ school.getName());
}
}
}
内部类
内部类是 Java 一个小众 的特性,我之所以说小众,并不是说内部类没有用,而是我们日常开发中其实很少用到,但是翻看 JDK 源码,发现很多源码中都有内部类的构造。比如常见的 ArrayList 源码中就有一个 Itr 内部类继承于 Iterator 类;再比如 HashMap 中就构造了一个 Node 继承于 Map.Entry<K,V> 来表示 HashMap 的每一个节点。
Java 语言中之所以引入内部类,是因为有些时候一个类只想在一个类中有用,不想让其在其他地方被使用,也就是对外隐藏内部细节。
内部类其实也是一个语法糖,因为其只是一个编译时的概念,一旦编译完成,编译器就会为内部类生成一个单独的class 文件,名为 outer$innter.class。
下面我们就根据一个示例来验证一下。
public class OuterClass {
private String label;
class InnerClass {
public String linkOuter(){
return label = "inner";
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
System.out.println(innerClass.linkOuter());
}
}
上面这段编译后就会生成两个 class 文件,一个是 OuterClass.class ,一个是 OuterClass$InnerClass.class ,这就表明,外部类可以链接到内部类,内部类可以修改外部类的属性等。
我们来看一下内部类编译后的结果
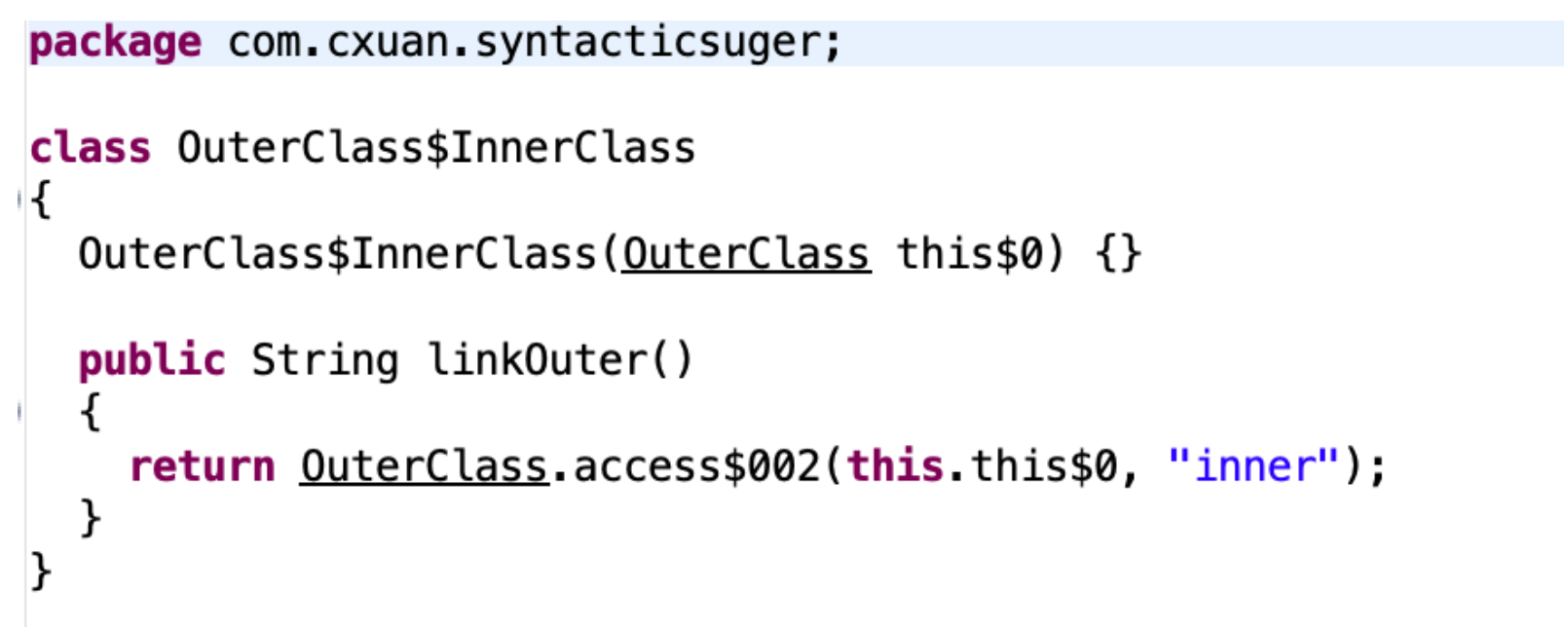
如上图所示,内部类经过编译后的 linkOuter() 方法会生成一个指向外部类的 this 引用,这个引用就是连接外部类和内部类的引用。
变长参数
变长参数也是一个比较小众的用法,所谓变长参数,就是方法可以接受长度不定确定的参数。一般我们开发不会使用到变长参数,而且变长参数也不推荐使用,它会使我们的程序变的难以处理。但是我们有必要了解一下变长参数的特性。
其基本用法如下
public class VariableArgs {
public static void printMessage(String... args){
for(String str : args){
System.out.println("str = " + str);
}
}
public static void main(String[] args) {
VariableArgs.printMessage("l","am","cxuan");
}
}
变长参数也是一种语法糖,那么它是如何实现的呢?我们可以猜测一下其内部应该是由数组构成,否则无法接受多个值,那么我们反编译看一下是不是由数组实现的。

可以看到,printMessage() 的参数就是使用了一个数组来接收,所以千万别被变长参数忽悠了!
变长参数特性是在 JDK 1.5 中引入的,使用变长参数有两个条件,一是变长的那一部分参数具有相同的类型,二是变长参数必须位于方法参数列表的最后面。
增强 for 循环
为什么有了普通的 for 循环后,还要有增强 for 循环呢?想一下,普通 for 循环你不是需要知道遍历次数?每次还需要知道数组的索引是多少,这种写法明显有些繁琐。增强 for 循环与普通 for 循环相比,功能更强并且代码更加简洁,你无需知道遍历的次数和数组的索引即可进行遍历。
增强 for 循环的对象要么是一个数组,要么实现了 Iterable 接口。这个语法糖主要用来对数组或者集合进行遍历,其在循环过程中不能改变集合的大小。
public static void main(String[] args) {
String[] params = new String[]{"hello","world"};
//增强for循环对象为数组
for(String str : params){
System.out.println(str);
}
List<String> lists = Arrays.asList("hello","world");
//增强for循环对象实现Iterable接口
for(String str : lists){
System.out.println(str);
}
}
经过编译后的 class 文件如下
public static void main(String[] args) {
String[] params = new String[]{"hello", "world"};
String[] lists = params;
int var3 = params.length;
//数组形式的增强for退化为普通for
for(int str = 0; str < var3; ++str) {
String str1 = lists[str];
System.out.println(str1);
}
List var6 = Arrays.asList(new String[]{"hello", "world"});
Iterator var7 = var6.iterator();
//实现Iterable接口的增强for使用iterator接口进行遍历
while(var7.hasNext()) {
String var8 = (String)var7.next();
System.out.println(var8);
}
}
如上代码所示,如果对数组进行增强 for 循环的话,其内部还是对数组进行遍历,只不过语法糖把你忽悠了,让你以一种更简洁的方式编写代码。
而对继承于 Iterator 迭代器进行增强 for 循环遍历的话,相当于是调用了 Iterator 的 hasNext() 和 next() 方法。
Switch 支持字符串和枚举
switch 关键字原生只能支持整数类型。如果 switch 后面是 String 类型的话,编译器会将其转换成 String 的hashCode 的值,所以其实 switch 语法比较的是 String 的 hashCode 。
如下代码所示
public class SwitchCaseTest {
public static void main(String[] args) {
String str = "cxuan";
switch (str){
case "cuan":
System.out.println("cuan");
break;
case "xuan":
System.out.println("xuan");
break;
case "cxuan":
System.out.println("cxuan");
break;
default:
break;
}
}
}
我们反编译一下,看看我们的猜想是否正确
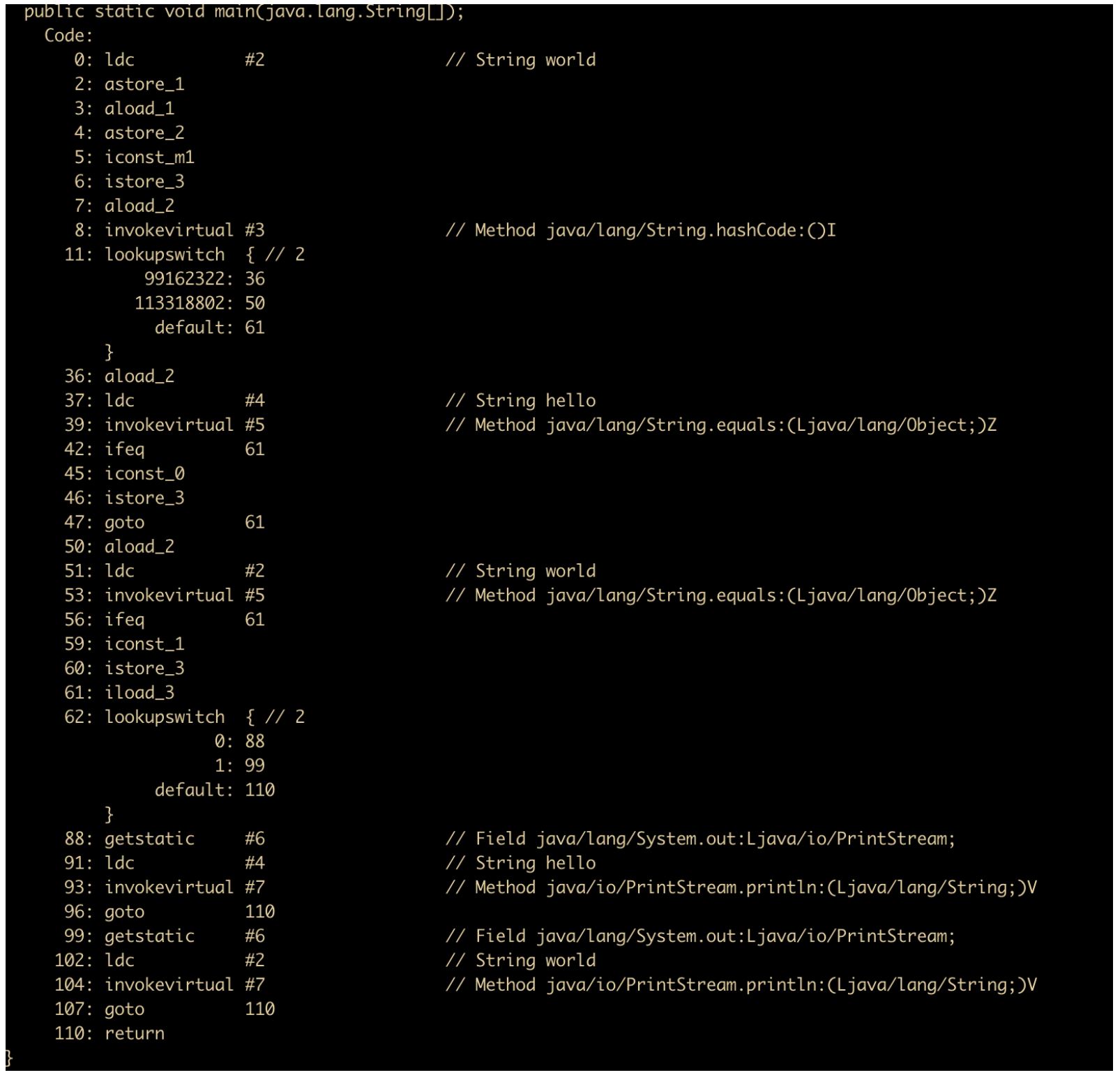
根据字节码可以看到,进行 switch 的实际是 hashcode 进行判断,然后通过使用 equals 方法进行比较,因为字符串有可能会产生哈希冲突的现象。
条件编译
这个又是让小伙伴们摸不着头脑了,什么是条件编译呢?其实,如果你用过 C 或者 C++ 你就知道可以通过预处理语句来实现条件编译。
那么什么是条件编译呢?
一般情况下,源程序中所有的行都参加编译。但有时希望对其中一部分内容只在满足一定条件下才进行编译,即对一部分内容指定编译条件,这就是 条件编译(conditional compile)。
#define DEBUG #IFDEF DEBUUG /* code block 1 */ #ELSE /* code block 2 */ #ENDIF
但是在 Java 中没有预处理和宏定义这些内容,那么我们想实现条件编译,应该怎样做呢?
使用 final + if 的组合就可以实现条件编译了。如下代码所示
public static void main(String[] args) {
final boolean DEBUG = true;
if (DEBUG) {
System.out.println("Hello, world!");
} else {
System.out.println("nothing");
}
}
这段代码会发生什么?我们反编译看一下

我们可以看到,我们明明是使用了 if ...else 语句,但是编译器却只为我们编译了 DEBUG = true 的条件,
所以,Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的,编译器不会为我们编译分支为 false 的代码。
断言
你在 Java 中使用过断言作为日常的判断条件吗?
断言:也就是所谓的 assert 关键字,是 jdk 1.4 后加入的新功能。它主要使用在代码开发和测试时期,用于对某些关键数据的判断,如果这个关键数据不是你程序所预期的数据,程序就提出警告或退出。当软件正式发布后,可以取消断言部分的代码。它也是一个语法糖吗?现在我不告诉你,我们先来看一下 assert 如何使用。
//这个成员变量的值可以变,但最终必须还是回到原值5
static int i = 5;
public static void main(String[] args) {
assert i == 5;
System.out.println("如果断言正常,我就被打印");
}
如果要开启断言检查,则需要用开关 -enableassertions 或 -ea 来开启。其实断言的底层实现就是 if 判断,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。
assert 断言就是通过对布尔标志位进行了一个 if 判断。
try-with-resources
JDK 1.7 开始,java引入了 try-with-resources 声明,将 try-catch-finally 简化为 try-catch,这其实是一种语法糖,在编译时会进行转化为 try-catch-finally 语句。新的声明包含三部分:try-with-resources 声明、try 块、catch 块。它要求在 try-with-resources 声明中定义的变量实现了 AutoCloseable 接口,这样在系统可以自动调用它们的 close 方法,从而替代了 finally 中关闭资源的功能。
如下代码所示
public class TryWithResourcesTest {
public static void main(String[] args) {
try(InputStream inputStream = new FileInputStream(new File("xxx"))) {
inputStream.read();
}catch (Exception e){
e.printStackTrace();
}
}
}
我们可以看一下 try-with-resources 反编译之后的代码

可以看到,生成的 try-with-resources 经过编译后还是使用的 try...catch...finally 语句,只不过这部分工作由编译器替我们做了,这样能让我们的代码更加简洁,从而消除样板代码。
字符串相加
这个想必大家应该都知道,字符串的拼接有两种,如果能够在编译时期确定拼接的结果,那么使用 + 号连接的字符串会被编译器直接优化为相加的结果,如果编译期不能确定拼接的结果,底层会直接使用 StringBuilder 的 append 进行拼接,如下图所示。
public class StringAppendTest {
public static void main(String[] args) {
String s1 = "I am " + "cxuan";
String s2 = "I am " + new String("cxuan");
String s3 = "I am ";
String s4 = "cxuan";
String s5 = s3 + s4;
}
}
上面这段代码就包含了两种字符串拼接的结果,我们反编译看一下
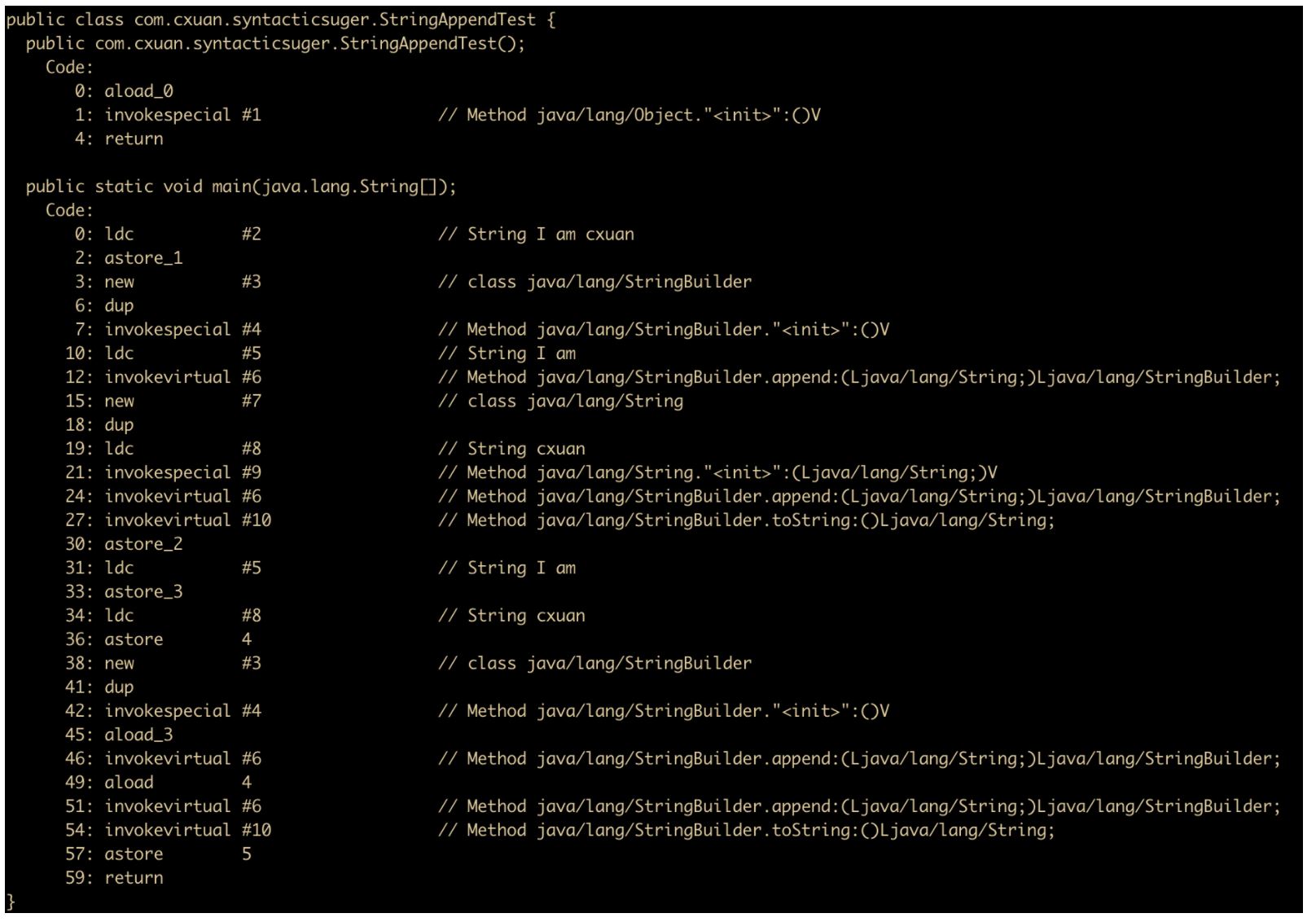
首先来看一下 s1 ,s1 因为 = 号右边是两个常量,所以两个字符串拼接会被直接优化成为 I am cxuan。而 s2 由于在堆空间中分配了一个 cxuan 对象,所以 + 号两边进行字符串拼接会直接转换为 StringBuilder ,调用其 append 方法进行拼接,最后再调用 toString() 方法转换成字符串。
而由于 s5 进行拼接的两个对象在编译期不能判定其拼接结果,所以会直接使用 StringBuilder 进行拼接。
学习语法糖的意义
互联网时代,有很多标新立异的想法和框架层出不穷,但是,我们对于学习来说应该抓住技术的核心。然而,软件工程是一门协作的艺术,对于工程来说如何提高工程质量,如何提高工程效率也是我们要关注的,既然这些语法糖能辅助我们以更好的方式编写备受欢迎的代码,我们程序员为什么要 抵制 呢?
语法糖也是一种进步,这就和你写作文似的,大白话能把故事讲明白的它就没有语言优美、酣畅淋漓的把故事讲生动的更令人喜欢。
我们要在敞开怀抱拥抱变化的同时也要掌握其 屠龙之技。
到此这篇关于Java 中的语法糖,真甜的文章就介绍到这了,更多相关Java 语法糖内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/201625/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)