
下载小姐姐图片并保存
- 请求的地址
- 伪装
- 定位元素
- 下载图片
- 保存好了
下面开始我们的实战,这个是我们今天访问的url:
url = 'http://pic.netbian.com/4kmeinv/'
1,先把包给导进来:
import requests from selenium.webdriver import Chrome,ChromeOptions import os
不知道怎么导包的看我的第一篇,附上链接:
https://www.jb51.net/article/204774.htm
2, 接下来就开始发送请求
#请求的url
url = 'http://pic.netbian.com/4kmeinv/'
#进行伪装
headers = {
"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
#发起请求
response = requests.get(url=url,headers=headers)
#手动设定响应数据的编码格式
response.encoding = 'utf-8'
page_text = response.text
#这个就是再后台上面运行那个浏览器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
option.add_experimental_option('excludeSwitches',['enable-automation'])
#这里也要输入
browser = Chrome(options=option)
browser.get(url)
相信看过我上篇的都知道这些,那就废话不多说,定位元素:
3,定位:
先看下代码再说:
li = browser.find_elements_by_xpath('//*[@id="main"]/div[3]/ul/li')
老样子,分为三步,第一步选中所选的图片?>copy xpath?>ctrl+f -->粘贴进去可以看到是1of1,但明显我们要的是这个页面上所有的图片,所以呀,只需要改一下就可以啦,将tr[1],里面的包括括号删掉就可以。
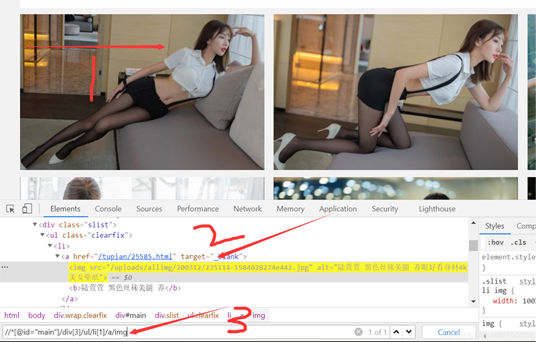
这样的话就是整个页面内所有的图片啦,

4,创建文件以保存我们所要的图片:
#创建一个文件夹
if not os.path.exists('./小美女图'):
os.mkdir('./小美女图')
然后再循环一下就好啦:
for i in li:
img_src = i.find_element_by_xpath('./a/img').get_attribute('src')
img_name = i.find_element_by_xpath('./a/img').get_attribute('alt')+'.jpg'
至于为什么要这么写,可以看一下我的上一篇博客:
https://www.jb51.net/article/204771.htm
5,保存
img_data = requests.get(url=img_src,headers=headers).content img_path = '小美女图/'+img_name with open(img_path,'wb') as fp: fp.write(img_data) print(img_name,'下载成功!!!')
最后的结果哈哈哈哈:这个也不存在什么图片尺寸过大啥的,如果错了,多半是你元素没有定位好。
到此这篇关于详解用selenium来下载小姐姐图片并保存的文章就介绍到这了,更多相关selenium 下载图片内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/204773/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)