
整理了一套模板,全注释了,这个难点终于克服了
from PIL import Image
import pandas as pd
import numpy as np
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
import os
#放文件的路径
dir_path= './97/train/'
csv_path='./97/train.csv'
class Mydataset(Dataset):
#传递数据路径,csv路径 ,数据增强方法
def __init__(self, dir_path,csv, transform=None, target_transform=None):
super(Mydataset, self).__init__()
#一个个往列表里面加绝对路径
self.path = []
#读取csv
self.data = pd.read_csv(csv)
#对标签进行硬编码,例如0 1 2 3 4,把字母变成这个
colorMap = {elem: index + 1 for index, elem in enumerate(set(self.data["label"]))}
self.data['label'] = self.data['label'].map(colorMap)
#创造空的label准备存放标签
self.num = int(self.data.shape[0]) # 一共多少照片
self.label = np.zeros(self.num, dtype=np.int32)
#迭代得到数据路径和标签一一对应
for index, row in self.data.iterrows():
self.path.append(os.path.join(dir_path,row['filename']))
self.label[index] = row['label'] # 将数据全部读取出来
#训练数据增强
self.transform = transform
#验证数据增强在这里没用
self.target_transform = target_transform
#最关键的部分,在这里使用前面的方法
def __getitem__(self, index):
img =Image.open(self.path[index]).convert('RGB')
labels = self.label[index]
#在这里做数据增强
if self.transform is not None:
img = self.transform(img) # 转化tensor类型
return img, labels
def __len__(self):
return len(self.data)
#数据增强的具体内容
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize(150),
transforms.CenterCrop(150),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
#加载数据
train_data = Mydataset(dir_path=dir_path,csv=csv_path, transform=transform)
trainloader = DataLoader(train_data, batch_size=16, shuffle=True, num_workers=0)
#迭代训练
for i_batch,batch_data in enumerate(trainloader):
image,label=batch_data
补充:pytorch—定义自己的数据集及加载训练
笔记:pytorch Conv2d 的宽高公式理解,pytorch 使用自己的数据集并且加载训练
一、pypi 镜像使用帮助
pypi 镜像每 5 分钟同步一次。
临时使用
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
注意,simple 不能少, 是 https 而不是 http
设为默认
修改 ~/.config/pip/pip.conf (Linux), %APPDATA%\pip\pip.ini (Windows 10) 或 $HOME/Library/Application Support/pip/pip.conf (macOS) (没有就创建一个), 修改 index-url至tuna,例如
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple
pip 和 pip3 并存时,只需修改 ~/.pip/pip.conf。
二、pytorch Conv2d 的宽高公式理解

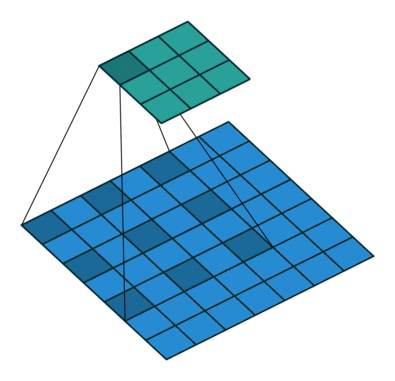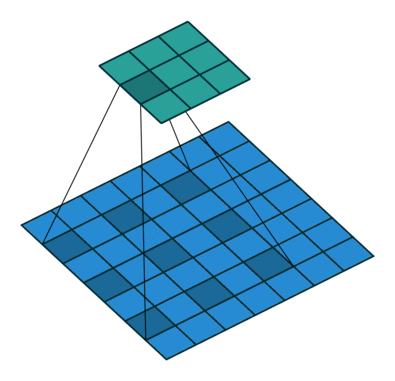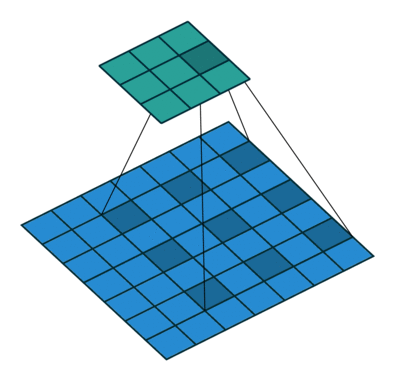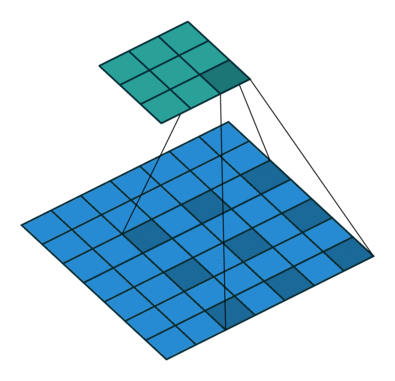

三、pytorch 使用自己的数据集并且加载训练
import os
import sys
import numpy as np
import cv2
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
import time
import random
import csv
from PIL import Image
def createImgIndex(dataPath, ratio):
'''
读取目录下面的图片制作包含图片信息、图片label的train.txt和val.txt
dataPath: 图片目录路径
ratio: val占比
return:label列表
'''
fileList = os.listdir(dataPath)
random.shuffle(fileList)
classList = [] # label列表
# val 数据集制作
with open('data/val_section1015.csv', 'w') as f:
writer = csv.writer(f)
for i in range(int(len(fileList)*ratio)):
row = []
if '.jpg' in fileList[i]:
fileInfo = fileList[i].split('_')
sectionName = fileInfo[0] + '_' + fileInfo[1] # 切面名+标准与否
row.append(os.path.join(dataPath, fileList[i])) # 图片路径
if sectionName not in classList:
classList.append(sectionName)
row.append(classList.index(sectionName))
writer.writerow(row)
f.close()
# train 数据集制作
with open('data/train_section1015.csv', 'w') as f:
writer = csv.writer(f)
for i in range(int(len(fileList) * ratio)+1, len(fileList)):
row = []
if '.jpg' in fileList[i]:
fileInfo = fileList[i].split('_')
sectionName = fileInfo[0] + '_' + fileInfo[1] # 切面名+标准与否
row.append(os.path.join(dataPath, fileList[i])) # 图片路径
if sectionName not in classList:
classList.append(sectionName)
row.append(classList.index(sectionName))
writer.writerow(row)
f.close()
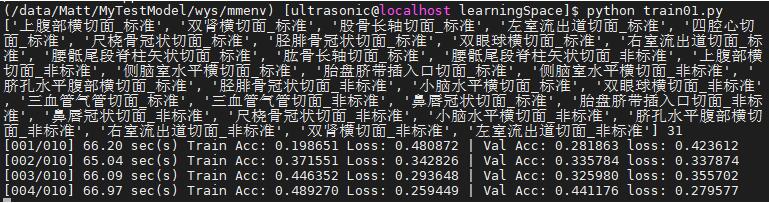
print(classList, len(classList))
return classList
def default_loader(path):
'''定义读取文件的格式'''
return Image.open(path).resize((128, 128),Image.ANTIALIAS).convert('RGB')
class MyDataset(Dataset):
'''Dataset类是读入数据集数据并且对读入的数据进行索引'''
def __init__(self, txt, transform=None, target_transform=None, loader=default_loader):
super(MyDataset, self).__init__() #对继承自父类的属性进行初始化
fh = open(txt, 'r') #按照传入的路径和txt文本参数,以只读的方式打开这个文本
reader = csv.reader(fh)
imgs = []
for row in reader:
imgs.append((row[0], int(row[1]))) # (图片信息,lable)
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index):
'''用于按照索引读取每个元素的具体内容'''
# fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中row[0]和row[1]的信息
fn, label = self.imgs[index]
img = self.loader(fn)
if self.transform is not None:
img = self.transform(img) #数据标签转换为Tensor
return img, label
def __len__(self):
'''返回数据集的长度'''
return len(self.imgs)
class Model(nn.Module):
def __init__(self, classNum=31):
super(Model, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 维度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, classNum)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)
def train(train_set, train_loader, val_set, val_loader):
model = Model()
loss = nn.CrossEntropyLoss() # 因为是分类任务,所以loss function使用 CrossEntropyLoss
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # optimizer 使用 Adam
num_epoch = 10
# 开始训练
for epoch in range(num_epoch):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
model.train() # train model会开放Dropout和BN
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 用 optimizer ? model ??档 gradient ?w零
train_pred = model(data[0]) # 利用 model 的 forward 函数返回预测结果
batch_loss = loss(train_pred, data[1]) # 计算 loss
batch_loss.backward() # tensor(item, grad_fn=<NllLossBackward>)
optimizer.step() # 以 optimizer 用 gradient 更新参数
train_acc += np.sum(np.argmax(train_pred.data.numpy(), axis=1) == data[1].numpy())
train_loss += batch_loss.item()
model.eval()
with torch.no_grad(): # 不跟踪梯度
for i, data in enumerate(val_loader):
# data = [imgData, labelList]
val_pred = model(data[0])
batch_loss = loss(val_pred, data[1])
val_acc += np.sum(np.argmax(val_pred.data.numpy(), axis=1) == data[1].numpy())
val_loss += batch_loss.item()
# 打印结果
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, num_epoch, time.time() - epoch_start_time, \
train_acc / train_set.__len__(), train_loss / train_set.__len__(), val_acc / val_set.__len__(),
val_loss / val_set.__len__()))
if __name__ == '__main__':
dirPath = '/data/Matt/QC_images/test0916' # 图片文件目录
createImgIndex(dirPath, 0.2) # 创建train.txt, val.txt
root = os.getcwd() + '/data/'
train_data = MyDataset(txt=root+'train_section1015.csv', transform=transforms.ToTensor())
val_data = MyDataset(txt=root+'val_section1015.csv', transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_data, batch_size=6, shuffle=True, num_workers = 4)
val_loader = DataLoader(dataset=val_data, batch_size=6, shuffle=False, num_workers = 4)
# 开始训练模型
train(train_data, train_loader, val_data, val_loader)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自学编程网。如有错误或未考虑完全的地方,望不吝赐教。

- 本文固定链接: https://zxbcw.cn/post/206998/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)