
简单实现ip代理,为了不卖广告,
请自行准备一个ip代理的平台
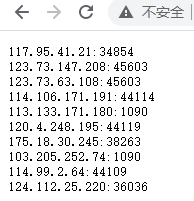
例如我用的这个平台,每次提取10个ip

从上面可以看到数据格式是文本,换行是\r\n,访问链接之后大概就是长这样的,scrapy里面的ip需要加上前缀http://
例如:http://117.95.41.21:34854
OK,那现在已经准备好了ip了,先给你们屡一下思路。
ip池和计数器放在setting文件
第一次请求的时候要填满ip池,所以在爬虫文件的start_requests函数下手
更换ip的地方是middlewares的下载器中间件类的process_request函数,因为每个请求发起前都会经过这个函数
首先是setting文件,其实就是加两句代码
count = {'count': 0}
ipPool = []
还有就是开启下载器中间件,注意是下面那个download的类,中间件的process_request函数的时候才能生效
下载器中间件的process_request函数,进行ip代理和固定次数更还ip代理池
# 记得导包
from 你的项目.settings import ipPool, count
import random
import requests
def process_request(self, request, spider):
# 随机选中一个ip
ip = random.choice(ipPool)
print('当前ip', ip, '-----', count['count'])
# 更换request的ip----------这句是重点
request.meta['proxy'] = ip
# 如果循环大于某个值,就清理ip池,更换ip的内容
if count['count'] > 50:
print('-------------切换ip------------------')
count['count'] = 0
ipPool.clear()
ips = requests.get('你的ip获取的地址')
for ip in ips.text.split('\r\n'):
ipPool.append('http://' + ip)
# 每次访问,计数器+1
count['count'] += 1
return None
最后就是爬虫文件的start_requests函数,就是第一次发请求前要先填满ip池的ip
# 记得导包
from 你的项目.settings import ipPool
import random
import requests
def start_requests(self):
# 第一次请求发起前先填充一下ip池
ips = requests.get('你的ip获取的地址')
for ip in ips.text.split('\r\n'):
ipPool.append('http://' + ip)
简单的ip代理以及固定次数就更换ip池就完成了
到此这篇关于超简单的scrapy实现ip动态代理与更换ip的方法实现的文章就介绍到这了,更多相关scrapy ip动态代理与更换ip内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/208042/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)