
在学习Python爬虫部分,需要你已经学过Python基础和前端的相关知识。
开发环境介绍:
- window10 操作系统
- Python解释器3.8
- 集成开发环境pycharm
数据的来源及作用
数据的来源有哪些?
- 用户产生的数据: 百度指数
- 政府统计的数据: 政府数据
- 数据管理公司: 聚合数据
- 自己爬取的数据: 爬取网站上的某些视频
数据的作用
- 数据分析
- 智能产品的练习数据
- 其他(比如买卖)
爬虫的相关概念
a) 爬虫的概念
爬虫就是应用程序,从网上下载各种各样的资源。
换句话说就是使用编程语言编写一个用于爬虫web或者app的数据应用程序。
怎么爬取数据呢?
- 找到要爬取的目标网站,发起请求
- 分析url是如何变化的和提取有用的url
- 提取有用的信息
爬虫什么数据都可以爬吗?
当然不能,需要遵守一定的规则和协议
可以看一下京东的:
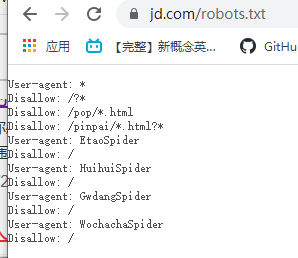
有些是允许的,有些是不允许的。
b) 爬虫分类
- 通用爬虫
百度等搜索引擎,从一些初始的URL扩展到整个网站,主要为门户站点搜索引起和大型网站服务采集数据
- 聚焦网站爬虫
主题网络爬虫,选择性爬取根据需求相关的页面的网络爬虫
- 增量式网络爬虫
对已经下载的页面采取更新知识和只爬新产生的。
c) 爬虫的原理
- 通用的爬虫原理
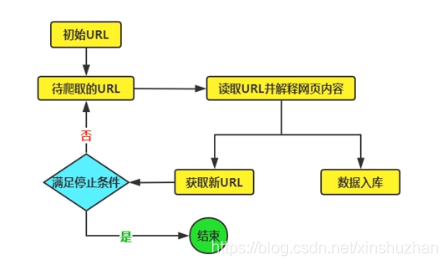
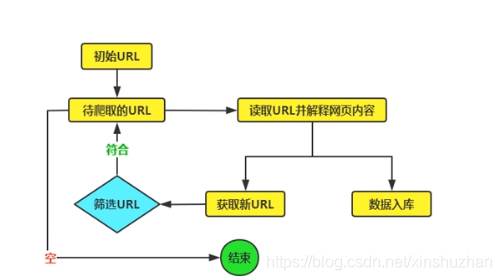
- 聚焦网络爬虫原理
d) 各种语言写爬虫的对比
- php对多线程,异步支持不是很友好,并发能力弱。速度和效率低
- java: 代码量大,而且重构成本比较高,任何改动都会导致大量的改动,而爬虫需要经常修改采集代码
- Python: 开发效率高,代码简洁,支持的模块多,和HTTP请求和html解析模块非常丰富,还有scrapy,scrapy-redis框架,让开发爬虫更简单。
到此这篇关于Python爬虫部分开篇示例讲解的文章就介绍到这了,更多相关Python爬虫部分开篇示例讲解内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/209144/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)