
看代码吧~
hist(data$MEDV,col="grey")#可以看到目标数据的总体分布
legend(35,170,c("min:5","median:21.2","mean:22.51","max:50"),fill=c("lightblue","wheat"))
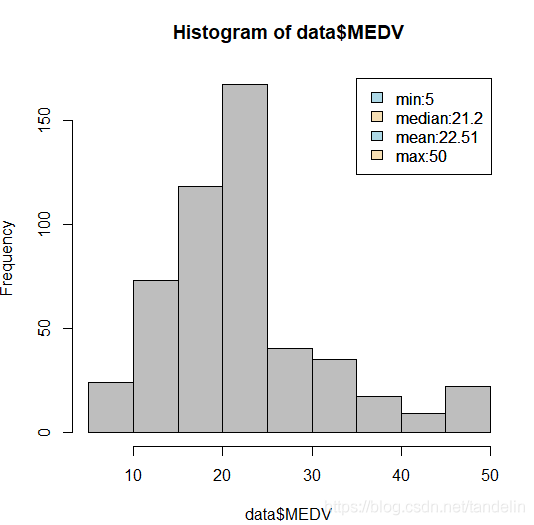
补充:R语言作图——histogram(直方图)
最近小仙同学很是烦恼,本以为自己已经掌握了ggplot2作图的语法,用read.csv(), ggplot()+geom_point()/boxplot()/violinplot()…就可以画遍天下图表,结果却发现到真正画图的时候,还是会出现不少的小问题。

比如小仙最近要画一个直方图,最开始用hist()函数试了一下,看了下形状, 好像因为数据取值范围跨度太大(最大值104,724,最小值30),这个图画出来有点丑,于是决定用ggplot美化一下。
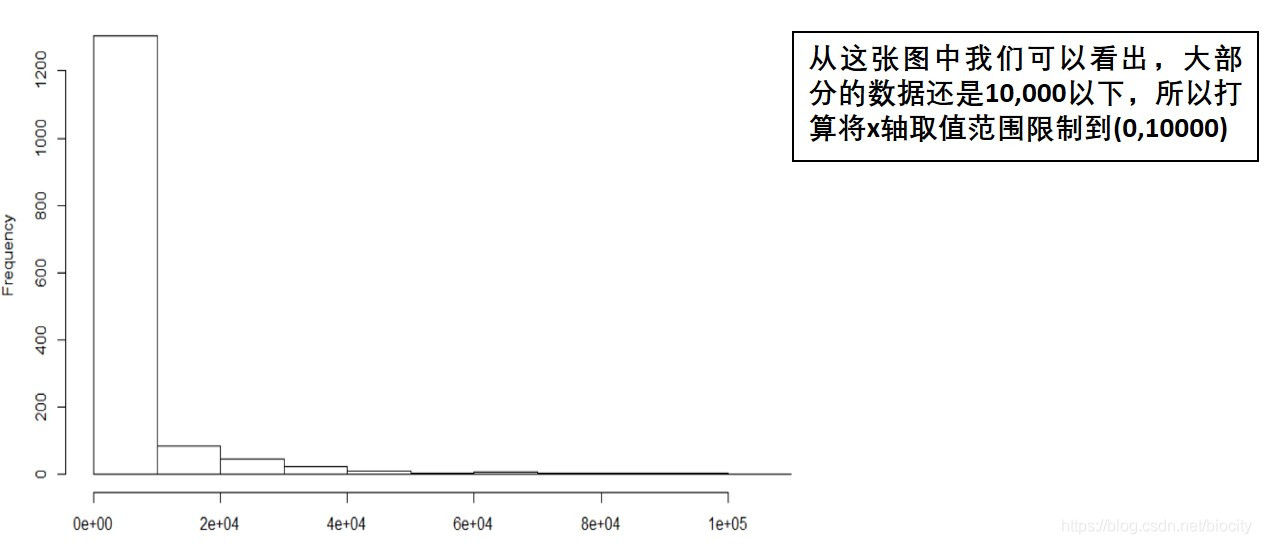
调整之后好看是好看了,但是大家有没有看出什么不对的地方,明明bins=10但是只画出8个格子,之后调整bins的值,每次都会比我指定的值少2个格子。
而且,图中第一个格子(取值范围0-1250)应该有700多个数据,但是图上显示只有不到300个,问题出在哪里呢?
小仙同学百思不得其解。
在geom_histogram()函数中,bins就是用来指定分组数目(格子),为什么总是会少两个?
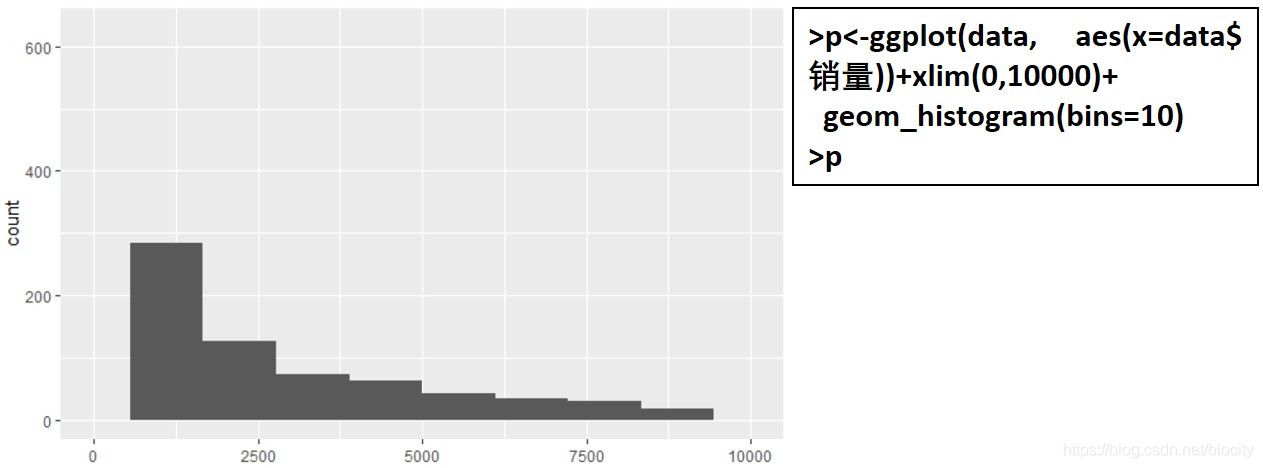
小仙同学考虑到自己能力有限,决定量力而行,另辟蹊径。
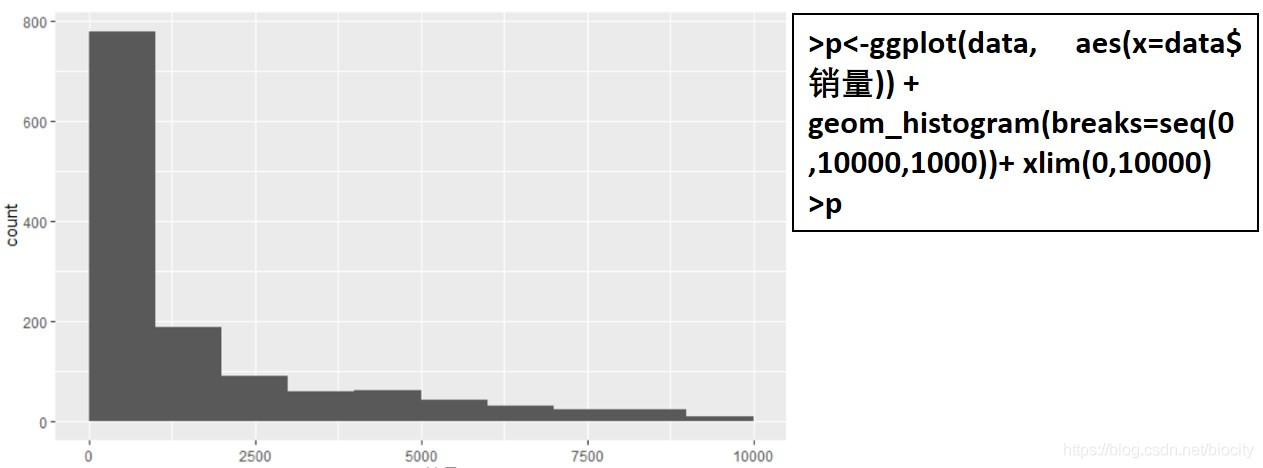
于是设置另外一个参数breaks,终于找回了丢失的格子
经过此事,小仙同学深刻认识到了自己的有限水平,哈哈。不过还是分享一下,希望能帮助到大家。实际的数据可真是比书上的例子难处理呢。
按照惯例写一下整个作图的过程。
Step1. 绘图数据的准备
首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式。
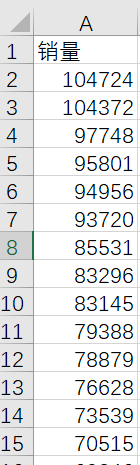
Step2. 绘图数据的读取
data<-read.csv(“your file path”, header = T)
#注释:header=T表示数据中的第一行是列名,如果没有列名就用header=F
Step3.绘图所需package的安装、调用
library(ggplot2)
#注释:package使用之前需要调用
Step4.绘图
p<-ggplot(data, aes(x=data$销量)) + geom_histogram(breaks=seq(0,10000,1000))+ xlim(0,10000) p

以上为个人经验,希望能给大家一个参考,也希望大家多多支持自学编程网。如有错误或未考虑完全的地方,望不吝赐教。

- 本文固定链接: https://zxbcw.cn/post/210031/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)