
似乎因为受这篇文章的影响 http://katemats.com/what-every-programmer-should-know-about-seo/ 于是我也觉得我应该写一个每个程序员必知之SEO,作为一个擅长前端兼SEO的设计师。

搜索引擎是如何工作的
如果你有时间,可以读一下谷歌的框架:http://infolab.stanford.edu/~backrub/google.html
这是一个老的,有些过时纸,但非常平易近人,甚至在我们中间的非白皮书的读者图标微笑什么每个程序员都应该知道的关于搜索引擎优化和他们绝对概念的解释更详细,我只提一笔带过。
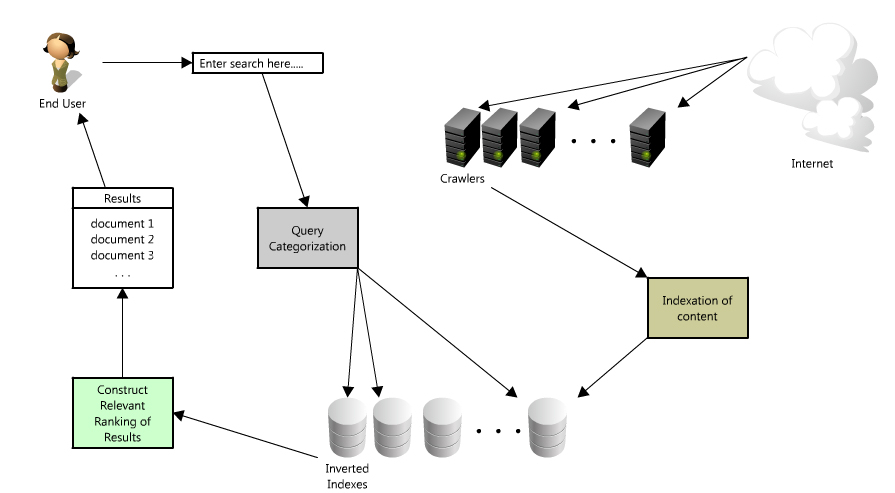
搜索时发生什么了
- 用户输入查询内容
- 查询处理以及分词技术
- 确定搜索意图及返回相关、新鲜的内容
为什么需要SEO
这是一个有趣的问题,答案总会来源于为网站带来更多的流量。
爬虫与索引
我们先看看来自谷歌的爬虫工作的一点内容
抓取是 Googlebot 发现新网页并更新这些网页以将网页添加到 Google 索引中的过程。
我们使用许多计算机来获取(或"抓取")网站上的大量网页。执行获取任务的程序叫做 Googlebot(也被称为漫游器或信息采集软件)。Googlebot 使用算法来进行抓取:计算机程序会确定要抓取的网站、抓取频率以及从每个网站中获取的网页数量。
Google 的抓取过程是根据网页网址的列表进行的,该列表是在之前进行的抓取过程中形成的,且随着网站管理员所提供的站点地图数据不断进行扩充。Googlebot 在访问每个网站时,会检测每个网页上的链接,并将这些链接添加到它要抓取的网页列表中。新建立的网站、对现有网站所进行的更改以及无效链接都会被记录下 来,并用于更新 Google 索引。
也就是如原文所说:
谷歌的爬虫(又或者说蛛蛛)能够抓取你整个网站索引的所有页。
为什么谷歌上可以搜索整个互联网的内容?因为,他解析并存储了。而更有意思的是,他会为同样的内容建立一个索引或者说分类,按照一定的相关性,针对于某个关键词的内容。
PageRank对于一个网站来说是相当重要的,只是这个相比也比较复杂。包括其他网站链接向你的网站,以及流量,当然还有域名等等。
什么样的网站需要SEO?
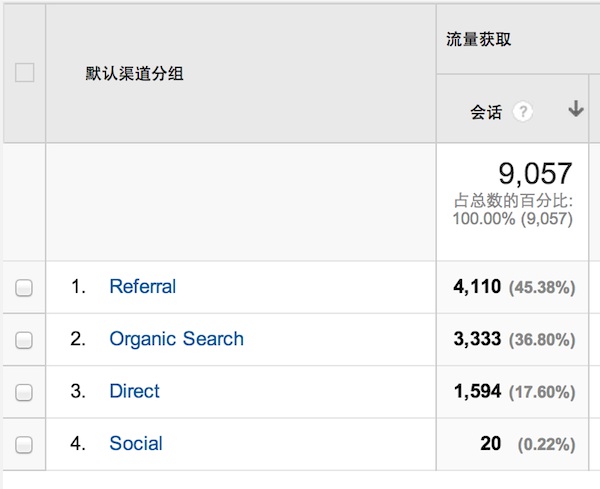
下图是我的博客的流量来源
正常情况下除了像腾讯这类的QQ空间自我封闭的网站外都需要SEO,或者不希望泄露一些用户隐私如Facebook、人人等等
- 如果你和我的网站一样需要靠搜索带来流量
- 如果你只有很少的用户访问,却有很多的内容。
- 如果你是为一个公司、企业工作为以带来业务。
- 。。。
SEO与编程的不同之处
SEO与编程的最大不同之处在于
编程的核心是技术,SEO的核心是内容。
内容才是SEO最重要的组成部分,这也就是腾讯复制不了的东西。
SEO基础知识
确保网站是可以被索引的
一些常见的页面不能被访问的原因
- 隐藏在需要提交的表格中的链接
- 不能解析的JavaScript脚本中的链接
- Flash、Java和其他插件中的链接
- PowerPoint和PDF文件中的链接
- 指向被meta Robtots标签、rel="NoFollow"和robots.txt屏蔽的页面的链接
- 页面上有上几百个链接
- frame(框架结构)和iframe里的链接
对于现在的网站来还有下面的原因,通过来说是因为内容是动态生成的,而不是静态的
- 网站通过WebSocket的方法渲染内容
- 使用诸如Mustache之类的JS模板引擎
什么样的网页可以被索引
- 确保页面可以在没有JavaScript下能被渲染。对于现在JavaScript语言使用越来越多的情况,在使用JS模板引擎的时候也应该注意这样的问题。
- 在用户禁用了JavaScript的情况下,保证所有的链接和页面是可以访问的。
- 确保爬虫可以看到所有的内容。那些用JS动态加载出来的对于爬虫来说是不友好的。
- 使用描述性的锚文本的网页。
- 限制的页面上的链接数量。除去一些分类网站、导航网站之类有固定流量,要不容易被认为垃圾网站。
- 确保页面能被索引。有一指向它的URL。
- URL应该遵循最佳实践。如blog/how-to-driver有更好的可读性。
在正确的地方使用正确的关键词
- 把关键词放在URL中
- 关键词应该是页面的标签
- 带有H1标签
- 图片文件名、ALT属性带有关键词
- 页面文字
- 加粗文字
- Descripiton标签

- 本文固定链接: https://zxbcw.cn/post/2112/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)