
一、什么是负载均衡
负载均衡:建立在现有网络结构之上,它提供了一种廉价有效透明的方法扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性。
现在网站的架构已经从C/S模式转变为B/S模式,C/S模式是有一个专门的客户端,而B/S模式是将浏览器作为客户端。当用户在浏览器上输入一个网址按下回车键后,就会产生一个请求,在远方的服务器会处理这个请求,根据这个请求来生成用户想要的页面,然后将这个页面响应给浏览器,这样用户就能看到他想要看到的东西。我们知道,一台服务器处理数据(请求也是一种数据)的能力是有限的,当有大量的用户同时在浏览器上输入网址并按下回车键后,就会有大量的请求产生,远方的服务器就不得不处理这些请求,由于请求数量过多,服务器处理的效率就会变慢,响应时间就会变长,这样用户就不能在可以忍受的时间内看到自己想看到的东西,严重影响体验效果。更严重一点,如果请求数量超过了这台服务器所能处理的最大请求,服务器就会崩溃,直接导致网站瘫痪。
那么,有什么方法能够解决这个问题呢?答案就是建立一个集群(就是一群服务器),通过集群的力量来提高服务端的数据处理能力,因为一台服务器的处理能力肯定比不上多台服务器的处理能力。
这样我们在来描述一下用户请求页面的过程:首先用户在浏览器输入网址并按下回车键,然后会产生一个请求,远方的服务器会处理这个请求…等等,现在远方有很多服务器,到底哪个服务器来处理这个请求呢,总不能所有的服务器都处理这个请求吧。哪个服务器处理这个请求?大家明白了吧,这就是负载均衡所要解决的问题。回到上边请求页面的过程,这个请求此时会被一台专门的服务器来处理,这台服务器其实就是个集群的老大,他负责把这个请求派给下面哪个小弟(服务器)来处理,处理完之后返回页面用户。当有多个请求同时发生时,集群的老大可以将请求派给不同的小弟,这样处理的效率就会大幅提升,充分发挥集群的力量,至于哪个请求到底派给哪个小弟,这就是调度策略的问题了。
二、实现负载均衡的三种方式
(1)HTTP重定向实现负载均衡
利用HTTP重定向协议实现负载均衡大概工作原理如下图:
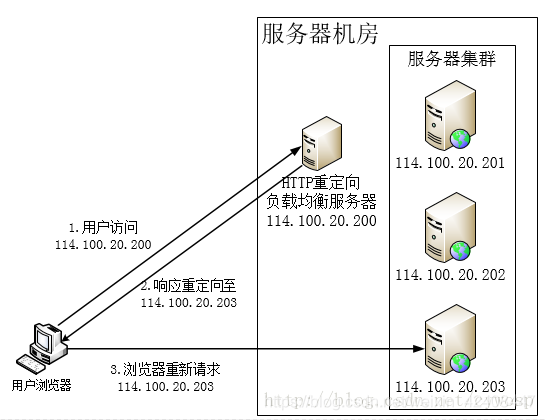
HTTP重定向服务器是一台普通的应用服务器,其唯一个功能就是根据用户的HTTP请求计算出一台真实的服务器地址,并将该服务器地址写入HTTP重定向响应中(重定向响应状态码为302)返回给用户浏览器。用户浏览器在获取到响应之后,根据返回的信息,重新发送一个请求到真实的服务器上。如上图所示,浏览器访问www.apusapp.com,DNS服务器解析到IP地址为114.100.20.200,即HTTP重定向服务器的IP地址。重定向服务器计根据某种负载均衡算法算出真实的服务器地址为114.100.20.203并返回给用户浏览器,用户浏览器得到返回后重新对114.100.20.203发起了请求,最后完成访问。
这种负载均衡方案的有点是比较简单,缺点是浏览器需要两次请求服务器才能完成一次访问,性能较差;同时,重定向服务器本身的处理能力有可能成为瓶颈,整个集群的伸缩性规模有限;使用HTTP返回码302重定向,有可能使搜索引擎判断为SEO作弊,降低搜索排名。因此实践中很少使用这种负载均衡方案来部署。
(2)DNS负载均衡
DNS(Domain Name System)是因特网的一项服务,它作为域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。人们在通过浏览器访问网站时只需要记住网站的域名即可,而不需要记住那些不太容易理解的IP地址。在DNS系统中有一个比较重要的的资源类型叫做主机记录也称为A记录,A记录是用于名称解析的重要记录,它将特定的主机名映射到对应主机的IP地址上。如果你有一个自己的域名,那么要想别人能访问到你的网站,你需要到特定的DNS解析服务商的服务器上填写A记录,过一段时间后,别人就能通过你的域名访问你的网站了。DNS除了能解析域名之外还具有负载均衡的功能,下面是利用DNS工作原理处理负载均衡的工作原理图:
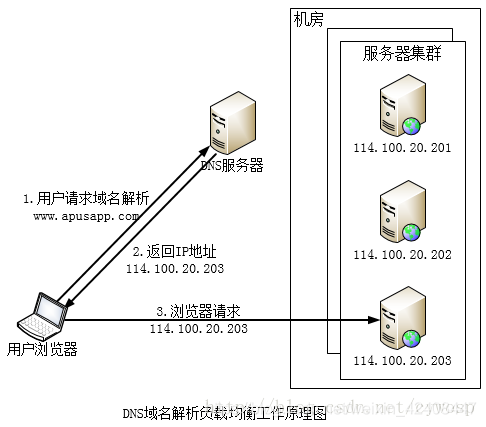
由上图可以看出,在DNS服务器中应该配置了多个A记录,如:
www.apusapp.com IN A 114.100.20.201;
www.apusapp.com IN A 114.100.20.202;
www.apusapp.com IN A 114.100.20.203;
因此,每次域名解析请求都会根据对应的负载均衡算法计算出一个不同的IP地址并返回,这样A记录中配置多个服务器就可以构成一个集群,并可以实现负载均衡。上图中,用户请求www.apusapp.com,DNS根据A记录和负载均衡算法计算得到一个IP地址114.100.20.203,并返回给浏览器,浏览器根据该IP地址,访问真实的物理服务器114.100.20.203。所有这些操作对用户来说都是透明的,用户可能只知道www.apusapp.com这个域名。
DNS域名解析负载均衡有如下优点:
1.将负载均衡的工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦。
2.技术实现比较灵活、方便,简单易行,成本低,使用于大多数TCP/IP应用。
3.对于部署在服务器上的应用来说不需要进行任何的代码修改即可实现不同机器上的应用访问。
4.服务器可以位于互联网的任意位置。
5.同时许多DNS还支持基于地理位置的域名解析,即会将域名解析成距离用户地理最近的一个服务器地址,这样就可以加速用户访问,改善性能。
同时,DNS域名解析也存在如下缺点:
1.目前的DNS是多级解析的,每一级DNS都可能缓存A记录,当某台服务器下线之后,即使修改了A记录,要使其生效也需要较长的时间,这段时间,DNS任然会将域名解析到已下线的服务器上,最终导致用户访问失败。
2.不能够按服务器的处理能力来分配负载。DNS负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异,不能反映服务器当前运行状态,所以其的负载均衡效果并不是太好。
3.可能会造成额外的网络问题。为了使本DNS服务器和其他DNS服务器及时交互,保证DNS数据及时更新,使地址能随机分配,一般都要将DNS的刷新时间设置的较小,但太小将会使DNS流量大增造成额外的网络问题。
事实上,大型网站总是部分使用DNS域名解析,利用域名解析作为第一级负载均衡手段,即域名解析得到的一组服务器并不是实际提供服务的物理服务器,而是同样提供负载均衡服务器的内部服务器,这组内部负载均衡服务器再进行负载均衡,请请求发到真实的服务器上,最终完成请求。
(3)反向代理负载均衡
请求过程:
用户发来的请求都首先要经过反向代理服务器,服务器根据用户的请求要么直接将结果返回给用户,要么将请求交给后端服务器处理,再返回给用户。
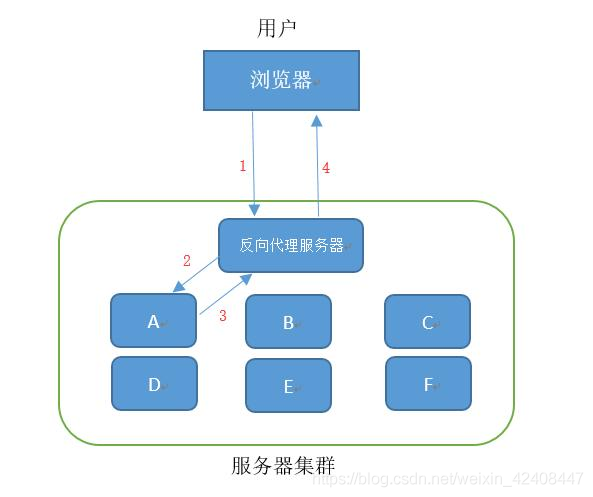
反向代理负载均衡
优点:
隐藏后端服务器。与HTTP重定向相比,反向代理能够隐藏后端服务器,所有浏览器都不会与后端服务器直接交互,从而能够确保调度者的控制权,提升集群的整体性能。
故障转移。与DNS负载均衡相比,反向代理能够更快速地移除故障结点。当监控程序发现某一后端服务器出现故障时,能够及时通知反向代理服务器,并立即将其删除。
合理分配任务 。HTTP重定向和DNS负载均衡都无法实现真正意义上的负载均衡,也就是调度服务器无法根据后端服务器的实际负载情况分配任务。但反向代理服务器支持手动设定每台后端服务器的权重。我们可以根据服务器的配置设置不同的权重,权重的不同会导致被调度者选中的概率的不同。
缺点:
调度者压力过大 。由于所有的请求都先由反向代理服务器处理,那么当请求量超过调度服务器的最大负载时,调度服务器的吞吐率降低会直接降低集群的整体性能。
制约扩展。当后端服务器也无法满足巨大的吞吐量时,就需要增加后端服务器的数量,可没办法无限量地增加,因为会受到调度服务器的最大吞吐量的制约。
三、Ribbon简介
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现。通过Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。Spring Cloud Ribbon虽然只是一个工具类框架,它不像服务注册中心、配置中心、API网关那样需要独立部署,但是它几乎存在于每一个Spring Cloud构建的微服务和基础设施中。因为微服务间的调用,API网关的请求转发等内容,实际上都是通过Ribbon来实现的,包括Feign,它也是基于Ribbon实现的工具。所以,对Spring Cloud Ribbon的理解和使用,对于我们使用Spring Cloud来构建微服务非常重要。
Ribbon是Netflix发布的负载均衡器,它有助于控制HTTP和TCP的客户端的行为。为Ribbon配置服务提供者地址后,Ribbon就可基于某种负载均衡算法,自动地帮助服务消费者去请求。Ribbon默认为我们提供了很多负载均衡算法,例如轮询、随机等。当然,我们也可为Ribbon实现自定义的负载均衡算法。
四、Ribbon的应用
package com.itmuch.cloud.study;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@EnableDiscoveryClient
@SpringBootApplication
public class ConsumerMovieApplication {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
SpringApplication.run(ConsumerMovieApplication.class, args);
}
}
剩下的在controller中使用restTemplate中使用即可。
五、Ribbon和Feign的区别
(1)启动类使用的注解不同,Ribbon用的是@RibbonClient,Feign用的是@EnableFeignClients。
(2)服务的指定位置不同,Ribbon是在@RibbonClient注解上声明,Feign则是在定义抽象方法的接口中使用@FeignClient声明。
(3)调用方式不同,Ribbon需要自己构建http请求,模拟http请求然后使用RestTemplate发送给其他服务,步骤相当繁琐。Feign则是在Ribbon的基础上进行了一次改进,采用接口的方式,将需要调用的其他服务的方法定义成抽象方法即可,不需要自己构建http请求。不过要注意的是抽象方法的注解、方法签名要和提供服务的方法完全一致。
到此这篇关于浅谈SpringCloud之Ribbon的文章就介绍到这了,更多相关SpringCloud之Ribbon内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/211689/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)