
前言
java中经常需要用到多线程来处理一些业务,我不建议单纯使用继承Thread或者实现Runnable接口的方式来创建线程,那样势必有创建及销毁线程耗费资源、线程上下文切换问题。
同时创建过多的线程也可能引发资源耗尽的风险,这个时候引入线程池比较合理,方便线程任务的管理。
java中涉及到线程池的相关类均在jdk1.5开始的java.util.concurrent包中,涉及到的几个核心类及接口包括:
Executor、Executors、ExecutorService、ThreadPoolExecutor、FutureTask、Callable、Runnable等。
一、线程池的创建及重要参数
线程池可以自动创建也可以手动创建,自动创建体现在Executors工具类中,常见的可以创建newFixedThreadPool、newCachedThreadPool、newSingleThreadExecutor、newScheduledThreadPool;
手动创建体现在可以灵活设置线程池的各个参数,体现在代码中即ThreadPoolExecutor类构造器上各个实参的不同:
public static ExecutorService newFixedThreadPool(int var0) {
return new ThreadPoolExecutor(var0, var0, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue());
}
public static ExecutorService newSingleThreadExecutor() {
return new Executors.FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue());
}
public static ScheduledExecutorService newScheduledThreadPool(int var0) {
return new ScheduledThreadPoolExecutor(var0);
}
(重点)
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {……}
二、ThreadPoolExecutor中重要的几个参数详解
- corePoolSize:核心线程数,也是线程池中常驻的线程数,线程池初始化时默认是没有线程的,当任务来临时才开始创建线程去执行任务
- maximumPoolSize:最大线程数,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
- keepAliveTime:非核心线程的空闲时间超过keepAliveTime就会被自动终止回收掉,注意当corePoolSize=maxPoolSize时,keepAliveTime参数也就不起作用了(因为不存在非核心线程);
- unit:keepAliveTime的时间单位
- workQueue:用于保存任务的队列,可以为无界、有界、同步移交三种队列类型之一,当池子里的工作线程数大于corePoolSize时,这时新进来的任务会被放到队列中
- threadFactory:创建线程的工厂类,默认使用Executors.defaultThreadFactory(),也可以使用guava库的ThreadFactoryBuilder来创建
- handler:线程池无法继续接收任务(队列已满且线程数达到maximunPoolSize)时的饱和策略,取值有AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy
线程池中的线程创建流程图:
(基于<Java并发编程的艺术>一书)
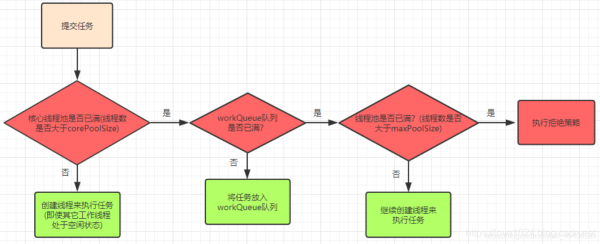
举个例子:
现有一个线程池,corePoolSize=10,maxPoolSize=20,队列长度为100,那么当任务过来会先创建10个核心线程数,接下来进来的任务会进入到队列中直到队列满了,会创建额外的线程来执行任务(最多20个线程),这个时候如果再来任务就会执行拒绝策略。
三、workQueue队列(阻塞队列)
SynchronousQueue(同步移交队列):队列不作为任务的缓冲方式,可以简单理解为队列长度为零LinkedBlockingQueue(无界队列):队列长度不受限制,当请求越来越多时(任务处理速度跟不上任务处理速度造成请求堆积)可能导致内存占用过多或OOMArrayBlockintQueue(有界队列):队列长度受限,当队列满了就需要创建多余的线程来执行任务
四、常见的几种自动创建线程池方式
自动创建线程池的几种方式都封装在Executors工具类中:
newFixedThreadPool:使用的构造方式为new ThreadPoolExecutor(var0, var0, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue()),设置了corePoolSize=maxPoolSize,keepAliveTime=0(此时该参数没作用),无界队列,任务可以无限放入,当请求过多时(任务处理速度跟不上任务提交速度造成请求堆积)可能导致占用过多内存或直接导致OOM异常
newSingleThreadExector:使用的构造方式为new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue(), var0),基本同newFixedThreadPool,但是将线程数设置为了1,单线程,弊端和newFixedThreadPool一致
newCachedThreadPool: 使用的构造方式为new ThreadPoolExecutor(0, 2147483647, 60L, TimeUnit.SECONDS, new SynchronousQueue()),corePoolSize=0,maxPoolSize为很大的数,同步移交队列,也就是说不维护常驻线程(核心线程),每次来请求直接创建新线程来处理任务,也不使用队列缓冲,会自动回收多余线程,由于将maxPoolSize设置成Integer.MAX_VALUE,当请求很多时就可能创建过多的线程,导致资源耗尽OOM
newScheduledThreadPool:使用的构造方式为new ThreadPoolExecutor(var1, 2147483647, 0L, TimeUnit.NANOSECONDS, new ScheduledThreadPoolExecutor.DelayedWorkQueue()),支持定时周期性执行,注意一下使用的是延迟队列,弊端同newCachedThreadPool一致
所以根据上面分析我们可以看到,FixedThreadPool和SigleThreadExecutor中之所以用LinkedBlockingQueue无界队列,是因为设置了corePoolSize=maxPoolSize,线程数无法动态扩展,于是就设置了无界阻塞队列来应对不可知的任务量;而CachedThreadPool则使用的是SynchronousQueue同步移交队列,为什么使用这个队列呢?
因为CachedThreadPool设置了corePoolSize=0,maxPoolSize=Integer.MAX_VALUE,来一个任务就创建一个线程来执行任务,用不到队列来存储任务;SchduledThreadPool用的是延迟队列DelayedWorkQueue。在实际项目开发中也是推荐使用手动创建线程池的方式,而不用默认方式。
关于这点在《阿里巴巴开发规范》中是这样描述的:
handler拒绝策略
- AbortPolicy:中断抛出异常
- DiscardPolicy:默默丢弃任务,不进行任何通知
- DiscardOldestPolicy:丢弃掉在队列中存在时间最久的任务
- CallerRunsPolicy:让提交任务的线程去执行任务(对比前三种比较友好一丢丢
关闭线程池
- shutdownNow():立即关闭线程池(暴力),正在执行中的及队列中的任务会被中断,同时该方法会返回被中断的队列中的任务列表
- shutdown():平滑关闭线程池,正在执行中的及队列中的任务能执行完成,后续进来的任务会被执行拒绝策略i
- sTerminated():当正在执行的任务及对列中的任务全部都执行(清空)完就会返回true。
五、线程池实现线程复用的原理
1.线程池里执行的是任务,核心逻辑在ThreadPoolExecutor类的execute方法中,同时ThreadPoolExecutor中维护了HashSet<Worker> workers;
2.addWorker()方法来创建线程执行任务,如果是核心线程的任务,会赋值给Worker的firstTask属性;
3.Worker实现了Runnable,本质上也是任务,核心在run()方法里;
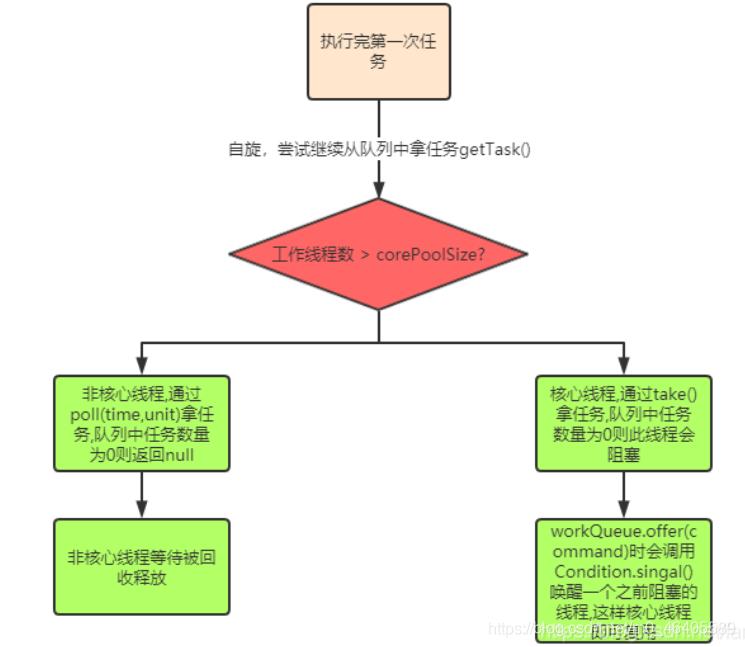
4.run()方法的执行核心runWorker(),自旋拿任务while (task != null || (task = getTask()) != null)),task是核心线程Worker的firstTask或者getTask();
5.getTask()的核心逻辑:
1.若当前工作线程数量大于核心线程数->说明此线程是非核心工作线程,通过poll()拿任务,未拿到任务即getTask()返回null,然后会在processWorkerExit(w, completedAbruptly)方法释放掉这个非核心工作线程的引用;
2.若当前工作线程数量小于核心线程数->说明此时线程是核心工作线程,通过take()拿任务
3.take()方式取任务,如果队列中没有任务了会调用await()阻塞当前线程,直到新任务到来,所以核心工作线程不会被回收; 当执行execute方法里的workQueue.offer(command)时会调用Condition.singal()方法唤醒一个之前阻塞的线程,这样核心线程即可复用
六、手动创建线程池(推荐)
那么上面说了使用Executors工具类创建的线程池有隐患,那如何使用才能避免这个隐患呢?对症下药,建立自己的线程工厂类,灵活设置关键参数:
//这里默认拒绝策略为AbortPolicy private static ExecutorService executor = new ThreadPoolExecutor(10,10,60L, TimeUnit.SECONDS,new ArrayBlockingQueue(10));
使用guava包中的ThreadFactoryBuilder工厂类来构造线程池:
private static ThreadFactory threadFactory = new ThreadFactoryBuilder().build(); private static ExecutorService executorService = new ThreadPoolExecutor(10, 10, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(10), threadFactory, new ThreadPoolExecutor.AbortPolicy());
通过guava的ThreadFactory工厂类还可以指定线程组名称,这对于后期定位错误时也是很有帮助的
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("thread-pool-d%").build();
七、Springboot中使用线程池
springboot可以说是非常流行了,下面说说如何在springboot中优雅的使用线程池
/**
* @ClassName ThreadPoolConfig
* @Description 配置类中构建线程池实例,方便调用
* @Author ww
* @Date 2021/5/11
* Version 1.0
*/
@Configuration
public class ThreadPoolConfig {
@Bean(value = "threadPoolInstance")
public ExecutorService createThreadPoolInstance() {
//通过guava类库的ThreadFactoryBuilder来实现线程工厂类并设置线程名称
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("thread-pool-%d").build();
ExecutorService threadPool = new ThreadPoolExecutor(10, 16, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(100), threadFactory, new ThreadPoolExecutor.AbortPolicy());
return threadPool;
}
}
/**
* @ClassName ThreadPoolConfig
* @Description 配置类中构建线程池实例,方便调用
* @Author ww
* @Date 2021/5/11
* Version 1.0
*/
@Configuration
public class ThreadPoolConfig {
@Bean(value = "threadPoolInstance")
public ExecutorService createThreadPoolInstance() {
//通过guava类库的ThreadFactoryBuilder来实现线程工厂类并设置线程名称
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("thread-pool-%d").build();
ExecutorService threadPool = new ThreadPoolExecutor(10, 16, 60L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(100), threadFactory, new ThreadPoolExecutor.AbortPolicy());
return threadPool;
}
}
其它相关
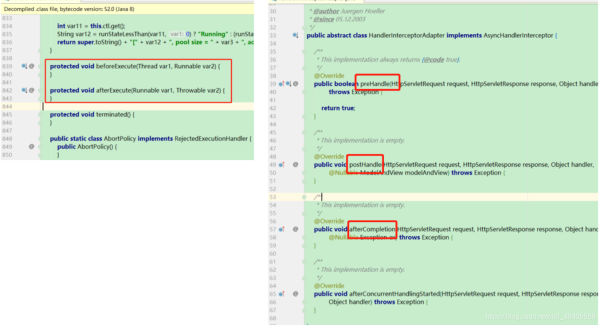
在ThreadPoolExecutor类中有两个比较重要的方法引起了我的注意:beforeExecute和afterExecute
protected void beforeExecute(Thread var1, Runnable var2) {
}
protected void afterExecute(Runnable var1, Throwable var2) {
}
这两个方法是protected修饰的,很显然是留给开发人员去重写方法体实现自己的业务逻辑,非常适合做钩子函数,在任务run方法的前后增加业务逻辑,比如添加日志、统计等。
这个和我们springmvc中拦截器的preHandle和afterCompletion方法很类似,都是对方法进行环绕,类似于spring的AOP。
到此这篇关于浅谈Java线程池的7大核心参数的文章就介绍到这了,更多相关Java线程池核心参数内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/212105/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)