
一、Tensorlow结构
import tensorflow as tf
import numpy as np
#创建数据
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1+0.3
#创建一个 tensorlow 结构
weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))#一维,范围[-1,1]
biases = tf.Variable(tf.zeros([1]))
y = weights*x_data + biases
loss = tf.reduce_mean(tf.square(y - y_data))#均方差函数
#建立优化器,减少误差,提高参数准确度,每次迭代都会优化
optimizer = tf.train.GradientDescentOptimizer(0.5)#学习率为0.5(<1)
train = optimizer.minimize(loss)#最小化损失函数
#初始化不变量
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#train
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(weights), sess.run(biases))
二、session的使用
import tensorflow as tf matrix1 = tf.constant([[3, 3]]) matrix2 = tf.constant([[2], [2]]) product = tf.matmul(matrix1, matrix2) #method1 sess = tf.Session() result2 = sess.run(product) print(result2) #method2 # with tf.Session() as sess: # result2 = sess.run(product) # print(result2)
三、Variable的使用
import tensorflow as tf
state = tf.Variable(0, name = 'counter')#变量初始化
# print(state.name)
one = tf.constant(1)
new_value = tf.add(state, one)
#将state用new_value代替
updata = tf.assign(state, new_value)
#变量激活
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(updata)
print(sess.run(state))
四、placeholder的使用
#给定type,tf大部分只能处理float32数据
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run(output, feed_dict={input1:[7.], input2:[2.]}))
五、激活函数 六、添加层
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))#正态分布
biases = tf.Variable(tf.zeros([1, out_size])+0.1) #1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases #Weights*x+b的初始化值,也是未激活的值
#激活
if activation_function is None:
#如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
#如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
七、创建一个神经网络
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))#正态分布
biases = tf.Variable(tf.zeros([1, out_size])+0.1) #1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases #Weights*x+b的初始化值,也是未激活的值
#激活
if activation_function is None:
#如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
#如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
#创建一列(相当于只有一个属性值),(-1,1)之间,有300个单位,后面是维度,x_data是有300行
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]#np.linspace在指定间隔内返回均匀间隔数字
#加入噪声,均值为0,方差为0.05,形状和x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
#定义y的函数为二次曲线函数,同时增加一些噪声数据
y_data = np.square(x_data) - 0.5 + noise
#定义输入值,输入结构的输入行数不固定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
"""建立网络"""
#定义隐藏层,输入为xs,输入size为1列,因为x_data只有一个属性值,输出size假定有10个神经元的隐藏层,激活函数relu
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
#定义输出层,输出为l1输入size为10列,也就是l1的列数,输出size为1,这里的输出类似y_data,因此为1列
prediction = add_layer(l1, 10, 1,activation_function=None)
"""预测"""
#定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
"""训练"""
#进行逐步优化的梯度下降优化器,学习率为0.1,以最小化损失函数进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#初始化模型所有参数
init = tf.global_variables_initializer()
#可视化
with tf.Session() as sess:
sess.run(init)
for i in range(1000):#学习1000次
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
if i%50==0:
print(sess.run(loss, feed_dict={xs:x_data, ys:y_data}))
八、可视化
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
def add_layer(inputs, in_size, out_size, activation_function = None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))#正态分布
biases = tf.Variable(tf.zeros([1, out_size])+0.1) #1行,out_size列,初始值不推荐为0,所以加上0.1
Wx_plus_b = tf.matmul(inputs, Weights) + biases #Weights*x+b的初始化值,也是未激活的值
#激活
if activation_function is None:
#如果没有设置激活函数,,则直接把当前信号原封不动的传递出去
outputs = Wx_plus_b
else:
#如果设置了激活函数,则由此激活函数对信号进行传递或抑制
outputs = activation_function(Wx_plus_b)
return outputs
"""定义数据形式"""
#创建一列(相当于只有一个属性值),(-1,1)之间,有300个单位,后面是维度,x_data是有300行
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]#np.linspace在指定间隔内返回均匀间隔数字
#加入噪声,均值为0,方差为0.05,形状和x_data一样
noise = np.random.normal(0, 0.05, x_data.shape)
#定义y的函数为二次曲线函数,同时增加一些噪声数据
y_data = np.square(x_data) - 0.5 + noise
#定义输入值,输入结构的输入行数不固定,但列就是1列的值
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
"""建立网络"""
#定义隐藏层,输入为xs,输入size为1列,因为x_data只有一个属性值,输出size假定有10个神经元的隐藏层,激活函数relu
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
#定义输出层,输出为l1输入size为10列,也就是l1的列数,输出size为1,这里的输出类似y_data,因此为1列
prediction = add_layer(l1, 10, 1,activation_function=None)
"""预测"""
#定义损失函数为差值平方和的平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),reduction_indices=[1]))
"""训练"""
#进行逐步优化的梯度下降优化器,学习率为0.1,以最小化损失函数进行优化
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#初始化模型所有参数
init = tf.global_variables_initializer()
#可视化
with tf.Session() as sess:
sess.run(init)
fig = plt.figure()#先生成一个图片框
#连续性画图
ax = fig.add_subplot(1, 1, 1)#编号为1,1,1
ax.scatter(x_data, y_data)#画散点图
#不暂停
plt.ion()#打开互交模式
# plt.show()
#plt.show绘制一次就暂停了
for i in range(1000):#学习1000次
sess.run(train_step, feed_dict={xs:x_data, ys:y_data})
if i%50==0:
try:
#画出一条后,抹除掉,去除第一个线段,但是只有一个相当于抹除当前线段
ax.lines.remove(lines[0])
except Exception:
pass
prediction_value = sess.run(prediction, feed_dict={xs:x_data})
lines = ax.plot(x_data,prediction_value,'r-',lw=5)#lw线宽
#暂停
plt.pause(0.5)
可视化结果:
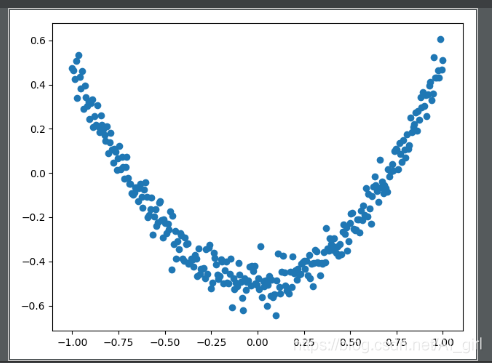
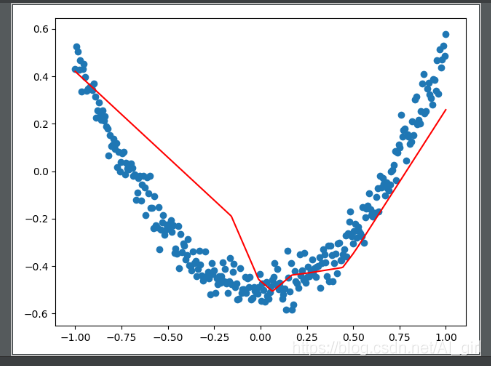
动图效果如下所示:

到此这篇关于基于Tensorflow搭建一个神经网络的实现的文章就介绍到这了,更多相关Tensorflow搭建神经网络内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/212354/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)