
引言
近年来,随着技术的发展,机器学习和深度学习在金融资产量化研究上的应用越来越广泛和深入。目前,大量数据科学家在Kaggle网站上发布了使用机器学习/深度学习模型对股票、期货、比特币等金融资产做预测和分析的文章。从金融投资的角度看,这些文章可能缺乏一定的理论基础支撑(或交易思维),大都是基于数据挖掘。但从量化的角度看,有很多值得我们学习参考的地方,尤其是Pyhton的深入应用、数据可视化和机器学习模型的评估与优化等。下面借鉴Kaggle上的一篇文章《Building an Asset Trading Strategy》,以上证指数为例,构建双均线交易策略,以交易信号为目标变量,以技术分析指标作为预测特征变量,使用多种机器学习模型进行对比评估和优化。文中的特征变量构建和提取,机器学习模型的对比评估和结果可视化都是很好的参考模板。
数据获取与指标构建
先引入需要用到的libraries,这是Python语言的突出特点之一。这些涉及到的包比较多,包括常用的numpy、pandas、matplotlib,技术分析talib,机器学习sklearn和数据包tushare等。
#先引入后面可能用到的libraries import numpy as np import pandas as pd import tushare as ts #技术指标 import talib as ta #机器学习模块 from sklearn.linear_model import LogisticRegression from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import GradientBoostingClassifier from xgboost import XGBClassifier,XGBRegressor from catboost import CatBoostClassifier,CatBoostRegressor from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor from sklearn.model_selection import train_test_split,KFold,cross_val_score from sklearn.metrics import accuracy_score import shap from sklearn.feature_selection import SelectKBest,f_regression from sklearn import preprocessing #画图 import seaborn as sns import matplotlib.pyplot as plt import plotly.graph_objects as go import plotly.express as px %matplotlib inline #正常显示画图时出现的中文和负号 from pylab import mpl mpl.rcParams['font.sans-serif']=['SimHei'] mpl.rcParams['axes.unicode_minus']=False
数据获取
用tushare获取上证行情数据作为分析样本。
#默认以上证指数交易数据为例
def get_data(code='sh',start='2000-01-01',end='2021-03-02'):
df=ts.get_k_data('sh',start='2005')
df.index=pd.to_datetime(df.date)
df=df[['open','high','low','close','volume']]
return df
df=get_data()
df_train,df_test=df.loc[:'2017'],df.loc['2018':]
构建目标变量(target variable)
以交易信号作为目标变量,使用价格信息和技术指标作为特征变量进行预测分析。以双均线交易策略为例,当短期均线向上突破长期均线时形成买入信号(设定为1),当短期均线向下跌破长期均线时发出卖出信号(设定为0),然后再使用机器学习模型进行预测和评估。这里将短期移动平均值(SMA1)和长期移动平均值(SMA2)的参数分别设置为10和60,二者的设定具有一定的任意性,参数的选择会影响后续结果,所以理想情况下需要进行参数优化来找到最优值。
def trade_signal(data,short=10,long=60,tr_id=False):
data['SMA1'] = data.close.rolling(short).mean()
data['SMA2'] = data.close.rolling(long).mean()
data['signal'] = np.where(data['SMA1'] >data['SMA2'], 1.0, 0.0)
if(tr_id is not True):
display(data['signal'].value_counts())
df_tr1 = df_train.copy(deep=True)
df_te1 = df_test.copy(deep=True)
trade_signal(df_tr1) #
trade_signal(df_te1,tr_id=True)
plt.figure(figsize=(14,12), dpi=80)
ax1 = plt.subplot(211)
plt.plot(df_tr1.close,color='b')
plt.title('上证指数走势',size=15)
plt.xlabel('')
ax2 = plt.subplot(212)
plt.plot(df_tr1.signal,color='r')
plt.title('交易信号',size=15)
plt.xlabel('')
plt.show()

df_tr1[['SMA1','SMA2','signal']].iloc[-250:].plot(figsize=(14,6),secondary_y=['signal']) plt.show()

#删除均线变量
df_tr1=df_tr1.drop(['SMA1','SMA2'], axis=1)
df_te1=df_te1.drop(['SMA1','SMA2'], axis=1)
#画目标变量与其他变量之间的相关系数图
cmap = sns.diverging_palette(220, 10, as_cmap=True)
def corrMat(df,target='demand',figsize=(9,0.5),ret_id=False):
corr_mat = df.corr().round(2);shape = corr_mat.shape[0]
corr_mat = corr_mat.transpose()
corr = corr_mat.loc[:, df.columns == target].transpose().copy()
if(ret_id is False):
f, ax = plt.subplots(figsize=figsize)
sns.heatmap(corr,vmin=-0.3,vmax=0.3,center=0,
cmap=cmap,square=False,lw=2,annot=True,cbar=False)
plt.title(f'Feature Correlation to {target}')
if(ret_id):
return corr
corrMat(df_tr1,'signal',figsize=(7,0.5))

当前的特征open、high、low、close、volumes与目标变量的线性相关值非常小,这可能意味着存在高非线性,相对平稳值的稳定振荡(圆形散射),或者也许它们不是理想的预测特征变量,所以下面需要进行特征构建和选取。
技术指标特征构建
为方便分析,下面以常见的几个技术指标作为特征引入特征矩阵,具体指标有:
移动平均线:移动平均线通过减少噪音来指示价格的运动趋势。
随机振荡器%K和%D:随机振荡器是一个动量指示器,比较特定的证券收盘价和一定时期内的价格范围。%K、%D分别为慢、快指标。
相对强弱指数(RSI):动量指标,衡量最近价格变化的幅度,以评估股票或其他资产的价格超买或超卖情况。
变化率(ROC):动量振荡器,测量当前价格和n期过去价格之间的百分比变化。ROC值越高越有可能超买,越低可能超卖。
动量(MOM):证券价格或成交量加速的速度;价格变化的速度。
#复制之前的数据 df_tr2=df_tr1.copy(deep=True) df_te2=df_te1.copy(deep=True)
计算技术指标
#使用talib模块直接计算相关技术指标 #下面参数的选取具有主观性 def indicators(data): data['MA13']=ta.MA(data.close,timeperiod=13) data['MA34']=ta.MA(data.close,timeperiod=34) data['MA89']=ta.MA(data.close,timeperiod=89) data['EMA10']=ta.EMA(data.close,timeperiod=10) data['EMA30']=ta.EMA(data.close,timeperiod=30) data['EMA200']=ta.EMA(data.close,timeperiod=200) data['MOM10']=ta.MOM(data.close,timeperiod=10) data['MOM30']=ta.MOM(data.close,timeperiod=30) data['RSI10']=ta.RSI(data.close,timeperiod=10) data['RSI30']=ta.RSI(data.close,timeperiod=30) data['RS200']=ta.RSI(data.close,timeperiod=200) data['K10'],data['D10']=ta.STOCH(data.high,data.low,data.close, fastk_period=10) data['K30'],data['D30']=ta.STOCH(data.high,data.low,data.close, fastk_period=30) data['K20'],data['D200']=ta.STOCH(data.high,data.low,data.close, fastk_period=200) indicators(df_tr2) indicators(df_te2) corrMat(df_tr2,'signal',figsize=(15,0.5))

上图可以看到明显线性相关的一组特征是作为特征工程的结果创建的。如果在特征矩阵中使用基本数据集特征,很可能对目标变量的变化影响很小或没有影响。另一方面,新创建的特征具有相当宽的相关值范围,这是相当重要的;与目标变量(交易信号)的相关性不算特别高。
#删除缺失值 df_tr2 = df_tr2.dropna() df_te2 = df_te2.dropna()
模型预测与评估
下面使用常用的机器学习算法分别对数据进行拟合和交叉验证评估
models.append(('RF', RandomForestClassifier(n_estimators=25)))
models = []
#轻量级模型
#线性监督模型
models.append(('LR', LogisticRegression(n_jobs=-1)))
models.append(('TREE', DecisionTreeClassifier()))
#非监督模型
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('NB', GaussianNB()))
#高级模型
models.append(('GBM', GradientBoostingClassifier(n_estimators=25)))
models.append(('XGB',XGBClassifier(n_estimators=25,use_label_encoder=False)))
models.append(('CAT',CatBoostClassifier(silent=True,n_estimators=25)))
构建模型评估函数
def modelEval(ldf,feature='signal',split_id=[None,None],eval_id=[True,True,True,True],
n_fold=5,scoring='accuracy',cv_yrange=None,hm_vvals=[0.5,1.0,0.75]):
''' Split Train/Evaluation <DataFrame> Set Split '''
# split_id : Train/Test split [%,timestamp], whichever is not None
# test_id : Evaluate trained model on test set only
if(split_id[0] is not None):
train_df,eval_df = train_test_split(ldf,test_size=split_id[0],shuffle=False)
elif(split_id[1] is not None):
train_df = df.loc[:split_id[1]]; eval_df = df.loc[split_id[1]:]
else:
print('Choose One Splitting Method Only')
''' Train/Test Feature Matrices + Target Variables Split'''
y_train = train_df[feature]
X_train = train_df.loc[:, train_df.columns != feature]
y_eval = eval_df[feature]
X_eval = eval_df.loc[:, eval_df.columns != feature]
X_one = pd.concat([X_train,X_eval],axis=0)
y_one = pd.concat([y_train,y_eval],axis=0)
''' Cross Validation, Training/Evaluation, one evaluation'''
lst_res = []; names = []; lst_train = []; lst_eval = []; lst_one = []; lst_res_mean = []
if(any(eval_id)):
for name, model in models:
names.append(name)
# Cross Validation Model on Training Se
if(eval_id[0]):
kfold = KFold(n_splits=n_fold, shuffle=True)
cv_res = cross_val_score(model,X_train,y_train, cv=kfold, scoring=scoring)
lst_res.append(cv_res)
# Evaluate Fit Model on Training Data
if(eval_id[1]):
res = model.fit(X_train,y_train)
train_res = accuracy_score(res.predict(X_train),y_train); lst_train.append(train_res)
if(eval_id[2]):
if(eval_id[1] is False): # If training hasn't been called yet
res = model.fit(X_train,y_train)
eval_res = accuracy_score(res.predict(X_eval),y_eval); lst_eval.append(eval_res)
# Evaluate model on entire dataset
if(eval_id[3]):
res = model.fit(X_one,y_one)
one_res = accuracy_score(res.predict(X_one),y_one); lst_one.append(one_res)
''' [out] Verbal Outputs '''
lst_res_mean.append(cv_res.mean())
fn1 = cv_res.mean()
fn2 = cv_res.std();
fn3 = train_res
fn4 = eval_res
fn5 = one_res
s0 = pd.Series(np.array(lst_res_mean),index=names)
s1 = pd.Series(np.array(lst_train),index=names)
s2 = pd.Series(np.array(lst_eval),index=names)
s3 = pd.Series(np.array(lst_one),index=names)
pdf = pd.concat([s0,s1,s2,s3],axis=1)
pdf.columns = ['cv_average','train','test','all']
''' Visual Ouputs '''
sns.set(style="whitegrid")
fig,ax = plt.subplots(1,2,figsize=(15,4))
ax[0].set_title(f'{n_fold} Cross Validation Results')
sns.boxplot(data=lst_res, ax=ax[0], orient="v",width=0.3)
ax[0].set_xticklabels(names)
sns.stripplot(data=lst_res,ax=ax[0], orient='v',color=".3",linewidth=1)
ax[0].set_xticklabels(names)
ax[0].xaxis.grid(True)
ax[0].set(xlabel="")
if(cv_yrange is not None):
ax[0].set_ylim(cv_yrange)
sns.despine(trim=True, left=True)
sns.heatmap(pdf,vmin=hm_vvals[0],vmax=hm_vvals[1],center=hm_vvals[2],
ax=ax[1],square=False,lw=2,annot=True,fmt='.3f',cmap='Blues')
ax[1].set_title('Accuracy Scores')
plt.show()
基准模型:使用原始行情数据作为特征
modelEval(df_tr1,split_id=[0.2,None])
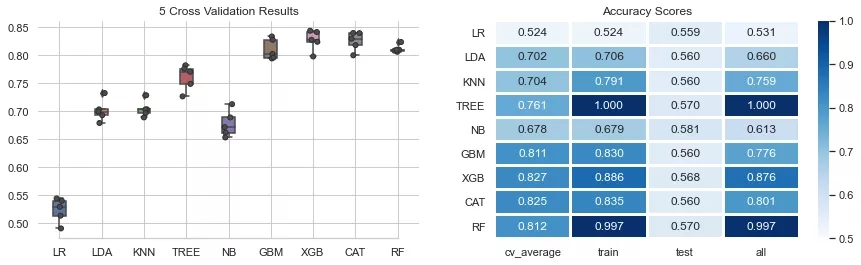
结果显示,cross_val_score徘徊在准确度= 0.5的区域,这表明仅使用指数/股票的价格数据(开盘、最高、最低、成交量、收盘)很难准确预测价格变动的方向性。大多数模型的训练得分往往高于交叉验证得分。有意思的是,DecisionTreeClassifier & RandomForest即使很少估计可以达到非常高的分数,但交叉验证的得分却很低,表明对训练数据可能存在过度拟合了。
加入技术指标特征
modelEval(df_tr2,split_id=[0.2,None],cv_yrange=(0.8,1.0),hm_vvals=[0.8,1.0,0.9])
结果表明,与基准模型相比,准确率得分有了非常显著的提高。线性判别分析(LDA)的表现非常出色,不仅在训练集上,而且在交叉验证中,得分显著提高。毫无疑问,更复杂的模型GBM,XGB,CAT,RF在全样本中评估得分较高。与有监督学习模型相比,kNN和GaussianNB的无监督模型表现较差。
特征的优化
def feature_importance(ldf,feature='signal',n_est=100):
# Input dataframe containing feature & target variable
X = ldf.copy()
y = ldf[feature].copy()
del X[feature]
# CORRELATION
imp = corrMat(ldf,feature,figsize=(15,0.5),ret_id=True)
del imp[feature]
s1 = imp.squeeze(axis=0);s1 = abs(s1)
s1.name = 'Correlation'
# SHAP
model = CatBoostRegressor(silent=True,n_estimators=n_est).fit(X,y)
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
shap_sum = np.abs(shap_values).mean(axis=0)
s2 = pd.Series(shap_sum,index=X.columns,name='Cat_SHAP').T
# RANDOMFOREST
model = RandomForestRegressor(n_est,random_state=0, n_jobs=-1)
fit = model.fit(X,y)
rf_fi = pd.DataFrame(model.feature_importances_,index=X.columns,
columns=['RandForest']).sort_values('RandForest',ascending=False)
s3 = rf_fi.T.squeeze(axis=0)
# XGB
model=XGBRegressor(n_estimators=n_est,learning_rate=0.5,verbosity = 0)
model.fit(X,y)
data = model.feature_importances_
s4 = pd.Series(data,index=X.columns,name='XGB').T
# KBEST
model = SelectKBest(k=5, score_func=f_regression)
fit = model.fit(X,y)
data = fit.scores_
s5 = pd.Series(data,index=X.columns,name='K_best')
# Combine Scores
df0 = pd.concat([s1,s2,s3,s4,s5],axis=1)
df0.rename(columns={'target':'lin corr'})
x = df0.values
min_max_scaler = preprocessing.MinMaxScaler()
x_scaled = min_max_scaler.fit_transform(x)
df = pd.DataFrame(x_scaled,index=df0.index,columns=df0.columns)
df = df.rename_axis('Feature Importance via', axis=1)
df = df.rename_axis('Feature', axis=0)
pd.options.plotting.backend = "plotly"
fig = df.plot(kind='bar',title='Scaled Feature Importance')
fig.show()
feature_importance(df_tr2)
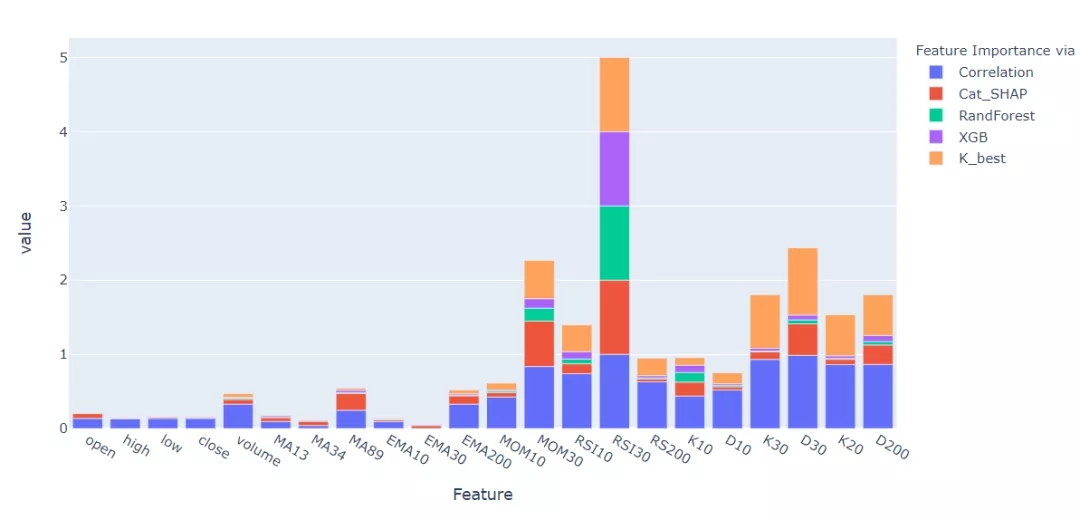
注意到,对于很多特征,相关性(Pearson's value)小的在其他方法中也会给出小的得分值。同样,高相关的特征在其他特征重要性方法中得分也很高。当谈到特征的重要性时,有一些特征显示出一些轻微的不一致,总的来说,大多数方法都可以观察到特征评分的相似性。在机器学习中,某些特征对于大多数方法来说都有一个非常低的相对分数值,因此可能没有什么影响,即使把它们删除,也不会降低模型的准确性。删除可能不受影响的特性将使整个方法更加有效,同时可以专注于更长和更深入的超参数网格搜索,可能得到比原来模型更准确的结果。
df_tr2_FI = df_tr2.drop(columns=['open','high','low','close','EMA10']) modelEval(df_tr2_FI,split_id=[0.2,None],cv_yrange=(0.8,1.0),hm_vvals=[0.8,1.0,0.9])
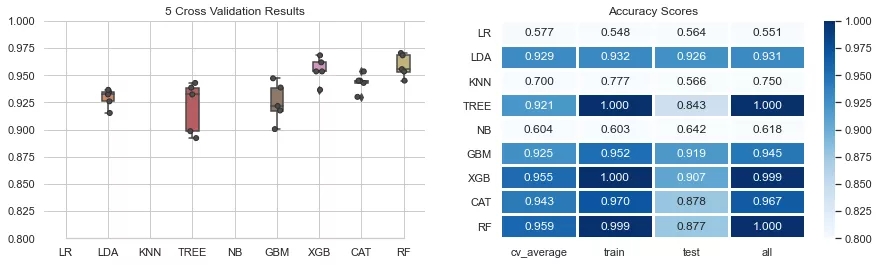
结语
本文只是以上证指数为例,以技术指标作为特征,使用机器学习算法对股票交易信号(注意这里不是股价或收益率)进行预测评估,目的在于向读者展示Python机器学习在金融量化研究上的应用。从金融维度来看,分析的深度较浅,实际上对股价预测有用的特征有很多,包括(1)外在因素, 如股票相关公司的竞争对手、客户、全球经济、地缘政治形势、财政和货币政策、资本获取等。因此,公司股价可能不仅与其他公司的股价相关,还与大宗商品、外汇、广义指数、甚至固定收益证券等其他资产相关;(2)股价市场因素,如很多投资者关注技术指标。(3)公司基本面因素,如公司的年度和季度报告可以用来提取或确定关键指标,如净资产收益率(ROE)和市盈率(price -to - earnings)。此外,新闻可以预示即将发生的事件,这些事件可能会推动股价向某个方向发展。当关注股票价格预测时,我们可以使用类似的方法来构建影响预测变量的因素,希望本文能起到抛砖引玉的作用。
以上就是python基于机器学习预测股票交易信号的详细内容,更多关于python 预测股票交易信号的资料请关注自学编程网其它相关文章!

- 本文固定链接: https://zxbcw.cn/post/213258/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)