
了解知道Dropout原理
如果要提高神经网络的表达或分类能力,最直接的方法就是采用更深的网络和更多的神经元,复杂的网络也意味着更加容易过拟合。
于是就有了Dropout,大部分实验表明其具有一定的防止过拟合的能力。
用代码实现Dropout




Dropout的numpy实现

PyTorch中实现dropout

import torch.nn.functional as F
import torch.nn.init as init
import torch
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
import math
%matplotlib inline
#%matplotlib inline 可以在Ipython编译器里直接使用
#功能是可以内嵌绘图,并且可以省略掉plt.show()这一步。
xy=np.loadtxt('./data/diabetes.csv.gz',delimiter=',',dtype=np.float32)
x_data=torch.from_numpy(xy[:,0:-1])#取除了最后一列的数据
y_data=torch.from_numpy(xy[:,[-1]])#取最后一列的数据,[-1]加中括号是为了keepdim
print(x_data.size(),y_data.size())
#print(x_data.shape,y_data.shape)
#建立网络模型
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.l1=torch.nn.Linear(8,60)
self.l2=torch.nn.Linear(60,4)
self.l3=torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
self.dropout=torch.nn.Dropout(p=0.5)
def forward(self,x):
out1=self.sigmoid(self.l1(x))
out2=self.dropout(out1)
out3=self.sigmoid(self.l2(out2))
out4=self.dropout(out3)
y_pred=self.sigmoid(self.l3(out4))
return y_pred
#our model
model=Model()
criterion=torch.nn.BCELoss(size_average=True)
#optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
optimizer=torch.optim.Adam(model.parameters(),lr=0.1,weight_decay=0.1)
#weight_decay是L2正则
#training loop
Loss=[]
for epoch in range(2000):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
if epoch%20 == 0:
print("epoch = ",epoch," loss = ",loss.data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
hour_var = Variable(torch.randn(1,8))
print("predict",model(hour_var).data[0]>0.5)
L2正则化
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,weight_decay=0.001)
补充:PyTorch1.0实现L1,L2正则化以及Dropout (附dropout原理的python实现以及改进)
看代码吧~
# 包 import torch import torch.nn as nn import torch.nn.functional as F # torchvision 包收录了若干重要的公开数据集、网络模型和计算机视觉中的常用图像变换 import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np %matplotlib inline
1. 什么是dropout(随机失活)?
1.1 一种Regularization的方法
与L1、L2正则化和最大范式约束等方法互为补充。在训练的时候,dropout的实现方法是让神经元以超参数 p 的概率被激活或者被设置为0。
1.2 在训练过程中
随机失活可以被认为是对完整的神经网络抽样出一些子集,每次基于输入数据只更新子网络的参数(然而,数量巨大的子网络们并不是相互独立的,因为它们都共享参数)。
1.3 在测试过程中不使用随机失活
所有的神经元都激活,**但是对于隐层的输出都要乘以 p **。可以理解为是对数量巨大的子网络们做了模型集成(model ensemble),以此来计算出一个平均的预测。详见:http://cs231n.github.io/neural-networks-2/
1.4 一般在全连接层把神经元置为0
在卷积层中可能把某个通道置为0!
2. 用代码实现regularization(L1、L2、Dropout)
注意:PyTorch中的regularization是在optimizer中实现的,所以无论怎么改变weight_decay的大小,loss会跟之前没有加正则项的大小差不多。这是因为loss_fun损失函数没有把权重W的损失加上!
2.1 L1 regularization
对于每个 ω 我们都向目标函数增加一个λ|ω| 。
L1正则化有一个有趣的性质,它会让权重向量在最优化的过程中变得稀疏(即非常接近0)。也就是说,使用L1正则化的神经元最后使用的是它们最重要的输入数据的稀疏子集,同时对于噪音输入则几乎是不变的了。
相较L1正则化,L2正则化中的权重向量大多是分散的小数字。在实践中,如果不是特别关注某些明确的特征选择,一般说来L2正则化都会比L1正则化效果好。
PyTorch里的optimizer只能实现L2正则化,L1正则化只能手动实现:
regularization_loss = 0
for param in model.parameters():
regularization_loss += torch.sum(abs(param))
calssify_loss = criterion(pred,target)
loss = classify_loss + lamda * regularization_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
2.2 L2 regularization
对于网络中的每个权重 ω ,向目标函数中增加一个 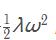 其中 λ 是正则化强度。这样该式子关于梯度就是 λω 了。
其中 λ 是正则化强度。这样该式子关于梯度就是 λω 了。
L2正则化可以直观理解为它对于大数值的权重向量进行严厉惩罚,倾向于更加分散的权重向量。
最后需要注意在梯度下降和参数更新的时候,使用L2正则化意味着所有的权重都以 w += -lambda * W向着0线性下降。
选择一个合适的权重衰减系数λ非常重要,这个需要根据具体的情况去尝试,初步尝试可以使用 1e-4 或者 1e-3
在PyTorch中某些optimizer优化器的参数weight_decay (float, optional)就是 L2 正则项,它的默认值为0。
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,weight_decay=0.001)
2.3 PyTorch1.0 实现 dropout
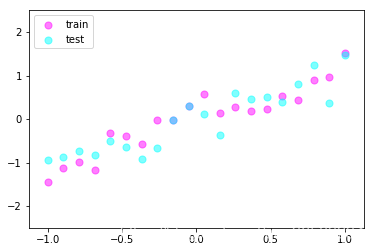
数据少, 才能凸显过拟合问题, 所以我们就做10个数据点.
torch.manual_seed(1) # Sets the seed for generating random numbers.reproducible
N_SAMPLES = 20
N_HIDDEN = 300
# training data
x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
print('x.size()',x.size())
# torch.normal(mean, std, out=None) → Tensor
y = x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# test data
test_x = torch.unsqueeze(torch.linspace(-1, 1, N_SAMPLES), 1)
test_y = test_x + 0.3*torch.normal(torch.zeros(N_SAMPLES, 1), torch.ones(N_SAMPLES, 1))
# show data
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.show()
x.size() torch.Size([20, 1])
我们现在搭建两个神经网络, 一个没有 dropout, 一个有 dropout. 没有 dropout 的容易出现 过拟合, 那我们就命名为 net_overfitting, 另一个就是 net_dropped.
net_overfitting = torch.nn.Sequential(
torch.nn.Linear(1,N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,N_HIDDEN),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,1),
)
net_dropped = torch.nn.Sequential(
torch.nn.Linear(1,N_HIDDEN),
torch.nn.Dropout(0.5), # 0.5的概率失活
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,N_HIDDEN),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch.nn.Linear(N_HIDDEN,1),
)
训练模型并测试2个模型的performance
optimizer_ofit = torch.optim.Adam(net_overfitting.parameters(),lr=0.001)
optimizer_drop = torch.optim.Adam(net_dropped.parameters(),lr=0.01)
loss = torch.nn.MSELoss()
for epoch in range(500):
pred_ofit= net_overfitting(x)
pred_drop= net_dropped(x)
loss_ofit = loss(pred_ofit,y)
loss_drop = loss(pred_drop,y)
optimizer_ofit.zero_grad()
optimizer_drop.zero_grad()
loss_ofit.backward()
loss_drop.backward()
optimizer_ofit.step()
optimizer_drop.step()
if epoch%50 ==0 :
net_overfitting.eval() # 将神经网络转换成测试形式,此时不会对神经网络dropout
net_dropped.eval() # 此时不会对神经网络dropout
test_pred_ofit = net_overfitting(test_x)
test_pred_drop = net_dropped(test_x)
# show data
plt.scatter(x.data.numpy(), y.data.numpy(), c='magenta', s=50, alpha=0.5, label='train')
plt.scatter(test_x.data.numpy(), test_y.data.numpy(), c='cyan', s=50, alpha=0.5, label='test')
plt.plot(test_x.data.numpy(), test_pred_ofit.data.numpy(), 'r-', lw=3, label='overfitting')
plt.plot(test_x.data.numpy(), test_pred_drop.data.numpy(), 'b--', lw=3, label='dropout(50%)')
plt.text(0, -1.2, 'overfitting loss=%.4f' % loss(test_pred_ofit, test_y).data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.text(0, -1.5, 'dropout loss=%.4f' % loss(test_pred_drop, test_y).data.numpy(), fontdict={'size': 20, 'color': 'blue'})
plt.legend(loc='upper left')
plt.ylim((-2.5, 2.5))
plt.pause(0.1)
net_overfitting.train()
net_dropped.train()
plt.ioff()
plt.show()
一共10张图片就不一一放上来了,取1,4,7,10张吧:
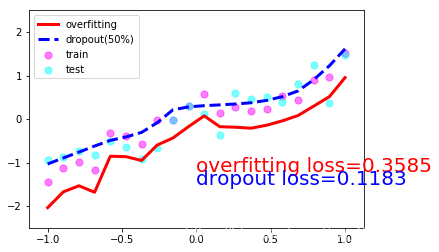
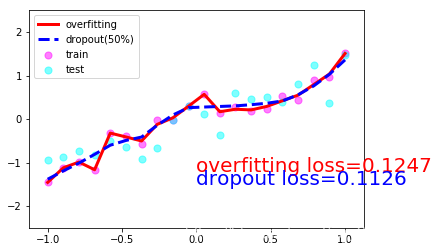
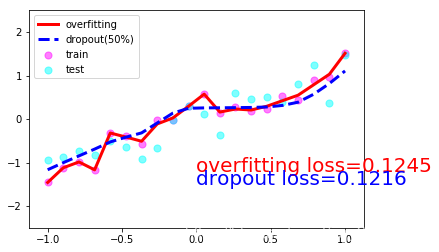
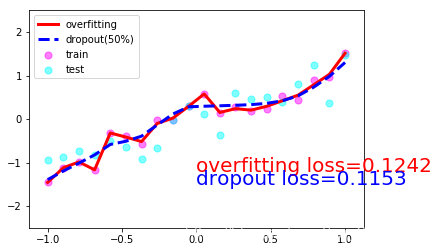
3. Dropout的numpy实现(参考斯坦福大学CS231n课程笔记)
网上对于为什么dropout后要进行rescale缩放的讨论很多,这里给出斯坦福cs231n课上的解释,个人觉得比较有道理,这里是对普通dropout的改进,使得无论是否使用随机失活,预测方法的代码可以保持不变。
一个3层神经网络的普通版dropout可以用下面代码实现:
""" 普通版随机失活: 不推荐实现 """
p = 0.5 # 激活神经元激活神经元激活神经元(重要的事情说三遍)的概率. p值更高 = 随机失活更弱
def train_step(X):
""" X中是输入数据 """
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # 第一个dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # 第二个dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # 注意:激活数据要乘以p
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # 注意:激活数据要乘以p
out = np.dot(W3, H2) + b3
上述操作不好的性质是必须在测试时对激活数据要按照 p 进行数值范围调整,我们可以使其在训练时就进行数值范围调整,从而让前向传播在测试时保持不变。
这样做还有一个好处,无论你决定是否使用随机失活,预测方法的代码可以保持不变。这就是反向随机失活(inverted dropout):
"""
inverted dropout(反向随机失活): 推荐实现方式.
在训练的时候drop和调整数值范围,测试时不用任何改变.
"""
p = 0.5 # 激活神经元的概率. p值更高 = 随机失活更弱
def train_step(X):
# 3层neural network的前向传播
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # 第一个dropout mask. 注意/p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # 第二个dropout mask. 注意/p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# 反向传播:计算梯度... (略)
# 进行参数更新... (略)
def predict(X):
# 前向传播时模型集成
H1 = np.maximum(0, np.dot(W1, X) + b1) # 不用数值范围调整了
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
以上为个人经验,希望能给大家一个参考,也希望大家多多支持自学编程网。

- 本文固定链接: https://zxbcw.cn/post/213410/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)