
一、什么是数据类型
其实可以明白数据类型指的就是变量值的不同类型,姓名可能是一种数据类型、年龄可能是一种数据类型、爱好可能又是另一种数据类型
二、字符串类型
字符串类型所表示的数据是常量,它是一种不可变数据类型
如何表示
str = 'zhangsan' str = "zhangsan" str = '''zhangsan''' # 可以实现换行 str = """zhangsan""" # 可以实现换行 str = r'zhangsan\n' # r可以取消转移字符的功能
相关方法

举例:
find('str') # 找不到为-1
index('str') # 找不到报错
isalnum('str') # 由字母或数字组成
isspace('str') # 由空格组成
split('str') # 分割之后是列表
rsplit('str',2) # 当分割次数有限制时与split有区别
partition('str') # 分割之后是三元组
capitalize() # 字符串首字母大写
title() # 每个单词首字母大写
ljust() # 左对齐加空格
取值与切片操作
str = '123456789‘ # 下标取值 str[0] # 1 str[-1] # 9 # 切片语法 m[start, end, step] str[1:3] # 23 str[3:1] # 空 str[0:] # 123456789 str[:3] # 123 str[::] # 123456789 str[::-1] # 987654321 str[0:4:1] # 1234 str[0:4:2] # 13 str[0:4:0] # 报错 str[0:4:-1] # 空 str[4:0:-1] # 5432 str[-3:-1] # 78 str[-1:-3] # 空 str[-3:-1:-1] # 空 str[-3:-1:1] # 78 str[-1:-3:-1] # 98 str[-1:-3:1] # 空
编码与解码操作
chr(65) # 编码转为字符
ord('我') # 字符转为编码
'str'.encode('utf-8') # 将字符串转编码
'str'.decode('utf-8') # 将字符串转解码
格式化输出操作
普通格式化
%s(字符串)、 %d(整形)、 %f(浮点型)、 %%(%)、 %x(十六进制)、 %X(十六进制)
name = 'zhangsan'
age = 18
print('姓名:', name, ',年龄:', age, sep='')
print('姓名:%s,年龄:%d' %(name,age))
————————————————
版权声明:本文为CSDN博主「ProChick」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_45747519/article/details/117379242
format格式化
# 默认
print('姓名{},年龄{}'.format('张三',18))
# 下标赋值
print('姓名{1},年龄{0}'.format(18,'张三'))
# 变量名赋值
print('姓名{name},年龄{age}'.format(name='zhangsan',age=18))
# 列表赋值
list = ['zhangsan',18]
print('姓名{},年龄{}'.format(*list))
# 字典赋值
dict = {"name":'zhangsan',"age":18}
print('姓名{name},年龄{age}'.format(**dict))
三、列表类型
列表类型所代表的数据元素有序且可以重复、可以修改
如何表示
mylist = ['张三',18]
mylist = list( ('zhangsan',18) ) # 将可迭代对象转化为列表
相关方法
添加元素
list = [1,2,3] # 追加 list.append(4) # [1,2,3,4] # 插入 list.insert(0,0) # [0,1,2,3,4]
修改元素
list = [1,2,3] # 修改指定位置元素 list[0] = 0 # [0,2,3] list[2] = 0 # [0,2,0]
删除元素
list = [1,2,3,4,5,6] # 删除最后一个 list.pop() # [1,2,3,4,5] # 删除指定位置 list.pop(0) # [2,3,4,5] # 删除指定元素 list.remove(2) # [3,4,5] # 清空 list.clear() # []
查询元素
list = [1, 2, 3, 2, 1] # 查找元素位置 list.index(1) # 0 # 查找元素个数 list.count(1) # 2
合并列表
list1 = [1,2,3] list2 = [4,5,6] # 合并 list1.extend(list2) # [1,2,3,4,5,6] print(list1+list2) # [1,2,3,4,5,6]
排序
list = [2, 3, 1]
# 正序
list.sort() # [1,2,3]
# 产生新对象并正序
new_list = sorted(list) # [1,2,3]
# 倒序
list.sort(reverse=True) # [3,2,1]
# 倒序
list.reverse() # [3,2,1]
# 自定义排序规则(一般用于字典类型的比较)
list = [
{'name':'zhangsan',age:18},
{'name':'lisi',age:20},
{'name':'wangwu',age:19}
]
list.sort(key = lambda item : item['age'])
拷贝
list = [1, 2, 3] # 是浅拷贝 new_list = list.copy() # [1, 2, 3]
嵌套
# 相当于二维数组 list = [[1,2],[3,4],[5,6]]
推导式
list = [i for i in range(1,3)] # [1,2] list = [(i,j) for i in range(1,3) for j in range(1)] # [(1,0),(2,0)]
四、元组类型
元组类型所表示的数据元素有序且可以重复,但不可以修改
如何表示
# 表示多个元素 tuple = (1,2,'3') # 表示1个元素 tuple = (True,)
相关方法
查询元素
tuple = (1,True,'3',True) tuple.index(0) # 1 tuple.count(True) # 2
合并
tuple1 = (1,2) tuple2 = (True,False) print(tuple1+tuple2) # (1,2,True,False)
五、字典类型
字典类型所表示的数据元素无序,Key不可以重复(只能是不可变数据类型),Value可以修改(可以为任意数据类型)
如何表示
student = {"name":'zhangsan',"age":20}
相关方法
查询元素
student = {"name":'zhangsan',"age":20}
print(student["age"]) # 20
print(student["birth"]) # 报错
print(student.get("age")) # 20
print(student.get("birth")) # None
print(student.get("birth",'2000-10-10')) # 2000-10-10d
# 获取所有Key
print(student.keys()) # ['name','age']
# 获取所有Value
print(student.values()) # ['zhangsan',20]
# 获取所有Key-Value
print(student.items()) # [('name':'zhangsan'),('age':20)]
添加、修改元素
student = {"name":'zhangsan',"age":20}
student["name"] = 'lisi'
print(student) # student = {"name":'lisi',"age":20}
student["sex"] = '男'
print(student) # student = {"name":'lisi',"age":20,"sex":'男'}
删除元素
student = {"name":'zhangsan',"age":20}
# 删除Key-Value,返回Value
result = student.pop("name")
print(student) # student = {"age":20}
print(result) # zhangsan
# 删除Key-Value,返回Key-Value
result = student.popitem("name")
print(student) # student = {"age":20}
print(result) # ('name','zhangsan')
# 清空
student.clear()
print(result) # {}
合并
student = {"name":'zhangsan',"age":20}
student_add = {"sex":'男'}
student.update(student_add)
print(student) # {"name":'zhangsan',"age":20,"sex":'男'}
推导式
student = {"name":'zhangsan',"age":20}
student_reverse = {v:k for k,v in student.items()}
print(student_reverse) # {"zhangsan":'name',"20":age}
六、集合类型
集合类型所表示的数据元素无序且不可以重复,不可以修改
如何表示
# 有元素的集合
set = {1,'我',True}
# 空集合
set()
相关方法
添加元素
set = {1,'我',True}
set.add('zhangsan')
print(set) # {1,'我',True,'zhangsan'}
删除元素
set = {1,'我',True}
# 随机删除一个元素
set.pop()
print(set) # {'我',True}
# 删除指定元素
set.remove('True')
print(set) # {1,'我'}
# 清空
set.clear()
print(set) # set()
合并
set = {1,'我',True}
# 两个集合合并后产生新的集合
new_set = set.union( {True,False} )
print(new_set) # {1,'我',True,False}
# 将一个可迭代对象合并到原有集合中
set.update(['False'])
print(set) # {1,'我',True,'False'}
运算
set1 = {1,2,3}
set2 = {3,4,5}
# 差集
print(set1 - ste2) # {1,2}
print(set2 - ste1) # {4,5}
# 交集
print(set1 & ste2) # {3}
# 并集
print(set1 | ste2) # {1,2,3,4,5}
# 差并集
print(set1 ^ ste2) # {1,2,4,5}
七、五种数据类型所支持的运算符比较
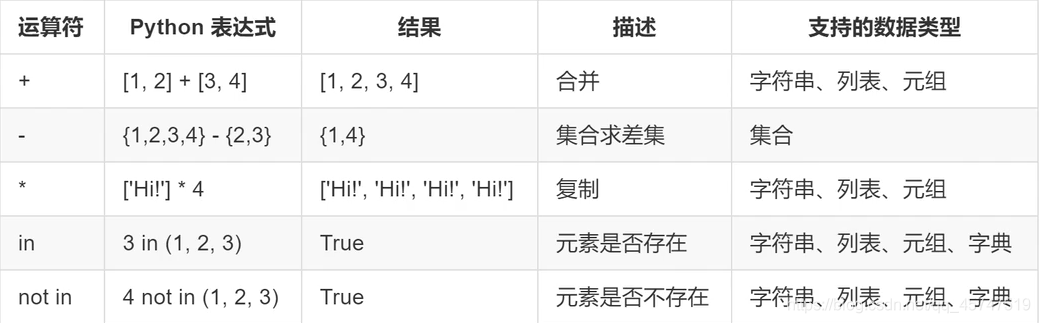
八、数据的序列化和反序列化
序列化操作
将数据从内存持久化保存到硬盘的过程
----(将数据转化为字符串)----
import json
list = ['name','age','city']
file = open('test.txt','w',encoding='utf8')
file.write(repr(list)) # 第一种方式
file.write(str(list)) # 第二种方式
file.write(json.dumps(list)) # 第三种方式
json.dump(list,file) # 第四种方式
file.close()
----(将数据转化为二进制)----
import pickle
list = ['name','age','city']
file = open('test.txt','wb',encoding='utf8')
file.write(pickle.dumps(list)) # 第一种方式
pickle.dump(list,file) # 第二种方式
file.close()
反序列化操作
将数据从硬盘加载到内存的过程
# test.txt ["name","age","city"]
----(将字符串转化为数据)----
import json
file = open('test.txt','r',encoding='utf8')
list1 = json.load(file) # 第一种方式
print(list1) # ['name','age','city']
list2 = json.loads(file.read()) # 第二种方式
print(list2) # ['name','age','city']
file.close()
----(将二进制转化为数据)----
import pickle
file = open('test.txt','rb',encoding='utf8')
list1 = pickle.loads(file.read()) # 第一种方式
print(list1) # ['name','age','city']
list2 = pickle.load(file) # 第二种方式
print(list2) # ['name','age','city']
file.close()
到此这篇关于Python数据类型最全知识总结的文章就介绍到这了,更多相关Python数据类型内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/213773/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)