
一、前言
ByteBuf是Netty当中的最重要的工具类,它与JDK的ByteBuffer原理基本上相同,也分为堆内与堆外俩种类型,但是ByteBuf做了极大的优化,具有更简单的API,更多的工具方法和优秀的内存池设计。
二、API
Netty 的数据处理 API 通过两个组件暴露——抽象类ByteBuf 和 接口 ByteBufHolder。
ByteBuf API 的优点:
- 它可以被用户自定义的缓冲区类型扩展
- 通过内置的复合缓冲区类型实现了透明的零拷贝;
- 容量可以按需增长(类似于 JDK 的 StringBuilder)
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法
- 读和写使用了不同的索引
- 支持方法的链式调用
- 支持引用
- 计数支持池化
其他类可用于管理 ByteBuf 实例的分配,以及执行各种针对于数据容器本身和它所持有的数据的操作。
三、Netty 的数据容器
所有网络通信最终都是基于底层的字节流传输,因此高效、方便、易用的数据接口是迷人的,而 Netty 的 ByteBuf 生而为满足这些需求。
3.1 工作原理
ByteBuf 维护俩不同索引:一个用于读取,一个用于写入:
- 从 ByteBuf 读取时,其 readerIndex 将会被递增已经被读取的字节数
- 当写入 ByteBuf 时,writerIndex 也会被递增
- 一个读索引和写索引都设置为 0 的 16 字节 ByteBuf

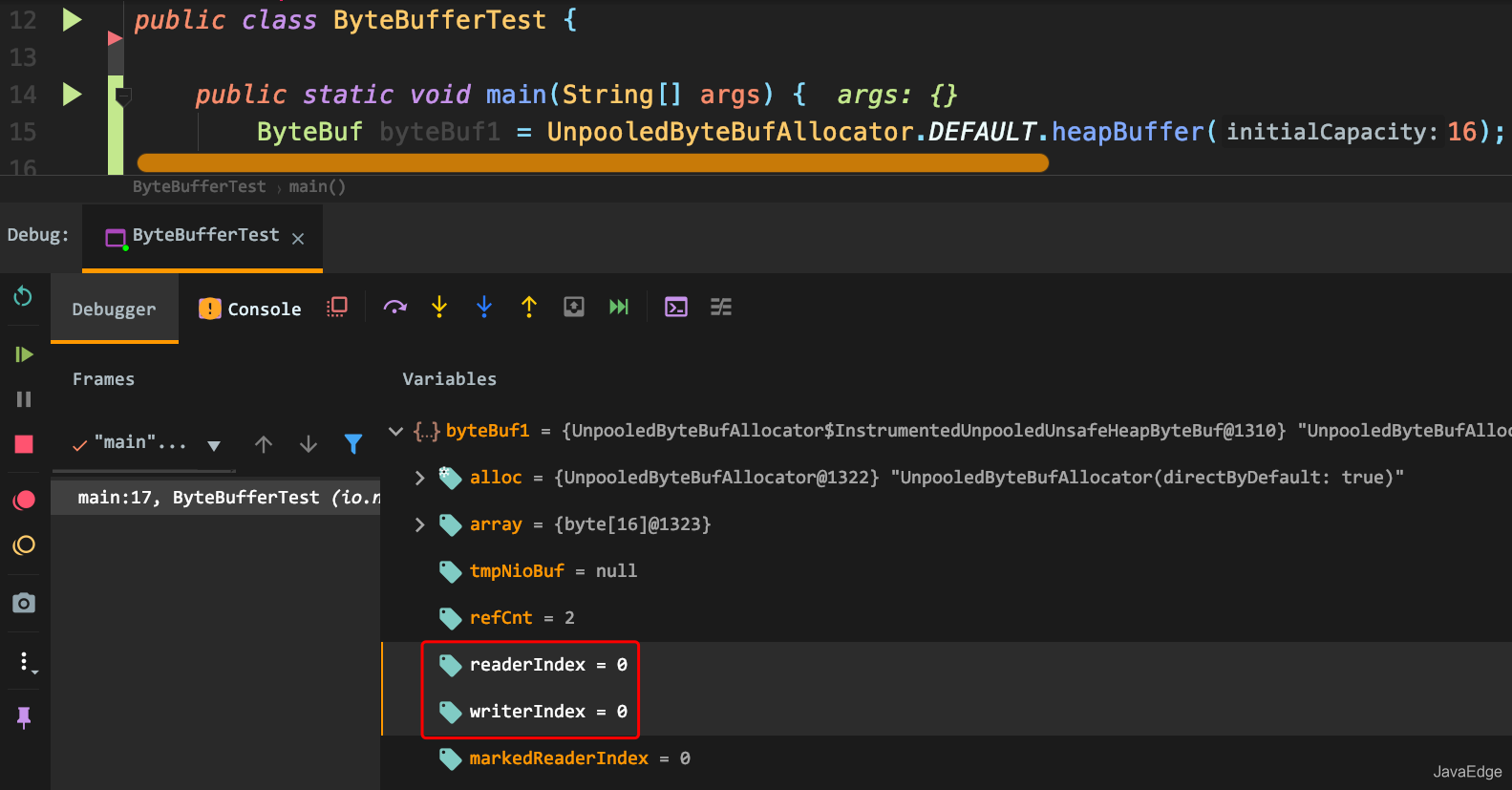
这些索引两两之间有什么关系呢?
若打算读取字节直到 readerIndex == writerIndex,会发生啥?此时,将会到达“可读取的”数据的末尾。类似试图读取超出数组末尾的数据一样,试图读取超出该点的数据也会抛 IndexOutOfBoundsException。
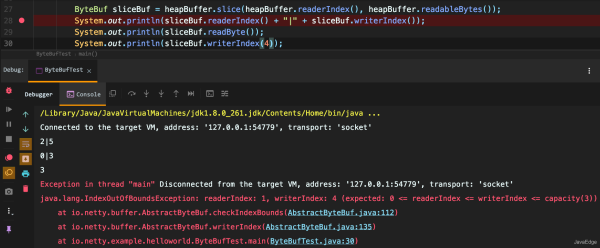
- read、write 开头的 ByteBuf 方法,会推进对应索引
- set、get 开头的操作则不会。后面的这些方法将在作为一个参数传入的一个相对索引上执行操作
可指定 ByteBuf 的最大容量。试图移动写索引(即 writerIndex)超过这个值将会触
发一个异常。(默认限制 Integer.MAX_VALUE。)
四、内存池化
非池化的堆内与堆外的 ByteBuf 示意图
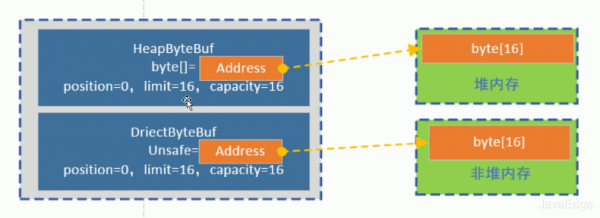
ByteBuf heapBuffer = UnpooledByteBufAllocator.DEFAULT.heapBuffer(10); ByteBuf directBuffer = UnpooledByteBufAllocator.DEFAULT.directBuffer(10);
注意要手动将GC 无法控制的非堆内存的空间释放:
池化的堆内与堆外的 ByteBuf 示意图


五、字节级操作
派生缓冲区
派生缓冲区为 ByteBuf 提供了以专门的方式来呈现其内容的视图。这类视图通过以下方法创建:
- Unpooled.unmodifiableBuffer(…)
- order(ByteOrder)
- readSlice(int)
这些方法都将返回一个新的 ByteBuf 实例,但都具有自己独立的读、写和标记索引。
其内部存储和 JDK 的 ByteBuffer 一样,都是共享的。所以派生缓冲区的创建成本很低,但同时也表明若你修改了它的内容,也会同时修改对应源实例!
slice、slice(int, int)、retainedSlice、retainedSlice(int, int)
返回此缓冲区的可读字节的一部分。
此方法与buf.slice(buf.readerIndex(), buf.readableBytes())相同。
该方法不会调用retain(),引用计数不会增加。
retainedSlice系列方法调用类似slice().retain(),但此方法可能返回产生较少垃圾的缓冲区实现。

duplicate、retainedDuplicate

返回一个共享该缓冲区整个区域的缓冲区。
此方法不会修改此缓冲区的readerIndex或writerIndex
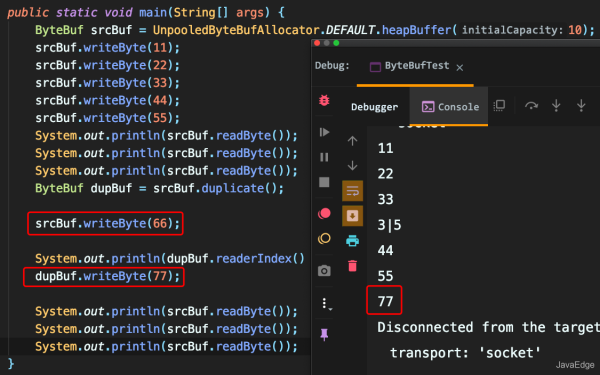
读取器和写入器标记将不会重复。
duplicate不会调用retain(),不会增加引用计数,而retainedDuplicate会。
readSlice、readRetainedSlice
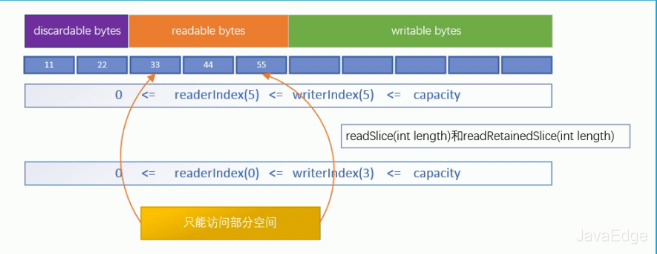
返回部分空间,彼此共享底层缓冲区,会增加原缓冲区的readerIndex。
如果需要一个现有缓冲区的真实副本,请使用 copy()或者 copy(int, int),因为这个调用所返回的 ByteBuf 拥有独立的数据副本。
六、引用与释放
ByteBuf 在使用完毕后一定要记得释放,否则会造成内存泄露。
引用计数
通过在某个对象所持有的资源不再被其他对象引用时释放该对象所持有的资源来优化内存使用和性能的技术。
Netty 在4.x为 ByteBuf 和 ByteBufHolder 带来了引用计数技术,都实现了:
ReferenceCounted接口
需要显式释放的引用计数对象。
当一个新的ReferenceCounted被实例化时,以1 作为初始值。
retain()
增加引用计数,将引用计数加1。只要引用计数>0,就能保证对象不会被释放。
release()
减少引用计数,将引用计数减1。若引用计数减少到0 ,对象将被显式释放,并且访问释放的对象通常会导致访问冲突。
若实现ReferenceCounted的对象是其他实现ReferenceCounted的对象的容器,则当容器的引用计数变为 0 时,所包含的对象也将通过release()被释放。
引用计数对于池化实现(如 PooledByteBufAllocator)很重要,它降低了内存分配的开销。
Channel channel = ...; // 从 Channel 获取 ByteBufAllocator ByteBufAllocator allocator = channel.alloc(); ... // 从 ByteBufAllocator 分配一个 ByteBuf ByteBuf buffer = allocator.directBuffer(); // 检查引用计数是否为预期的 1 assert buffer.refCnt() == 1; ByteBuf buffer = ...; // 减少该对象的活动引用。当减少到 0 时,该对象被释放,该方法返回 true boolean released = buffer.release();
试图访问一个已经被释放的引用计数的对象,将会抛IllegalReferenceCountException


一个特定的(ReferenceCounted 的实现)类,可以用它自己的独特方式来定义它的引用计数规则。例如可以设想一个类,其 release()方法的实现总是将引用计数设为
零,而不用关心它的当前值,从而一次性使所有的活动引用都失效。
谁负责释放
一般由最后访问(引用计数)对象的那一方来负责将它释放。
到此这篇关于又又???UG啦!理智分析Java NIO的ByteBuffer到底有多难用的文章就介绍到这了,更多相关Java NIO的ByteBuffer内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/214122/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)