
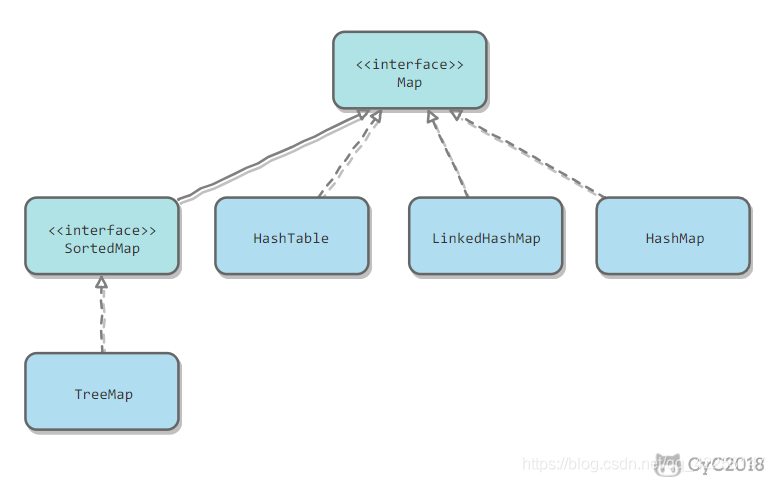
Map集合
Map集合存储的是键值对
Map集合的实现类:
HashTable、LinkedHashMap、HashMap、TreeMap
HashMap
基础了解:
1、键不可以重复,值可以重复;
2、底层使用哈希表实现;
3、线程不安全;
4、允许key为null,但只允许有一条记录为null,value也可以为null,允许多条记录为null;
源码分析
(一)以JDK1.7为例
1、存储结构
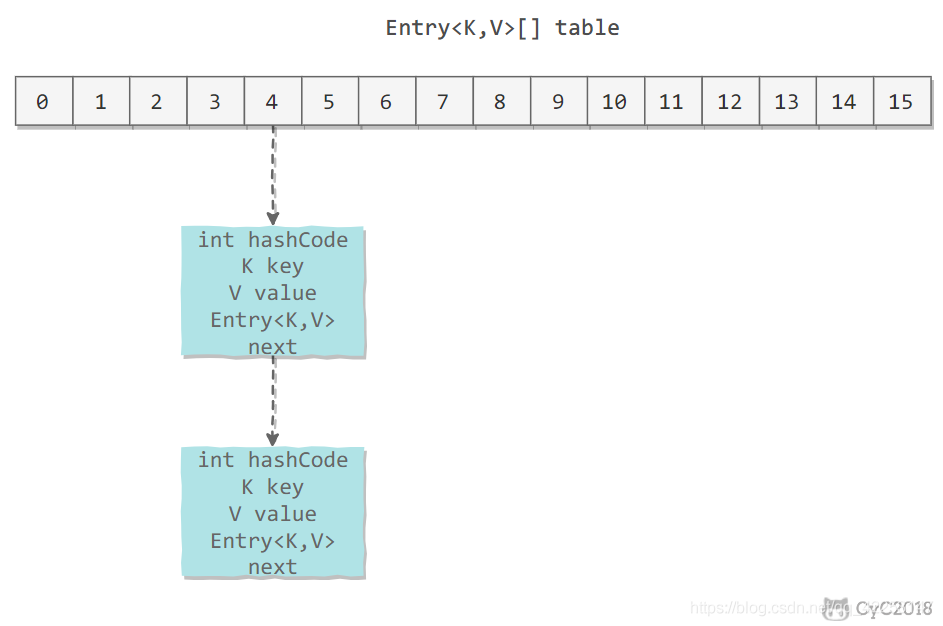
数据结构:数组+链表
首先hashmap内部有一个Entry类型的数组table;
通过Entry<K,V> 知道table数组每一个节点,存储的元素是键值对;
再通过字段next知道,每一个节点当出现哈希冲突的时候,会通过链表的形式将哈希值相同的节点放在同一个桶内;
四个字段:K,V,next,hash;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
}
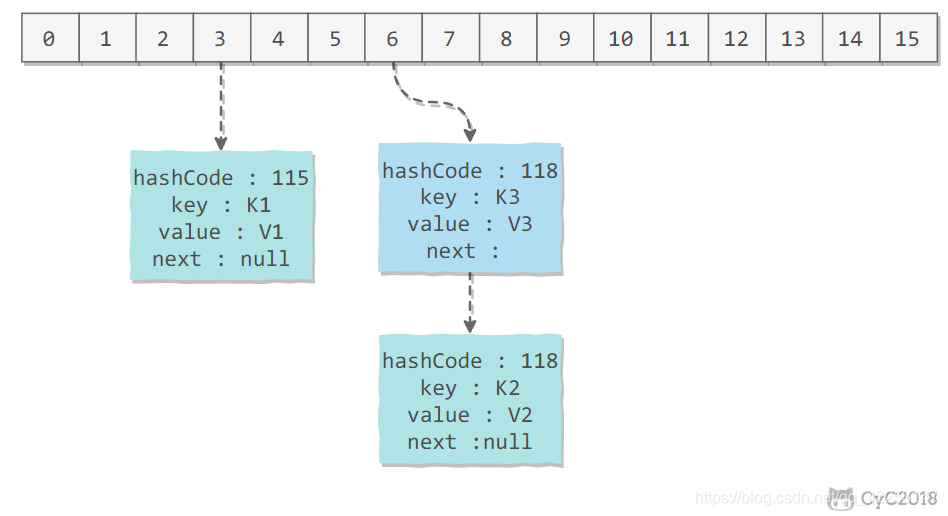
2、拉链法的工作原理
HashMap<String, String> map = new HashMap<>();
map.put("K1", "V1");
map.put("K2", "V2");
map.put("K3", "V3");
新建一个 HashMap,默认大小为 16;
插入 <K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
插入 <K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
插入 <K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2> 前面。
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3> 不是插在 <K2,V2> 后面,而是插入在链表头部。
查找需要分成两步进行:
计算键值对所在的桶;
在链表上顺序查找,时间复杂度显然和链表的长度成正比
3、put()方法
put方法调用
1.调用hash函数得到key的HashCode值
2.通过HashCode值与数组长度-1逻辑与运算得到一个index值
3.遍历索引位置对应的链表,如果Entry对象的hash值与hash函数得到的hash值相等,并且该Entry对象的key值与put方法传过来的key值相等则,将该Entry对象的value值赋给一个变量,将该Entry对象的value值重新设置为put方法传过来的value值。将旧的value返回。
4.添加Entry对象到相应的索引位置
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 键为 null 单独处理
if (key == null)
return putForNullKey(value);
int hash = hash(key);
// 确定桶下标
int i = indexFor(hash, table.length);
// 先找出是否已经存在键为 key 的键值对,如果存在的话就更新这个键值对的值为 value
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 插入新键值对
addEntry(hash, key, value, i);
return null;
}
HashMap 允许插入键为 null 的键值对。但是因为无法调用 null 的 hashCode() 方法,也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
使用链表的头插法,也就是新的键值对插在链表的头部,而不是链表的尾部。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 头插法,链表头部指向新的键值对
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
4、确定桶下标
很多操作都需要先确定一个键值对所在的桶下标。如上所示代码
int hash = hash(key); int i = indexFor(hash, table.length);
4.1、确定hash值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
4.2、取模确定桶下标
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
x : 00010000 x-1 : 00001111
令一个数 y 与 x-1 做与运算,可以去除 y 位级表示的第 4 位以上数:
y : 10110010 x-1 : 00001111 y&(x-1) : 00000010
这个性质和 y 对 x 取模效果是一样的:
y : 10110010 x : 00010000 y%x : 00000010
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的 n 次方,那么就可以将这个操作转换为位运算。
static int indexFor(int h, int length) {
return h & (length-1);
}
面试题目:hashmap的初始容量值为什么设置为16?
原因1、根据确定桶下标的原理, h & (length-1),长度length为2的整数次幂可以保证散列的均匀,提升效率;
原因2、因为length为偶数,length-1必为奇数,所以h值的奇偶数决定了散列表数组落入奇数或者偶数数组内;这样保证了散列的均匀性。而如果length为奇数,那么length-1位偶数,最后一位为0,根据 逻辑 & 的原则码,最后一位肯定都是偶数0,而不可能出现奇数1,所以散列表只能使用一半的数组,造成很大的浪费;
5、扩容原理
HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成链表的结构,使得查询效率降低!

static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f; transient Entry[] table; transient int size; int threshold; final float loadFactor; transient int modCount;
从下面的添加元素代码中可以看出,当需要扩容时,令 capacity 为原来的两倍
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
扩容使用 resize() 实现,需要注意的是,扩容操作同样需要把 oldTable 的所有键值对重新插入 newTable 中,因此这一步是很费时的。
多线程下扩容会出现HashMap的循环链表情况
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
6、扩容-重新计算桶下标
在进行扩容时,需要把键值对重新放到对应的桶上。HashMap 使用了一个特殊的机制,可以降低重新计算桶下标的操作。
假设原数组长度 capacity 为 16,扩容之后 new capacity 为 32:
capacity : 00010000 new capacity : 00100000 对于一个 Key,
它的哈希值如果在第 5 位上为 0,那么取模得到的结果和之前一样;如果为 1,那么得到的结果为原来的结果 +16。
7、计算数组容量
HashMap 构造函数允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
mask |= mask >> 1 11011000 mask |= mask >> 2 11111110 mask |= mask >> 4 11111111
mask+1 是大于原始数字的最小的 2 的 n 次方。
num 10010000 mask+1 100000000
以下是 HashMap 中计算数组容量的代码:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
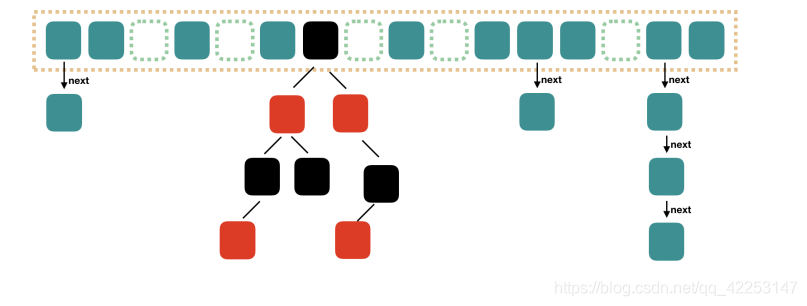
8、JDK1.8开始,链表转换为红黑树
从 JDK 1.8 开始,一个桶存储的链表长度大于 8 时会将链表转换为红黑树。
数据结构:数组+链表+红黑树
get()
get方法调用
1.当调用get方法时会调用hash函数,这个hash函数会将key的hashCode值返回,返回的hashCode与Entry数组长度-1进行逻辑与运算得到一个index值,用这个index值来确定数据存储在Entry数组当中的位置
2.通过循环来遍历索引位置对应的链表,初始值为数据存储在Entry数组当中的位置,循环条件为Entry对象不为null,改变循环条件为Entry对象的下一个节点
3.如果hash函数得到的hash值与Entry对象当中key的hash值相等,并且Entry对象当中的key值与get方法传进来的key值equals相同则返回该Entry对象的value值,否则返回null

我们能否让HashMap同步?
在多线程条件下,容易导致死循环,具体表现为CPU使用率100%。因此多线程环境下保证 HashMap 的线程安全性,主要有如下几种方法:
1、使用 java.util.Hashtable 类,此类是线程安全的。
2、使用 java.util.concurrent.ConcurrentHashMap,此类是线程安全的。
3、使用 java.util.Collections.synchronizedMap() 方法包装 HashMap object,得到线程安全的Map,并在此Map上进行操作。
通过Collections.synchronizedMap()来封装所有不安全的HashMap的方法,就连toString, hashCode都进行了封装. 封装的关键点有2处
(1)使用了经典的synchronized来进行互斥,
(2)使用了代理模式new了一个新的类,这个类同样实现了Map接口
到此这篇关于HashMap集合类的写法的文章就介绍到这了,更多相关Java遍历HashMap内容请搜索自学编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持自学编程网!

- 本文固定链接: https://zxbcw.cn/post/214456/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)