
1、简介
ConcurrentHashMap是HashMap的线程安全版本,内部也是使用(数组 + 链表 + 红黑树)的结构来存储元素。相比于同样线程安全的HashTable来说,效率等各方面都有极大地提高。
在学习ConcurrentHashMap源码之前,这里默认大家已经读过HashMap源码,了解LongAdder原子类、红黑树。先简单介绍下
ConcurrentHashMap的整体流程:
整体流程跟HashMap比较类似,大致是以下几步:
(1)如果桶数组未初始化,则初始化;
(2)如果待插入的元素所在的桶为空,则尝试把此元素直接插入到桶的第一个位置;
(3)如果正在扩容,则当前线程一起加入到扩容的过程中;
(4)如果待插入的元素所在的桶不为空且不在迁移元素,则锁住这个桶(分段锁);
(5)如果当前桶中元素以链表方式存储,则在链表中寻找该元素或者插入元素;
(6)如果当前桶中元素以红黑树方式存储,则在红黑树中寻找该元素或者插入元素;
(7)如果元素存在,则返回旧值;
(8)如果元素不存在,整个Map的元素个数加1,并检查是否需要扩容;
添加元素操作中使用的锁主要有(自旋锁 + CAS + synchronized + 分段锁)。
为什么使用synchronized而不是ReentrantLock?
因为synchronized已经得到了极大地优化,在特定情况下并不比ReentrantLock差。
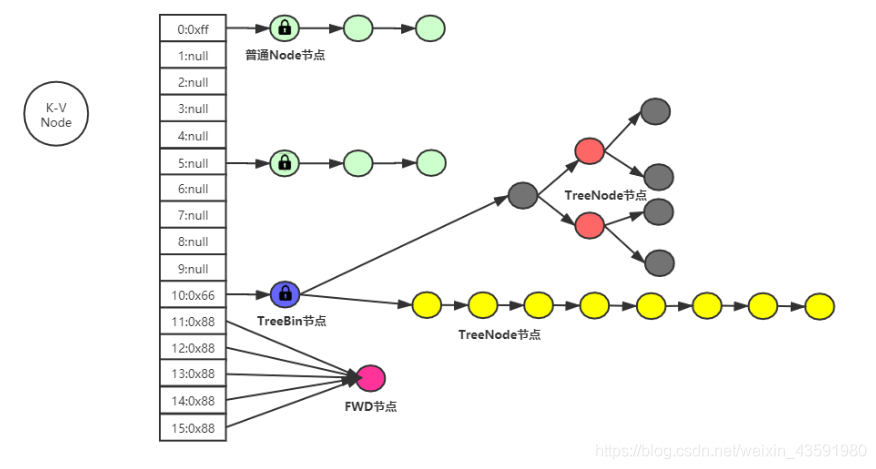
2、JDK1.8 ConcurrentHashMap结构图
3、成员属性
// 散列表数组最大容量值
private static final int MAXIMUM_CAPACITY = 1 << 30;
// 散列表默认容量值16
private static final int DEFAULT_CAPACITY = 16;
// 最大的数组大小(非2的幂) toArray和相关方法需要(并不是核心属性)
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// jdk1.7遗留下来的,用来表示并发级别的属性
// jdk1.8只有在初始化的时候用到,不再表示并发级别了~ 1.8以后并发级别由散列表长度决定
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
// 负载因子:表示散列表的填满程度~ 在ConcurrentHashMap中,该属性是固定值0.75,不可修改~
private static final float LOAD_FACTOR = 0.75f;
// 树化阈值:散列表的一个桶中链表长度达到8时候,可能发生链表树化
static final int TREEIFY_THRESHOLD = 8;
// 反树化阈值:散列表的一个桶中的红黑树元素个数小于6时候,将红黑树转换回链表结构
static final int UNTREEIFY_THRESHOLD = 6;
// 散列表长度达到64,且某个桶位中的链表长度达到8,才会发生树化
static final int MIN_TREEIFY_CAPACITY = 64;
// 控制线程迁移数据的最小步长(桶位的跨度~)
private static final int MIN_TRANSFER_STRIDE = 16;
// 固定值16,与扩容相关,计算扩容时会根据该属性值生成一个扩容标识戳
private static int RESIZE_STAMP_BITS = 16;
// (1 << (32 - RESIZE_STAMP_BITS)) - 1 = 65535:1 << 16 -1
// 表示并发扩容最多容纳的线程数
private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1;
// 也是扩容相关属性,在扩容分析的时候会用到~
private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS;
// 当node节点的hash值为-1:表示当前节点是FWD(forwarding)节点(已经被迁移的节点)
static final int MOVED = -1;
// 当node节点的hash值为-2:表示当前节点已经树化,且当前节点为TreeBin对象~,TreeBin对象代理操作红黑树
static final int TREEBIN = -2;
// 当node节点的hash值为-3:
static final int RESERVED = -3;
// 0x7fffffff 十六进制转二进制值为:1111111111111111111111111111111(31个1)
// 作用是将一个二进制负数与1111111111111111111111111111111 进行按位与(&)运算时,会得到一个正数,但不是取绝对值
static final int HASH_BITS = 0x7fffffff;
// 当前系统的CPU数量
static final int NCPU = Runtime.getRuntime().availableProcessors();
// JDK1.8 序列化为了兼容 JDK1.7的ConcurrentHashMap用到的属性 (非核心属性)
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
// 散列表table
transient volatile Node<K,V>[] table;
// 新表的引用:扩容过程中,会将扩容中的新table赋值给nextTable,(保持引用),扩容结束之后,这里就会被设置为NULL
private transient volatile Node<K,V>[] nextTable;
// 与LongAdder中的baseCount作用相同: 当未发生线程竞争或当前LongAdder处于加锁状态时,增量会被累加到baseCount
private transient volatile long baseCount;
// 表示散列表table的状态:
// sizeCtl<0时:
// 情况一、sizeCtl=-1: 表示当前table正在进行初始化(即,有线程在创建table数组),当前线程需要自旋等待...
// 情况二、表示当前table散列表正在进行扩容,高16位表示扩容的标识戳,低16位表示扩容线程数:(1 + nThread) 即,当前参与并发扩容的线程数量。
// sizeCtl=0时:表示创建table散列表时,使用默认初始容量DEFAULT_CAPACITY=16
// sizeCtl>0时:
// 情况一、如果table未初始化,表示初始化大小
// 情况二、如果table已经初始化,表示下次扩容时,触发条件(阈值)
private transient volatile int sizeCtl;
// 扩容过程中,记录当前进度。所有的线程都需要从transferIndex中分配区间任务,并去执行自己的任务
private transient volatile int transferIndex;
// LongAdder中,cellsBusy表示对象的加锁状态:
// 0: 表示当前LongAdder对象处于无锁状态
// 1: 表示当前LongAdder对象处于加锁状态
private transient volatile int cellsBusy;
// LongAdder中的cells数组,当baseCount发生线程竞争后,会创建cells数组,
// 线程会通过计算hash值,去取到自己的cell,将增量累加到指定的cell中
// 总数 = sum(cells) + baseCount
private transient volatile CounterCell[] counterCells;
4、静态属性
// Unsafe 类 private static final sun.misc.Unsafe U; // 表示sizeCtl属性在ConcurrentHashMap中内存的偏移地址 private static final long SIZECTL; // 表示transferIndex属性在ConcurrentHashMap中内存的偏移地址 private static final long TRANSFERINDEX; // 表示baseCount属性在ConcurrentHashMap中内存的偏移地址 private static final long BASECOUNT; // 表示cellsBusy属性在ConcurrentHashMap中内存的偏移地址 private static final long CELLSBUSY; // 表示cellsValue属性在ConcurrentHashMap中内存的偏移地址 private static final long CELLVALUE; // 表示数组第一个元素的偏移地址 private static final long ABASE; // 该属性用于数组寻址,请继续往下阅读 private static final int ASHIFT;
5、静态代码块
static {
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentHashMap.class;
SIZECTL = U.objectFieldOffset
(k.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset
(k.getDeclaredField("transferIndex"));
BASECOUNT = U.objectFieldOffset
(k.getDeclaredField("baseCount"));
CELLSBUSY = U.objectFieldOffset
(k.getDeclaredField("cellsBusy"));
Class<?> ck = CounterCell.class;
CELLVALUE = U.objectFieldOffset
(ck.getDeclaredField("value"));
Class<?> ak = Node[].class;
// 拿到数组第一个元素的偏移地址
ABASE = U.arrayBaseOffset(ak);
// 表示数组中每一个单元所占用的空间大小,即scale表示Node[]数组中每一个单元所占用的空间
int scale = U.arrayIndexScale(ak);
// (scale & (scale - 1)) != 0:判断scale的数值是否是2的次幂数
// java语言规范中,要求数组中计算出的scale必须为2的次幂数
// 1 0000 % 0 1111 = 0
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
// numberOfLeadingZeros(scale) 根据scale,返回当前数值转换为二进制后,从高位到地位开始统计,统计有多少个0连续在一块:eg, 8转换二进制=>1000 则 numberOfLeadingZeros(8)的结果就是28,为什么呢?因为Integer是32位,1000占4位,那么前面就有32-4个0,即连续最长的0的个数为28个
// 4转换二进制=>100 则 numberOfLeadingZeros(8)的结果就是29
// ASHIFT = 31 - Integer.numberOfLeadingZeros(4) = 2 那么ASHIFT的作用是什么呢?其实它有数组寻址的一个作用:
// 拿到下标为5的Node[]数组元素的偏移地址(存储地址):假设此时 根据scale计算得到的ASHIFT = 2
// ABASE + (5 << ASHIFT) == ABASE + (5 << 2) == ABASE + 5 * scale,就得到了下标为5的数组元素的偏移地址
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
} catch (Exception e) {
throw new Error(e);
}
}
6、内部类
6.1 Node节点
static class Node<K,V> implements Map.Entry<K,V> {
// hash值
final int hash;
// key
final K key;
// value
volatile V val;
// 后驱节点
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode();
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry<?,?> e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry<?,?>)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
}
6.2 ForwardingNode节点
这个内部类在之后分析扩容的文章中会再仔细去探究,这里先熟悉一下~
// 如果是一个写的线程(eg:并发扩容线程),则需要为创建新表贡献一份力
// 如果是一个读的线程,则调用该内部类的find(int h, Object k)方法
static final class ForwardingNode<K,V> extends Node<K,V> {
// nextTable表示新散列表的引用
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
// 到新表上去读数据
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;;) {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
6.3 TreeNode节点
TreeBin中需要用到该节点,之后会细说~
static final class TreeNode<K,V> extends Node<K,V> {
// 父节点
TreeNode<K,V> parent; // red-black tree links
// 左子节点
TreeNode<K,V> left;
// 右节点
TreeNode<K,V> right;
// 前驱节点
TreeNode<K,V> prev; // needed to unlink next upon deletion
// 节点有红、黑两种颜色~
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
*/
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
}
7、构造方法
public ConcurrentHashMap() {
}
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
构造方法与HashMap对比可以发现,没有了HashMap中的threshold和loadFactor,而是改用了sizeCtl来控制,而且只存储了容量在里面,那么它是怎么用的呢?官方给出的解释如下:
(1)-1,表示有线程正在进行初始化操作。
(2)-(1 + nThreads),表示有n个线程正在一起扩容。
(3)0,默认值,后续在真正初始化的时候使用默认容量。
(4)> 0,初始化或扩容完成后下一次的扩容门槛 。
8、总结
下一章:预热(内部一些小方法分析)
文章会不定时更新,有时候一天多更新几篇,如果帮助您复习巩固了知识点,后续会亿点点的更新!希望大家多多关注自学编程网的其他内容!

- 本文固定链接: https://zxbcw.cn/post/214611/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)