
一、页的概览
我们往 MySQL 插入的数据最终都是存在页中的。在 InnoDB 中的设计中,页与页之间是通过一个双向链表连接起来。
而存储在页中的一行一行的数据则是通过单链表连接起来的。
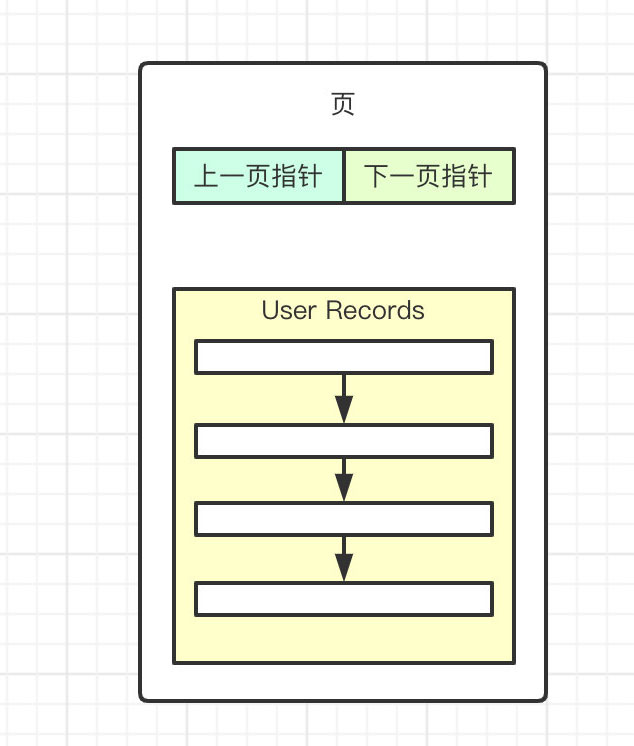
上图中的 User Records 的区域就是用来存储行数据的。那 InnoDB 为什么要这么设计?假设我们没有页这个概念,那么当我们查询时,成千上万的数据要如何做到快速的查询出结果?众所周知,MySQL 的性能是不错的,而如果没有页,我们剩下的只能是逐条逐条的遍历数据了。
那页是如何做到快速查询的呢?在当前页中,可以通过 User Records 中的连接每条记录的单链表来进行遍历,如果在当前页中没有找到,则可以通过下一页指针快速的跳到下一页进行查询。
二、Infimum 和 Supremum
有人可能会说了,你在 User Records 中还不是通过遍历来解决的,你就是简单的把数据分了个组而已。如果我的数据根本不在当前这个页中,那我难道还是得把之前的页中的每一条数据全部遍历完?这效率也太低了
当然,MySQL 也考虑到了这个问题,所以实际上在页中还存在一块区域叫做 The Infimum and Supremum Records ,代表了当前页中最大和最小的记录。
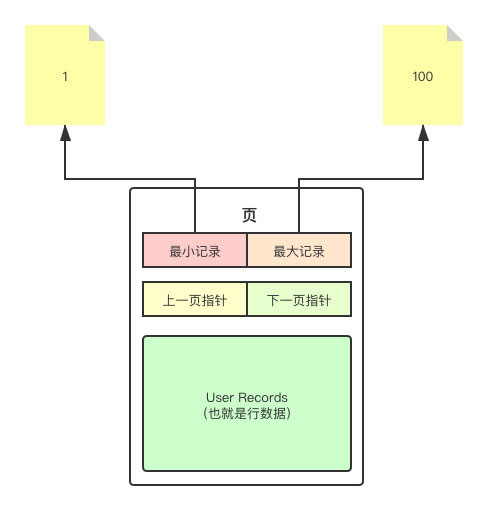
有了 Infimum Record 和 Supremum Record ,现在查询不需要将某一页的 User Records 全部遍历完,只需要将这两个记录和待查询的目标记录进行比较。比如我要查询的数据 id = 101 ,那很明显不在当前页。接下来就可以通过下一页指针跳到下页进行检索。
三、使用Page Directory
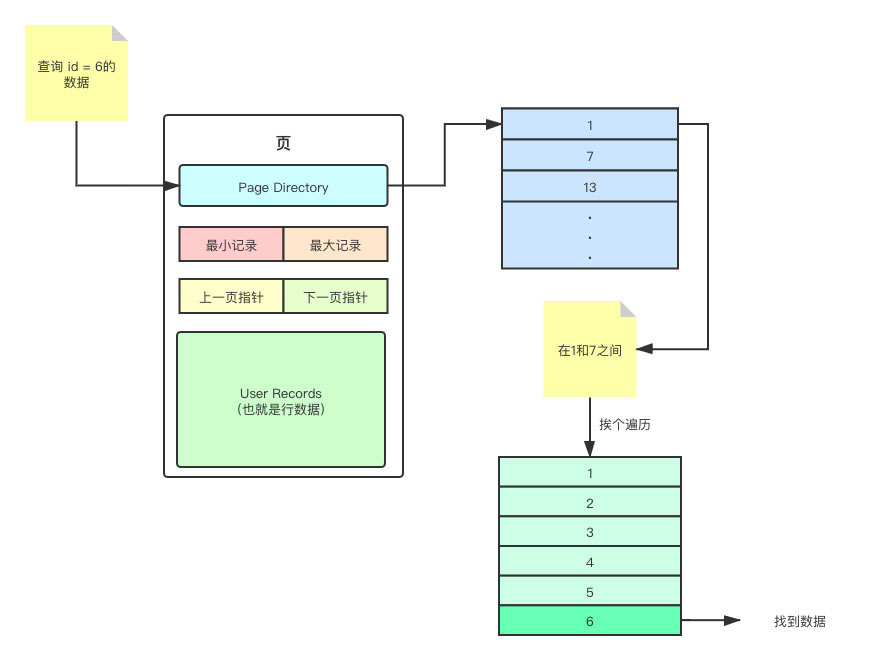
可能有人又会说了,你这 User Records 里不也全是单链表吗?即使我知道我要找的数据在当前页,那最坏的情况下,不还是得挨个挨个的遍历100次才能找到我要找的数据?你管这也叫效率高?
不得不说,这的确是个问题,不过是一个 MySQL 已经考虑到的问题。不错,挨个遍历确实效率很低。为了解决这个问题,MySQL 又在页中加入了另一个区域 Page Directory 。
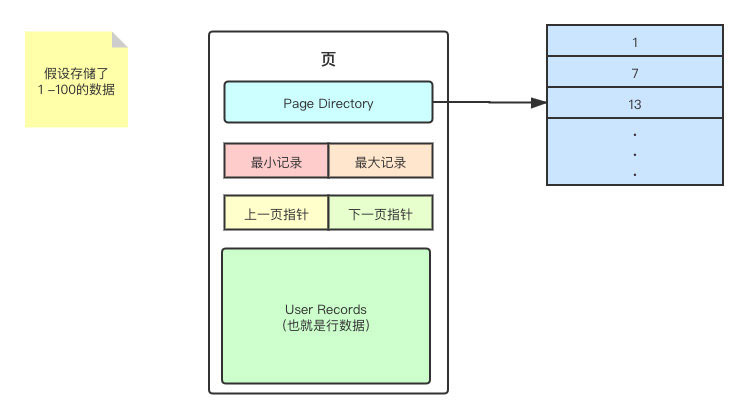
顾名思义,Page Directory 是个目录,里面有很多个槽位(Slots),每一个槽位都指向了一条 User Records 中的记录。大家可以看到,每隔几条数据,就会创建一个槽位。其实我图中给出的数据是非常严格按照其设定来的,在一个完整的页中,每隔6条数据就会有一个 Slot。
Page Directory 的设计不知道有没有让你想起另一个数据结构——跳表,只不过这里只抽象了一层索引
MySQL 会在新增数据的时候就将对应的 Slot 创建好,有了 Page Directory ,就可以对一张页的数据进行粗略的二分查找。至于为什么是粗略,毕竟 Page Directory 中不是完整的数据,二分查找出来的结果只能是个大概的位置,找到了这个大概的位置之后,还需要回到 User Records 中继续的进行挨个遍历匹配。
不过这样的效率已经比我们刚开始聊的原始版本高了很多了。
四、页的真实面貌
如果我开篇就把页的各种组成部分,各种概念直接抛出来,首先我自己接受不了,这样显得很僵硬。其次,对页不熟悉的人应该是不太能理解页为什么要这么设计的。所以我按照查询一条数据的一套思路,把页的大致的面貌呈现给了大家。
实际上,页上还存储了很多其他的字段,也还有其他的区域,但是这些都不会影响到我们对页的理解。所以,在对页有了一个较为清晰的认知之后,我们就可以来看看真实的页到底长啥样了。

上图就是页的实际全部组成,除了我们之前提到过的,还多了一些之前没有聊过的,例如 File Header、Page Header、Free Space、File Tailer 。我们一个一个来看。
4.1、File Header
其实File Header 在上文已经聊过了,只是不叫这个名字。上面提到的上一页指针和下一页指针其实就是属于File Header的,除此之外还有很多其他的数据。
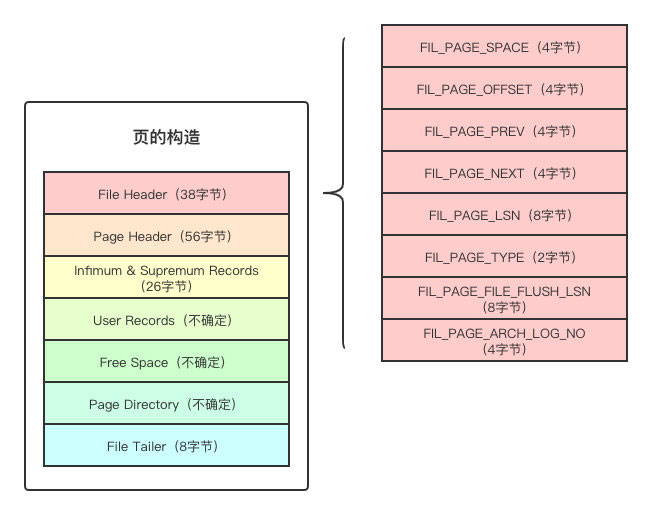
其实我比较抗拒把一堆参数列出来,告诉你这个大小多少,那个用来干嘛。对于我们需要详细了解页来说,其实暂时只需要知道两个就足够了,分别是:
- FIL_PAGE_PREV
- FIL_PAGE_NEXT
这两个变量就是上文提到过的上一页指针和下一页指针,说是指针,是为了方便大家理解,实际上是页在磁盘上的偏移量。
4.2、Page Header
比起 File Header ,Page Header 中的数据对我们来说就显得更加熟悉了,我这里画了一张图,把里面的内容详细的列了出来。
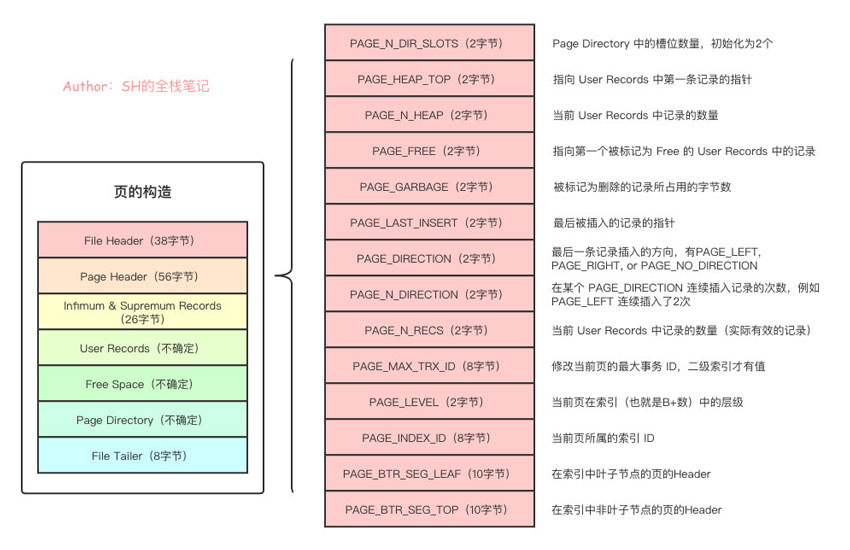
这里全列出来是因为了解这些参数的含义和为什么要设置参数,能够更好的帮助我们了解页的原理和构造,具体的看图说话就行。
这里也很想吐槽,太多博客都写的太僵硬,比如参数 PAGE_HEAP_TOP ,这里的 HEAP 很多博客都直接叫堆。这就跟你给Init写注释叫初始化一样,还不如不写。实际上你去研究一下就会知道,这里的堆实际上就是指User Records。
里面有个两个参数可能会有点混淆,分别是PAGE_N_HEAP和PAGE_N_RECS ,都是当前 User Records 中记录的数量,唯一的不同在于,PAGE_N_HEAP 中是包含了被标记为删除的记录的, 而 PAGE_N_RECS 中就是实际上我们能够查询到的所有数据。
4.3、Infimum & Supremum Records
上文中提到,Infimum & Supremum Records会记录当前页最大最小记录。实际上不准确,更准确的描述是最小记录和最大纪录的开区间。因为实际上 Infimum Records 会比当前页中的最小值还要小,而 Supremum Records 会比当前页中的最大值要大。
4.4、User Records
User Records 可以说是我们平时接触的最多的部分了,毕竟我们的数据最终都在这。页被初始化之后,User Records 中是没有数据的,随着系统运行,数据产生,User Records 中的数据会不断的膨胀,相应的 Free Space 空间会慢慢的变小。
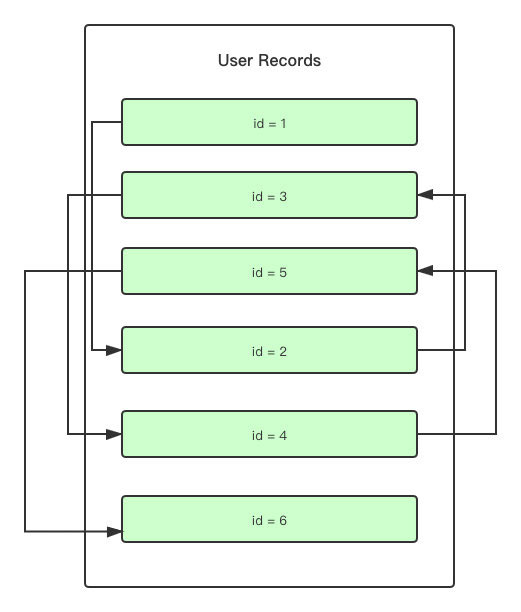
关于 User Records 中的概念,之前已经聊过了。这里只聊我认为很关键的一点,那就是顺序。
我们知道,在聚簇索引中,Key 实际上会按照 Primary Key 的顺序来进行排列。那在 User Records 中也会这样吗?我们插入一条新的数据到 User Records 中时,是否也会按照 Primary Key 的顺序来对已有的数据重排序?
答案是不会,因为这样会拉低 MySQL 处理的效率。
User Records 中的数据是由单链表指针的指向来保证的,也就是说,行数据实际在磁盘上的表现,是按照插入顺序来排队的,先到的数据在前面,后来的数据在后面。只不过通过 User Records 中的行数据之间的单链表形成了一个按照 Primary Key排列的顺序。
用图来表示,大概如下:
4.5、Free Space
这块其实变相的在其他的模块中讨论了,最初 User Records 是完全空的,当有新数据进来时,会来 Free Space 中申请空间,当 Free Space 没空间了,则说明需要申请新的页了,其他没什么特别之处。
4.6、Page Directory
这跟上文讨论的没什么出入,就直接跳过了。
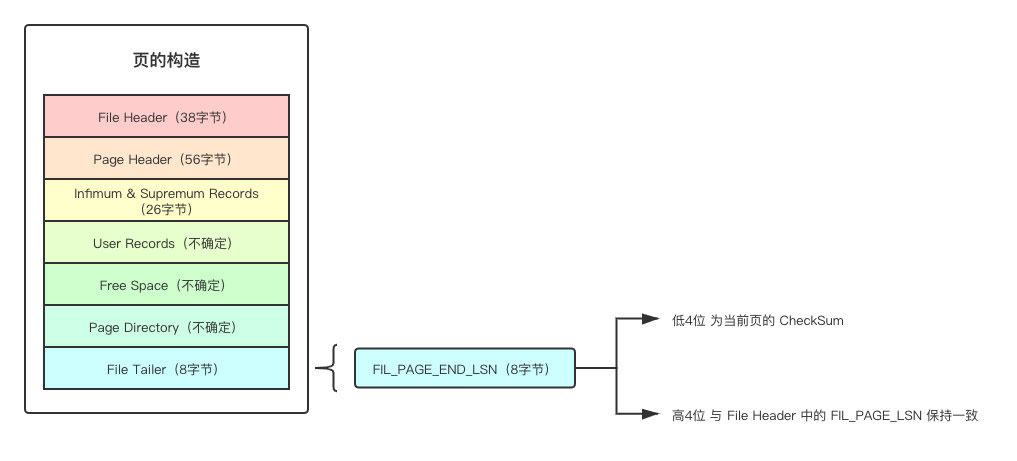
4.7、File Trailer
这块主要是为了防止页在刷入磁盘的过程中,由于极端的意外情况(网络问题、火灾、自然灾害)导致失败,而造成数据不一致的情况,也就是说形成了脏页。
里面有只有一个组成部分:
五、总结
到此,我认为关于页的所有东西就聊的差不多了,了解了底层的页原理,我个人认为是有助于我们更加友好、理智的使用 MySQL 的,使其能发挥出自己应该发挥的极致性能。
以上就是浅谈MySQL之浅入深出页原理的详细内容,更多关于MySQL 页原理的资料请关注自学编程网其它相关文章!

- 本文固定链接: https://zxbcw.cn/post/215789/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)