
一、背景
随着越来越多的机器学习应用场景的出现,而现有表现比较好的监督学习需要大量的标注数据,标注数据是一项枯燥无味且花费巨大的任务,所以迁移学习受到越来越多的关注。
传统机器学习(主要指监督学习)
- 基于同分布假设
- 需要大量标注数据
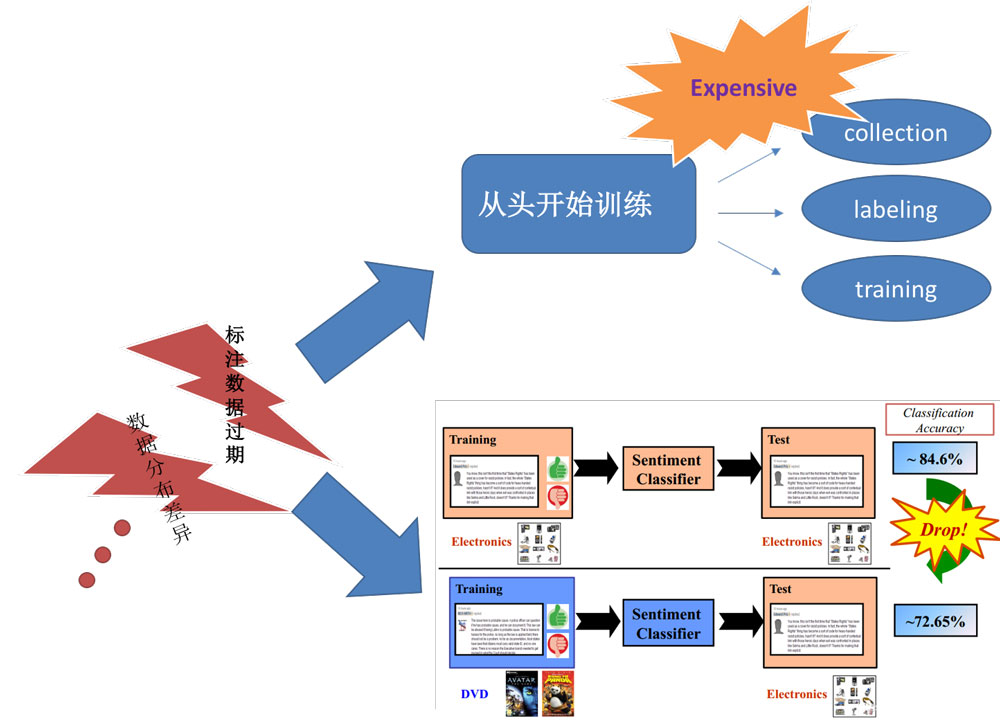
然而实际使用过程中不同数据集可能存在一些问题,比如
- 数据分布差异
- 标注数据过期:训练数据过期,也就是好不容易标定的数据要被丢弃,有些应用中数据是分布随着时间推移会有变化
如何充分利用之前标注好的数据(废物利用),同时又保证在新的任务上的模型精度?
基于这样的问题,所以就有了对于迁移学习的研究
二、定义及分类
Transfer Learning Definition:
Ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel domains/tasks.
2.1、目标
将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。
2.2、主要思想
从相关领域中迁移标注数据或者知识结构、完成或改进目标领域或任务的学习效果。
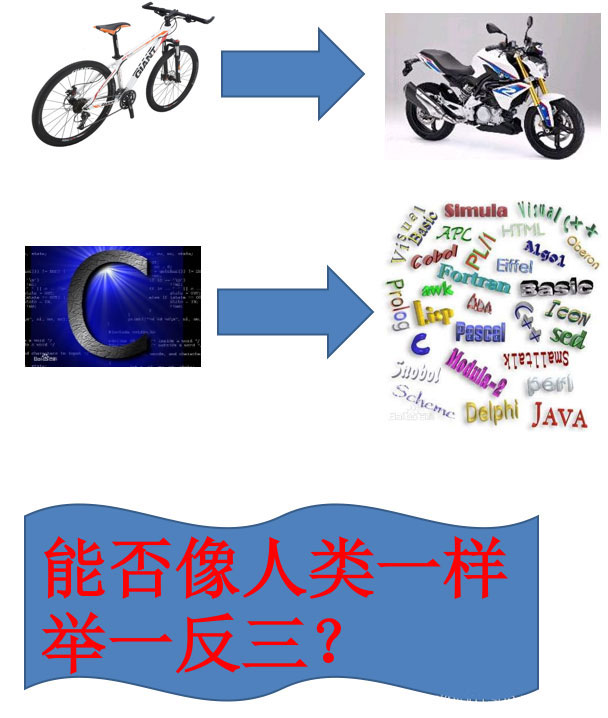
人在实际生活中有很多迁移学习,比如学会骑自行车,就比较容易学摩托车,学会了C语言,在学一些其它编程语言会简单很多。那么机器是否能够像人类一样举一反三呢?
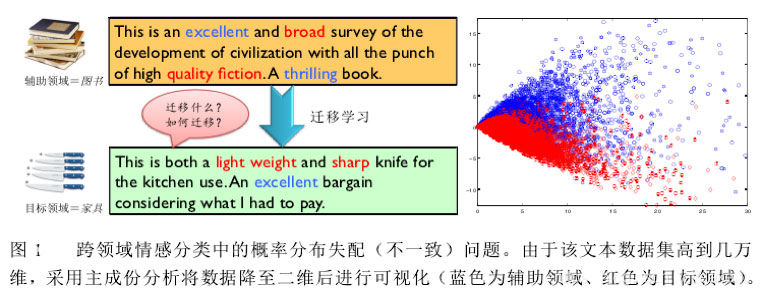
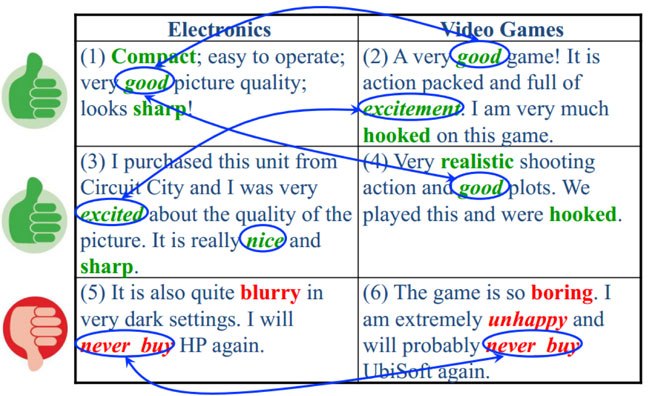
上图是一个商品评论情感分析的例子,图中包含两个不同的产品领域:books 图书领域和 furniture 家具领域;在图书领域,通常用“broad”、“quality fiction”等词汇来表达正面情感,而在家具领域中却由“sharp”、“light weight”等词汇来表达正面情感。可见此任务中,不同领域的不同情感词多数不发生重叠、存在领域独享词、且词汇在不同领域出现的频率显著不同,因此会导致领域间的概率分布失配问题。
2.3、迁移学习的形式定义及一种分类方式
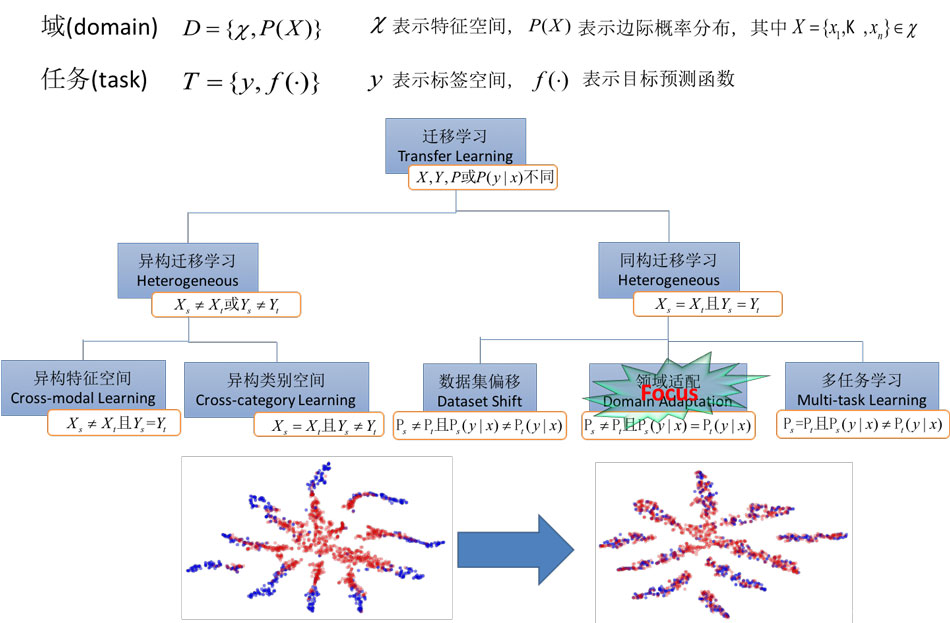
迁移学习里有两个非常重要的概念
- 域(Domain)
- 任务(Task)
域 可以理解为某个时刻的某个特定领域,比如书本评论和电视剧评论可以看作是两个不同的domain
任务 就是要做的事情,比如情感分析和实体识别就是两个不同的task
三、关键点
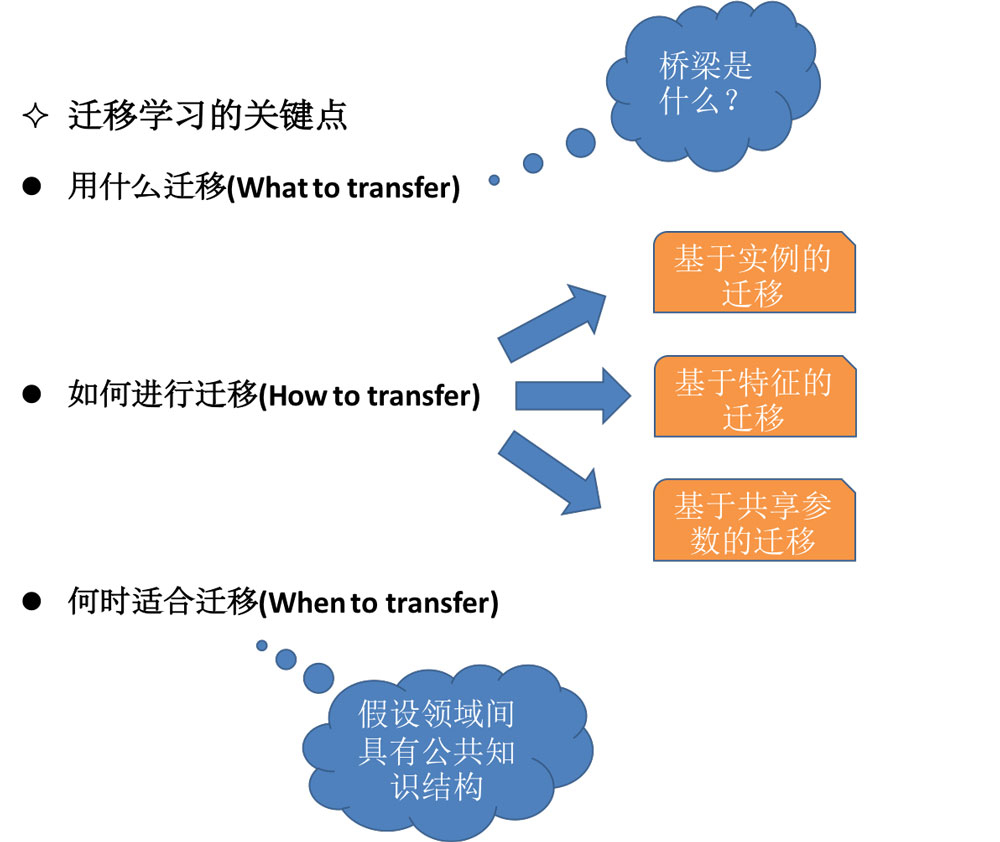
1.研究可以用哪些知识在不同的领域或者任务中进行迁移学习,即不同领域之间有哪些共有知识可以迁移。
2.研究在找到了迁移对象之后,针对具体问题所采用哪种迁移学习的特定算法,即如何设计出合适的算法来提取和迁移共有知识。
3.研究什么情况下适合迁移,迁移技巧是否适合具体应用,其中涉及到负迁移的问题。
当领域间的概率分布差异很大时,上述假设通常难以成立,这会导致严重的负迁移问题。
负迁移是旧知识对新知识学习的阻碍作用,比如学习了三轮车之后对骑自行车的影响,和学习汉语拼音对学英文字母的影响
研究如何利用正迁移,避免负迁移
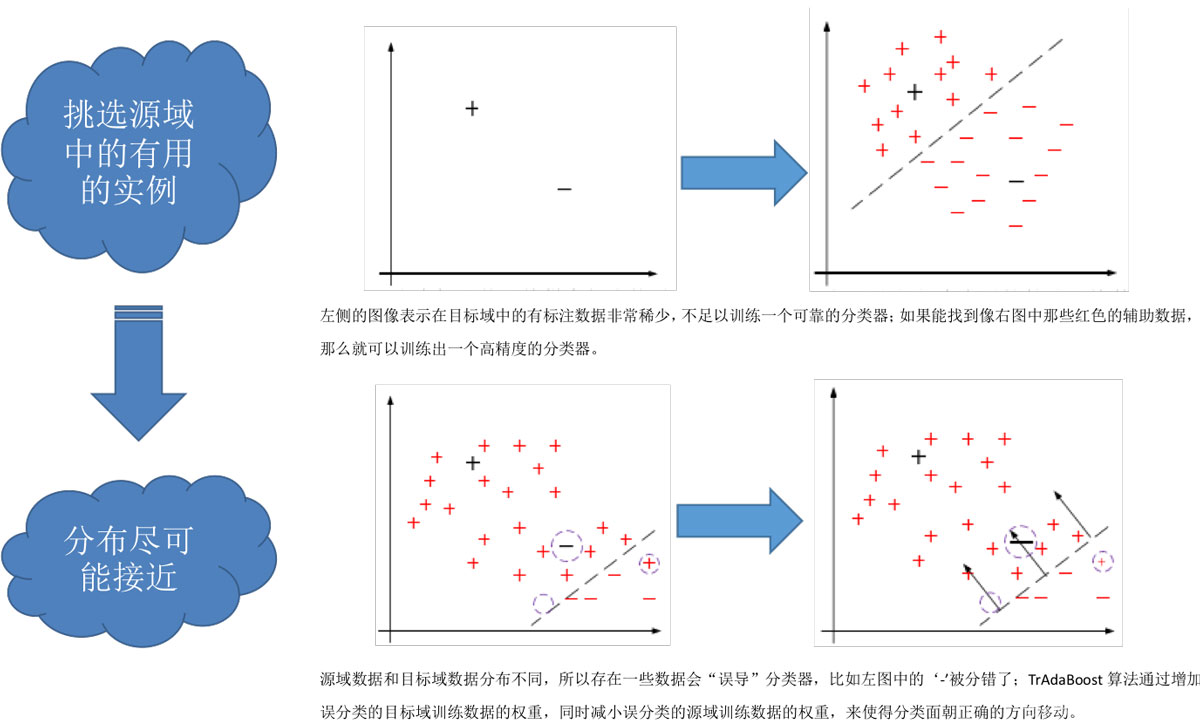
四、基于实例的迁移
基于实例的迁移学习研究的是,如何从源领域中挑选出,对目标领域的训练有用的实例,比如对源领域的有标记数据实例进行有效的权重分配,让源域实例分布接近目标域的实例分布,从而在目标领域中建立一个分类精度较高的、可靠地学习模型。
因为,迁移学习中源领域与目标领域的数据分布是不一致,所以源领域中所有有标记的数据实例不一定都对目标领域有用。戴文渊等人提出的TrAdaBoost算法就是典型的基于实例的迁移。
五、基于特征的迁移
5.1、特征选择
基于特征选择的迁移学习算法,关注的是如何找出源领域与目标领域之间共同的特征表示,然后利用这些特征进行知识迁移。
5.2、特征映射
基于特征映射的迁移学习算法,关注的是如何将源领域和目标领域的数据从原始特征空间映射到新的特征空间中去。
这样,在该空间中,源领域数据与的目标领域的数据分布相同,从而可以在新的空间中,更好地利用源领域已有的有标记数据样本进行分类训练,最终对目标领域的数据进行分类测试。
六、基于共享参数的迁移
基于共享参数的迁移研究的是如何找到源数据和目标数据的空间模型之间的共同参数或者先验分布,从而可以通过进一步处理,达到知识迁移的目的,假设前提是,学习任务中的的每个相关模型会共享一些相同的参数或者先验分布。
七、深度学习和迁移学习结合
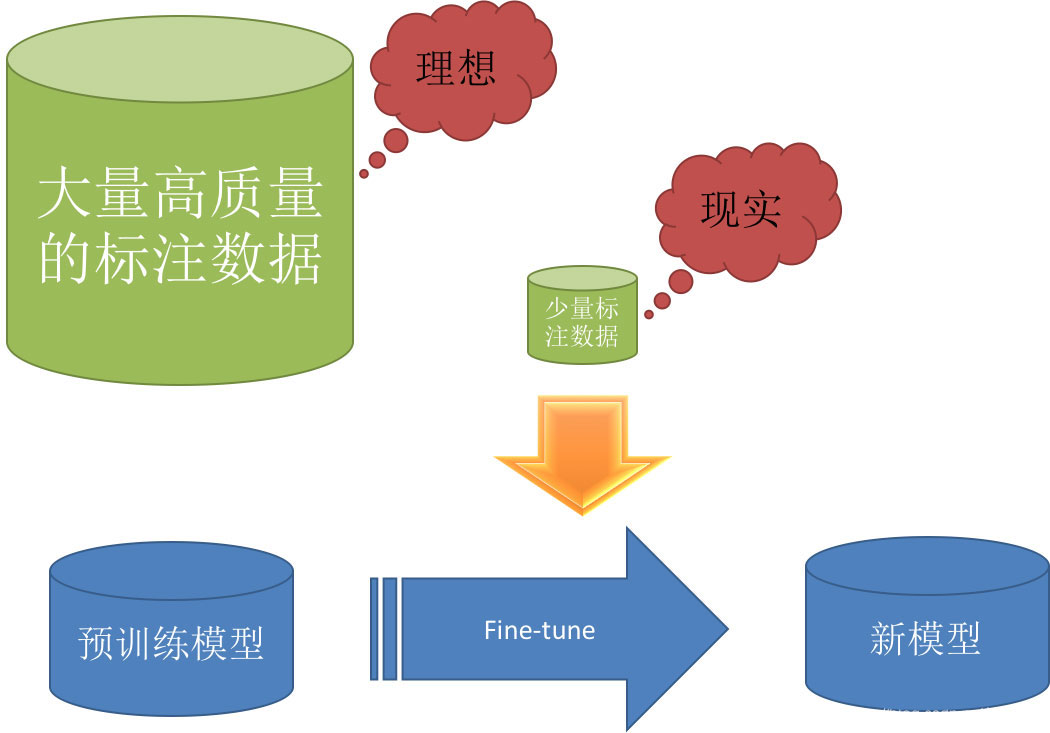
深度学习需要大量的高质量标注数据,Pre-training + fine-tuning 是现在深度学习中一个非常流行的trick,尤其是以图像领域为代表,很多时候会选择预训练的ImageNet对模型进行初始化。
下面将主要通过一些paper对深度学习中的迁移学习应用进行探讨
八、Pre-training+Fine-tuning
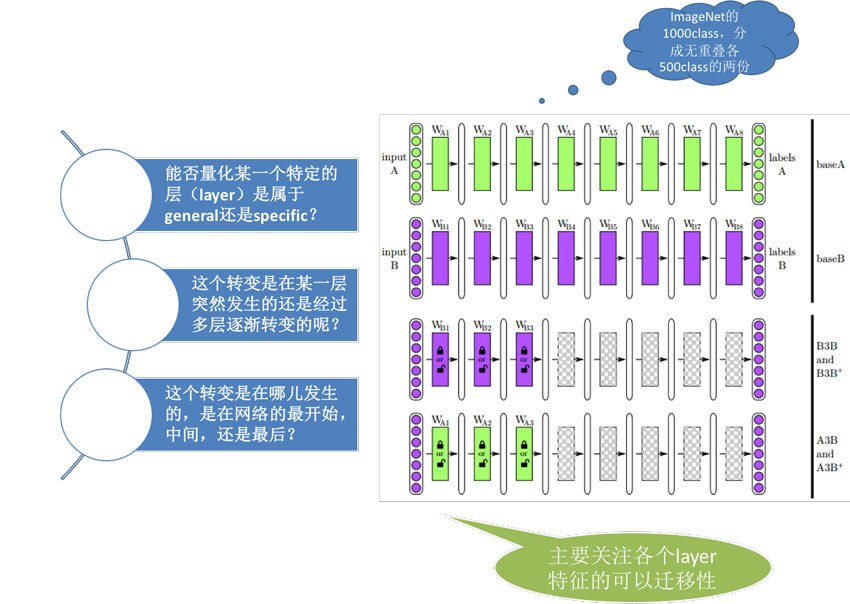
2014年Bengio等人在NIPS上发表论文 How transferable are features in deep neural networks,研究深度学习中各个layer特征的可迁移性(或者说通用性)
文章中进行了如下图所示的实验,有四种模型
- Domain A上的基本模型BaseA
- Domain B上的基本模型BaseB
- Domain B上前n层使用BaseB的参数初始化(后续有frozen和fine-tuning两种方式)
- Domain B上前n层使用BaseA的参数初始化(后续有frozen和fine-tuning两种方式)
将深度学习应用在图像处理领域中时,会观察到第一层(first-layer)中提取的features基本上是类似于Gabor滤波器(Gabor filters)和色彩斑点(color blobs)之类的。
通常情况下第一层与具体的图像数据集关系不是特别大,而网络的最后一层则是与选定的数据集及其任务目标紧密相关的;文章中将第一层feature称之为一般(general)特征,最后一层称之为特定(specific)特征
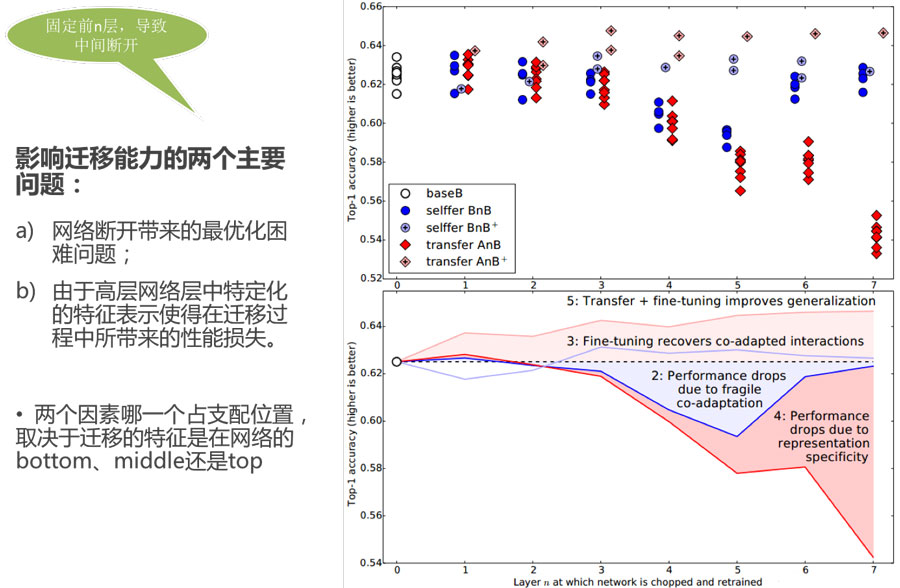
- 特征迁移使得模型的泛化性能有所提升,即使目标数据集非常大的时候也是如此。
- 随着参数被固定的层数n的增长,两个相似度小的任务之间的transferability gap的增长速度比两个相似度大的两个任务之间的transferability gap增长更快 两个数据集越不相似特征迁移的效果就越差
- 即使从不是特别相似的任务中进行迁移也比使用随机filters(或者说随机的参数)要好
- 使用迁移参数初始化网络能够提升泛化性能,即使目标task经过了大量的调整依然如此。
九、DANN (Domain-Adversarial Neural Network)
这篇paper将近两年流行的对抗网络思想引入到迁移学习中,从而提出了DANN
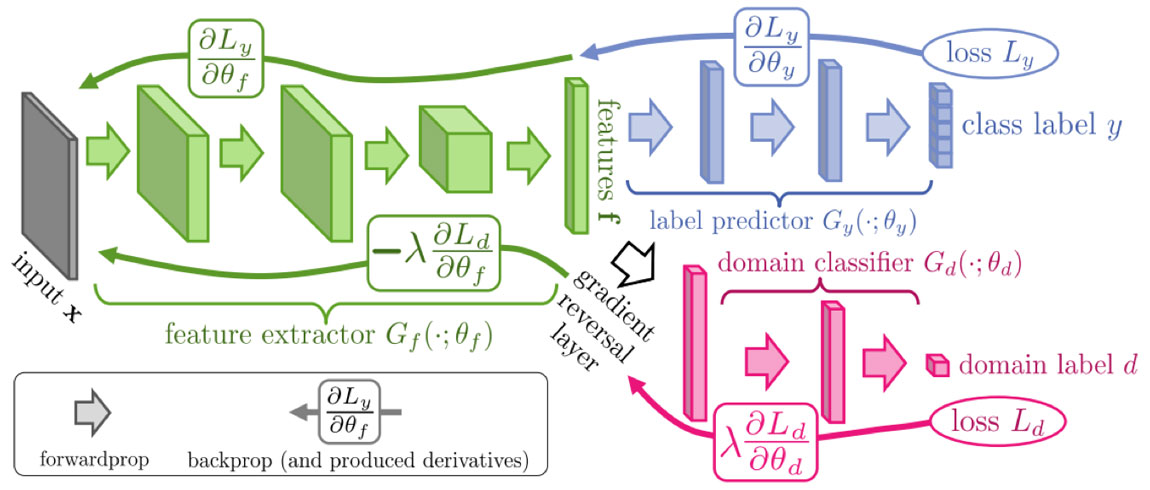
图中所展示的即为DANN的结构图,框架由feature extractor、label predictor和domain classifier三个部分组成,并且在feature extractor和domain classifier 之间有一个gradient reversal layer;其中domain classifier只在训练过程中发挥作用
- DANN将领域适配和特征学习整合到一个训练过程中,将领域适配嵌入在特征表示的学习过程中;所以模型最后的分类决策是基于既有区分力又对领域变换具有不变性的特征。
- 优化特征映射参数的目的是为了最小化label classifier的损失函数,最大化domain classifier的损失函数,前者是为了提取出具有区分能力的特征,后者是为了提取出具有领域不变性的特征,最终优化得到的特征兼具两种性质。
以上就是浅谈迁移学习的详细内容,更多关于迁移学习的资料请关注自学编程网其它相关文章!

- 本文固定链接: https://zxbcw.cn/post/215970/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)