
一、引言
我们知道java HashMap的扩容是有成本的,为了减少扩容的次数和成本,可以给HashMap设置初始容量大小,如下所示:
HashMap<string, integer=""> map0 = new HashMap<string, integer="">(100000);
但是在实际使用的过程中,发现性能不但没有提升,反而显著下降了!代码里对HashMap的操作也只有遍历了,看来是遍历出了问题,于是做了一番测试,得到如下结果:
HashMap的迭代器遍历性能与 initial capacity 有关,与size无关
二、迭代器测试
贴上测试代码:
public class MapForEachTest {
public static void main(String[] args) {
HashMap<string, integer=""> map0 = new HashMap<string, integer="">(100000);
initDataAndPrint(map0);
HashMap<string, integer=""> map1 = new HashMap<string, integer="">();
initDataAndPrint(map1);
}
private static void initDataAndPrint(HashMap map) {
initData(map);
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
forEach(map);
}
long end = System.currentTimeMillis();
System.out.println("");
System.out.println("HashMap Size: " + map.size() + " 耗时: " + (end - start) + " ms");
}
private static void forEach(HashMap map) {
for (Iterator<map.entry<string, integer="">> it = map.entrySet().iterator(); it.hasNext();){
Map.Entry<string, integer=""> item = it.next();
System.out.print(item.getKey());
// do something
}
}
private static void initData(HashMap map) {
map.put("a", 0);
map.put("b", 1);
map.put("c", 2);
map.put("d", 3);
map.put("e", 4);
map.put("f", 5);
}
}
这是运行结果:
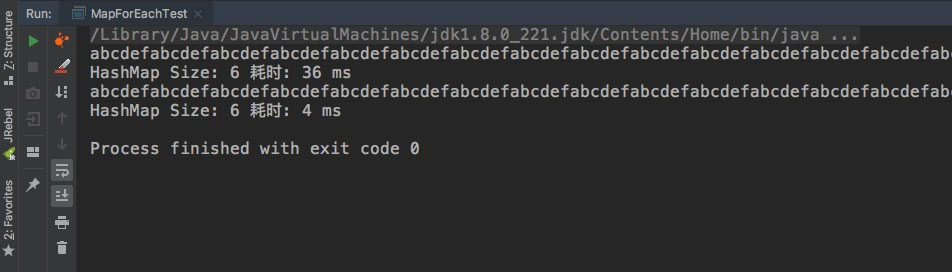
我们将第一个Map初始化10w大小,第二个map不指定大小(实际16),两个存储相同的数据,但是用迭代器遍历100次的时候发现性能迥异,一个36ms一个4ms,实际上性能差距更大,这里的4ms是600次System.out.print的耗时,这里将print注掉再试下
for (Iterator<map.entry<string, integer="">> it = map.entrySet().iterator(); it.hasNext();){
Map.Entry<string, integer=""> item = it.next();
// System.out.print(item.getKey());
// do something
}
输出结果如下:
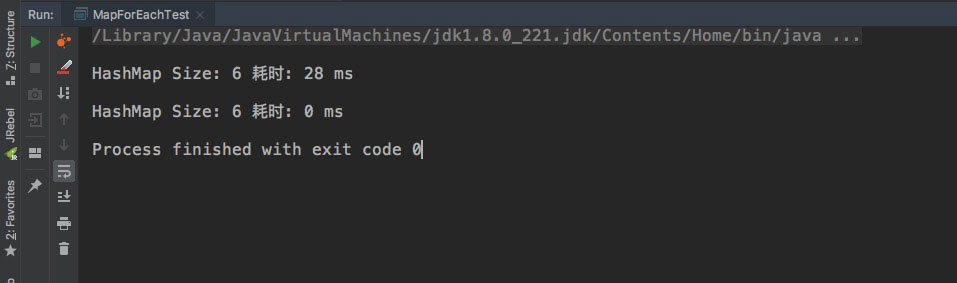
可以发现第二个map耗时几乎为0,第一个达到了28ms,遍历期间没有进行任何操作,既然石锤了和 initial capacity 有关,下一步我们去看看为什么会这样,找找Map迭代器的源码看看。
三、迭代器源码探究
我们来看看Map.entrySet().iterator()的源码;
public final Iterator<map.entry<k,v>> iterator() {
return new EntryIterator();
}
其中EntryIterator是HashMap的内部抽象类,源码并不多,我全部贴上来并附上中文注释
abstract class HashIterator {
// 下一个Node
Node<k,v> next; // next entry to return
// 当前Node
Node<k,v> current; // current entry
// 预期的Map大小,也就是说每个HashMap可以有多个迭代器(每次调用 iterator() 会new 一个迭代器出来),但是只能有一个迭代器对他remove,否则会直接报错(快速失败)
int expectedModCount; // for fast-fail
// 当前节点所在的数组下标,HashMap内部是使用数组来存储数据的,不了解的先去看看HashMap的源码吧
int index; // current slot
HashIterator() {
// 初始化 expectedModCount
expectedModCount = modCount;
// 浅拷贝一份Map的数据
Node<k,v>[] t = table;
current = next = null;
index = 0;
// 如果 Map 中数据不为空,遍历数组找到第一个实际存储的素,赋值给next
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<k,v> nextNode() {
// 用来浅拷贝table,和别名的作用差不多,没啥用
Node<k,v>[] t;
// 定义一个e指存储next,并在找到下一值时返它自己
Node<k,v> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
// 使current指向e,也就是next,这次要找的值,并且让next = current.next,一般为null
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
/**
* 删除元素,这里不讲了,调的是HashMap的removeNode,没啥特别的
**/
public final void remove() {
Node<k,v> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
// 用来保证快速失败的
expectedModCount = modCount;
}
}
上面的代码一看就明白了,迭代器每次寻找下一个元素都会去遍历数组,如果 initial capacity 特别大的话,也就是说 threshold 也大,table.length就大,所以遍历比较耗性能。
table数组的大小设置是在resize()方法里:
Node<k,v>[] newTab = (Node<k,v>[])new Node[newCap]; table = newTab;
四、其他遍历方法
注意代码里我们用的是Map.entrySet().iterator(),实际上和keys().iterator(), values().iterator() 一样,源码如下:
final class KeyIterator extends HashIterator
implements Iterator<k> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashIterator
implements Iterator<v> {
public final V next() { return nextNode().value; }
}
final class EntryIterator extends HashIterator
implements Iterator<map.entry<k,v>> {
public final Map.Entry<k,v> next() { return nextNode(); }
}
这两个就不分析了,性能一样。
实际使用中对集合的遍历还有几种方法:
- 普通for循环+下标
- 增强型for循环
- Map.forEach
- Stream.forEach
普通for循环+下标的方法不适用于Map,这里不讨论了。
4.1、增强型for循环
增强行for循环实际上是通过迭代器来实现的,我们来看两者的联系
源码:
private static void forEach(HashMap map) {
for (Iterator<map.entry<string, integer="">> it = map.entrySet().iterator(); it.hasNext();){
Map.Entry<string, integer=""> item = it.next();
System.out.print(item.getKey());
// do something
}
}
private static void forEach0(HashMap<string, integer=""> map) {
for (Map.Entry entry : map.entrySet()) {
System.out.print(entry.getKey());
}
}
编译后的字节码:
// access flags 0xA
private static forEach(Ljava/util/HashMap;)V
L0
LINENUMBER 41 L0
ALOAD 0
INVOKEVIRTUAL java/util/HashMap.entrySet ()Ljava/util/Set;
INVOKEINTERFACE java/util/Set.iterator ()Ljava/util/Iterator; (itf)
ASTORE 1
L1
FRAME APPEND [java/util/Iterator]
ALOAD 1
INVOKEINTERFACE java/util/Iterator.hasNext ()Z (itf)
IFEQ L2
L3
LINENUMBER 42 L3
ALOAD 1
INVOKEINTERFACE java/util/Iterator.next ()Ljava/lang/Object; (itf)
CHECKCAST java/util/Map$Entry
ASTORE 2
L4
LINENUMBER 43 L4
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
ALOAD 2
INVOKEINTERFACE java/util/Map$Entry.getKey ()Ljava/lang/Object; (itf)
CHECKCAST java/lang/String
INVOKEVIRTUAL java/io/PrintStream.print (Ljava/lang/String;)V
L5
LINENUMBER 45 L5
GOTO L1
L2
LINENUMBER 46 L2
FRAME CHOP 1
RETURN
L6
LOCALVARIABLE item Ljava/util/Map$Entry; L4 L5 2
// signature Ljava/util/Map$Entry<ljava lang="" string;ljava="" integer;="">;
// declaration: item extends java.util.Map$Entry<java.lang.string, java.lang.integer="">
LOCALVARIABLE it Ljava/util/Iterator; L1 L2 1
// signature Ljava/util/Iterator<ljava util="" map$entry<ljava="" lang="" string;ljava="" integer;="">;>;
// declaration: it extends java.util.Iterator<java.util.map$entry<java.lang.string, java.lang.integer="">>
LOCALVARIABLE map Ljava/util/HashMap; L0 L6 0
MAXSTACK = 2
MAXLOCALS = 3
// access flags 0xA
// signature (Ljava/util/HashMap<ljava lang="" string;ljava="" integer;="">;)V
// declaration: void forEach0(java.util.HashMap<java.lang.string, java.lang.integer="">)
private static forEach0(Ljava/util/HashMap;)V
L0
LINENUMBER 50 L0
ALOAD 0
INVOKEVIRTUAL java/util/HashMap.entrySet ()Ljava/util/Set;
INVOKEINTERFACE java/util/Set.iterator ()Ljava/util/Iterator; (itf)
ASTORE 1
L1
FRAME APPEND [java/util/Iterator]
ALOAD 1
INVOKEINTERFACE java/util/Iterator.hasNext ()Z (itf)
IFEQ L2
ALOAD 1
INVOKEINTERFACE java/util/Iterator.next ()Ljava/lang/Object; (itf)
CHECKCAST java/util/Map$Entry
ASTORE 2
L3
LINENUMBER 51 L3
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
ALOAD 2
INVOKEINTERFACE java/util/Map$Entry.getKey ()Ljava/lang/Object; (itf)
INVOKEVIRTUAL java/io/PrintStream.print (Ljava/lang/Object;)V
L4
LINENUMBER 52 L4
GOTO L1
L2
LINENUMBER 53 L2
FRAME CHOP 1
RETURN
L5
LOCALVARIABLE entry Ljava/util/Map$Entry; L3 L4 2
LOCALVARIABLE map Ljava/util/HashMap; L0 L5 0
// signature Ljava/util/HashMap<ljava lang="" string;ljava="" integer;="">;
// declaration: map extends java.util.HashMap<java.lang.string, java.lang.integer="">
MAXSTACK = 2
MAXLOCALS = 3
都不用耐心观察,两个方法的字节码除了局部变量不一样其他都几乎一样,由此可以得出增强型for循环性能与迭代器一样,实际运行结果也一样,我不展示了,感兴趣的自己去copy文章开头和结尾的代码试下。
4.2、Map.forEach
先说一下为什么不把各种方法一起运行同时打印性能,这是因为CPU缓存的原因和JVM的一些优化会干扰到性能的判断,附录全部测试结果有说明
直接来看源码吧
@Override
public void forEach(BiConsumer<!--? super K, ? super V--> action) {
Node<k,v>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<k,v> e = tab[i]; e != null; e = e.next)
action.accept(e.key, e.value);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
很简短的源码,就不打注释了,从源码我们不难获取到以下信息:
- 该方法也是快速失败的,遍历期间不能删除元素
- 需要遍历整个数组
- BiConsumer加了@FunctionalInterface注解,用了 lambda
第三点和性能无关,这里只是提下
通过以上信息我们能确定这个性能与table数组的大小有关。
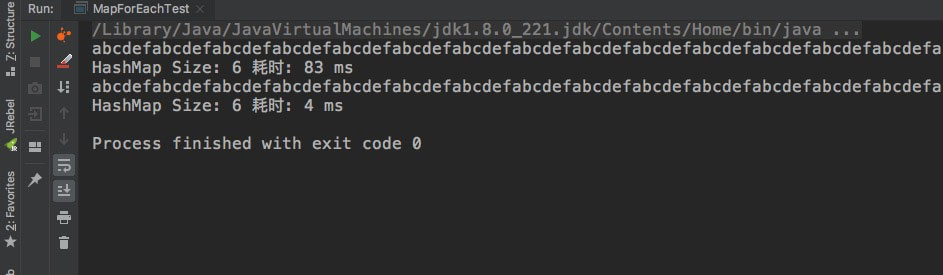
但是在实际测试的时候却发现性能比迭代器差了不少:
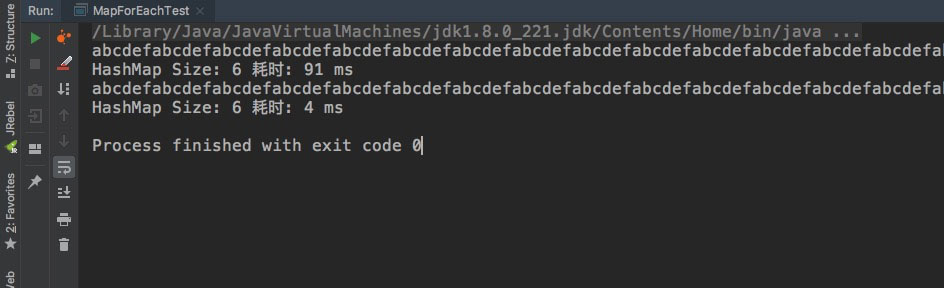
4.3、Stream.forEach
Stream与Map.forEach的共同点是都使用了lambda表达式。但两者的源码没有任何复用的地方。
不知道你有没有看累,先上测试结果吧:
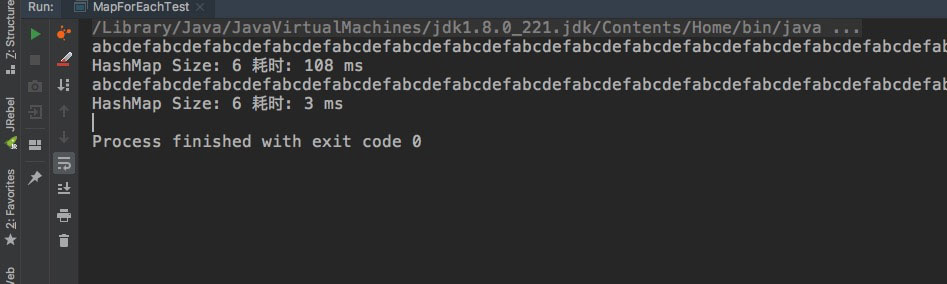
耗时比Map.foreach还要高点。
下面讲讲Straam.foreach顺序流的源码,这个也不复杂,不过累的话先去看看总结吧。
Stream.foreach的执行者是分流器,HashMap的分流器源码就在HashMap类中,是一个静态内部类,类名叫 EntrySpliterator
下面是顺序流执行的方法
public void forEachRemaining(Consumer<!--? super Map.Entry<K,V-->> action) {
int i, hi, mc;
if (action == null)
throw new NullPointerException();
HashMap<k,v> m = map;
Node<k,v>[] tab = m.table;
if ((hi = fence) < 0) {
mc = expectedModCount = m.modCount;
hi = fence = (tab == null) ? 0 : tab.length;
}
else
mc = expectedModCount;
if (tab != null && tab.length >= hi &&
(i = index) >= 0 && (i < (index = hi) || current != null)) {
Node<k,v> p = current;
current = null;
do {
if (p == null)
p = tab[i++];
else {
action.accept(p);
p = p.next;
}
} while (p != null || i < hi);
if (m.modCount != mc)
throw new ConcurrentModificationException();
}
}
从以上源码中我们也可以轻易得出遍历需要顺序扫描所有数组
五、总结
至此,Map的四种遍历方法都测试完了,我们可以简单得出两个结论
- Map的遍历性能与内部table数组大小有关,也就是说与常用参数 initial capacity 有关,不管哪种遍历方式都是的
- 性能(由高到低):迭代器 == 增强型For循环 > Map.forEach > Stream.foreach
这里就不说什么多少倍多少倍的性能差距了,抛开数据集大小都是扯淡,当我们不指定initial capacity的时候,四种遍历方法耗时都是3ms,这3ms还是输入输出流的耗时,实际遍历耗时都是0,所以数据集不大的时候用哪种都无所谓,就像不加输入输出流耗时不到1ms一样,很多时候性能消耗是在遍历中的业务操作,这篇文章不是为了让你去优化代码把foreach改成迭代器的,在大多数场景下并不需要关注迭代本身的性能,Stream与Lambda带来的可读性提升更加重要。
所以此文的目的就当是知识拓展吧,除了以上说到的遍历性能问题,你还应该从中能获取到的知识点有:
- HashMap的数组是存储在table数组里的
- table数组是resize方法初始化的,new Map不会初始化数组
- Map遍历是table数组从下标0递增排序的,所以他是无序的
- keySet().iterator,values.iterator, entrySet.iterator 来说没有本质区别,用的都是同一个迭代器
- 各种遍历方法里,只有迭代器可以remove,虽然增强型for循环底层也是迭代器,但这个语法糖隐藏了 remove 方法
- 每次调用迭代器方法都会new 一个迭代器,但是只有一个可以修改
- Map.forEach与Stream.forEach看上去一样,实际实现是不一样的
附:四种遍历源码
private static void forEach(HashMap map) {
for (Iterator<map.entry<string, integer="">> it = map.entrySet().iterator(); it.hasNext();){
Map.Entry<string, integer=""> item = it.next();
// System.out.print(item.getKey());
// do something
}
}
private static void forEach0(HashMap<string, integer=""> map) {
for (Map.Entry entry : map.entrySet()) {
System.out.print(entry.getKey());
}
}
private static void forEach1(HashMap<string, integer=""> map) {
map.forEach((key, value) -> {
System.out.print(key);
});
}
private static void forEach2(HashMap<string, integer=""> map) {
map.entrySet().stream().forEach(e -> {
System.out.print(e.getKey());
});
}
附:完整测试类与测试结果+一个奇怪的问题
public class MapForEachTest {
public static void main(String[] args) {
HashMap<string, integer=""> map0 = new HashMap<string, integer="">(100000);
HashMap<string, integer=""> map1 = new HashMap<string, integer="">();
initData(map0);
initData(map1);
testIterator(map0);
testIterator(map1);
testFor(map0);
testFor(map1);
testMapForeach(map0);
testMapForeach(map1);
testMapStreamForeach(map0);
testMapStreamForeach(map1);
}
private static void testIterator(HashMap map) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
forEach(map);
}
long end = System.currentTimeMillis();
System.out.println("");
System.out.println("HashMap Size: " + map.size() + " 迭代器 耗时: " + (end - start) + " ms");
}
private static void testFor(HashMap map) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
forEach0(map);
}
long end = System.currentTimeMillis();
System.out.println("");
System.out.println("HashMap Size: " + map.size() + " 增强型For 耗时: " + (end - start) + " ms");
}
private static void testMapForeach(HashMap map) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
forEach1(map);
}
long end = System.currentTimeMillis();
System.out.println("");
System.out.println("HashMap Size: " + map.size() + " MapForeach 耗时: " + (end - start) + " ms");
}
private static void testMapStreamForeach(HashMap map) {
long start = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
forEach2(map);
}
long end = System.currentTimeMillis();
System.out.println("");
System.out.println("HashMap Size: " + map.size() + " MapStreamForeach 耗时: " + (end - start) + " ms");
}
private static void forEach(HashMap map) {
for (Iterator<map.entry<string, integer="">> it = map.entrySet().iterator(); it.hasNext();){
Map.Entry<string, integer=""> item = it.next();
System.out.print(item.getKey());
// do something
}
}
private static void forEach0(HashMap<string, integer=""> map) {
for (Map.Entry entry : map.entrySet()) {
System.out.print(entry.getKey());
}
}
private static void forEach1(HashMap<string, integer=""> map) {
map.forEach((key, value) -> {
System.out.print(key);
});
}
private static void forEach2(HashMap<string, integer=""> map) {
map.entrySet().stream().forEach(e -> {
System.out.print(e.getKey());
});
}
private static void initData(HashMap map) {
map.put("a", 0);
map.put("b", 1);
map.put("c", 2);
map.put("d", 3);
map.put("e", 4);
map.put("f", 5);
}
}
测试结果:
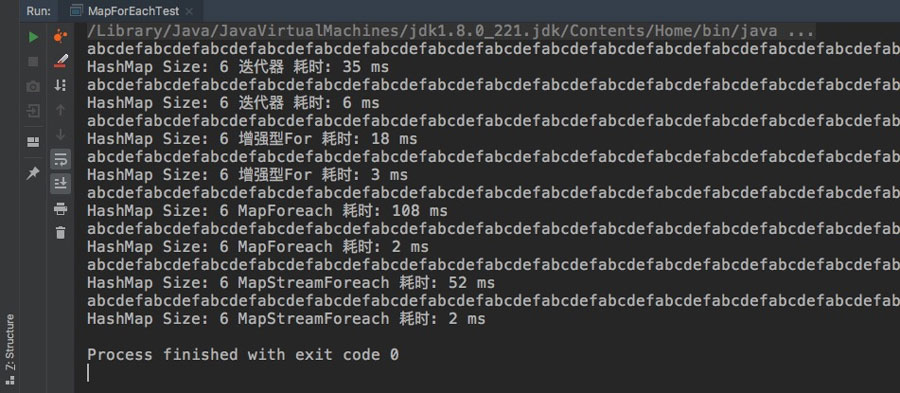
如果你认真看了上面的文章的话,会发现测试结果有个不对劲的地方:
MapStreamForeach的耗时似乎变少了
我可以告诉你这不是数据的原因,从我的测试测试结果来看,直接原因是因为先执行了 Map.foreach,如果你把 MapForeach 和 MapStreamForeach 调换一下执行顺序,你会发现后执行的那个耗时更少。
以上就是分析Java中Map的遍历性能问题的详细内容,更多关于Java Map 遍历性能的资料请关注自学编程网其它相关文章!

- 本文固定链接: https://www.zxbcw.cn/post/216035/
- 转载请注明:必须在正文中标注并保留原文链接
- QQ群: PHP高手阵营官方总群(344148542)
- QQ群: Yii2.0开发(304864863)